Encoding Animation with SVT-AV1: A Deep Dive

This blog post is based on a series of visual quality benchmarks with SSIMULACRA2 and speed benchmarks of SVT-AV1 1.8.0 on a corpus of animated clips.
The resources available will range from graphs to image comparisons (WIP). The former has the advantage of being easily understandable, showcasing pure efficiency comparisons between encoder parameters using metrics as the reference, while the latter are image samples from the encoded files during the tests that enable you to check quality for yourself and add another layer of subjective interpretation to these comparisons.
The testing methodology involves using relatively short video samples from a wide range of modern anime genre, which have been either losslessly encoded with x264 --qp 0 for ease of use or losslessly cut from their source. These lossless files are then pipped into SvtAv1EncApp directly, meaning we are measuring the performance of a single encoder instance and not leveraging chunked encoding like any actual final AV1 encoding pipeline should. Once an encode is done, SSIMULACRA2 scores are calculated using the Zig implementation and lots of useful data are aggregated to make the graphs for this benchmark, including encoding time, encode size (bitrate), and SSIMULACRA2 scores. Bits per pixel scores (BPP) are calculated so that the Metric / BPP graphs may represent the closest we have to real efficiency.
The clips used in this test were acquired legally. The Codec Wiki and its contributors do not endorse media piracy.
SvtAv1EncApp was compiled directly from the v1.8.0 source code using the provided Build/linux/build.sh script, Clang 16.0.6, and Profile-Guided Optimization (PGO). The testing machine is comprised of an i7 8750H running at 35W with 16GB of 2666MHz DDR4 RAM in Arch Linux with kernel 6.6.6 and the performance governor enabled. All encodes have been made in the same session without rebooting.
This testing was conducted within the AV1 Weeb Edition Discord server, which is focused on encoding animated content in AV1.
Samples
The samples are as follows:
- 11s
Blame!clip which sports 3DCG action with lots of grain, effects and high-contrast elements. Most complex source of this set. - 13s
Blue Lockclip which sports rapid camera movements and rotations + high-contrast elements. - 15s
Fate/Grand Order: Babyloniarelatively slow-paced clip with lots of effects still. Easiest source of this set but easy sources still give interesting data. - 22s
Jigokuraku (Hell's Paradise)flashback clip with huge static grain in a very dark scenery and some action. - 14s
Kaguya-samaopening sequence with lots of effects and fast change of scenery. The resolution of every clip is 1080p, except for the first one which is 1920x804.
All clips have been encoded in a wide quality range, from
--crf 8to--crf 43.
Without further ado, let's start with the first comparisons!
Presets comparisons (-1 -> 13)
In the following graphs, you may find comparisons between all SVT-AV1 presets, ranging from the slowest --preset -1 to the fastest --preset 13.
Please remember that these two extreme presets are meant for development purposes and as such should not be used in normal encoding conditions. You will soon understand why.
--preset X is the only parameter used here, in conjunction with the CRF values. That means everything else is default. The defaults worth mentioning are:
-
--tune 1: tune PSNR -
--aq-mode 2: variance deltaq -
--enable-qm 0: quantisation matrices disabled -
--irefresh-type 2: closed GOP -
--enable-tf 1: temporal filtering enabled And more, like CDEF and restoration enabled, overlays and film-grain disabled... -
First of all, here are the efficiency graphs:
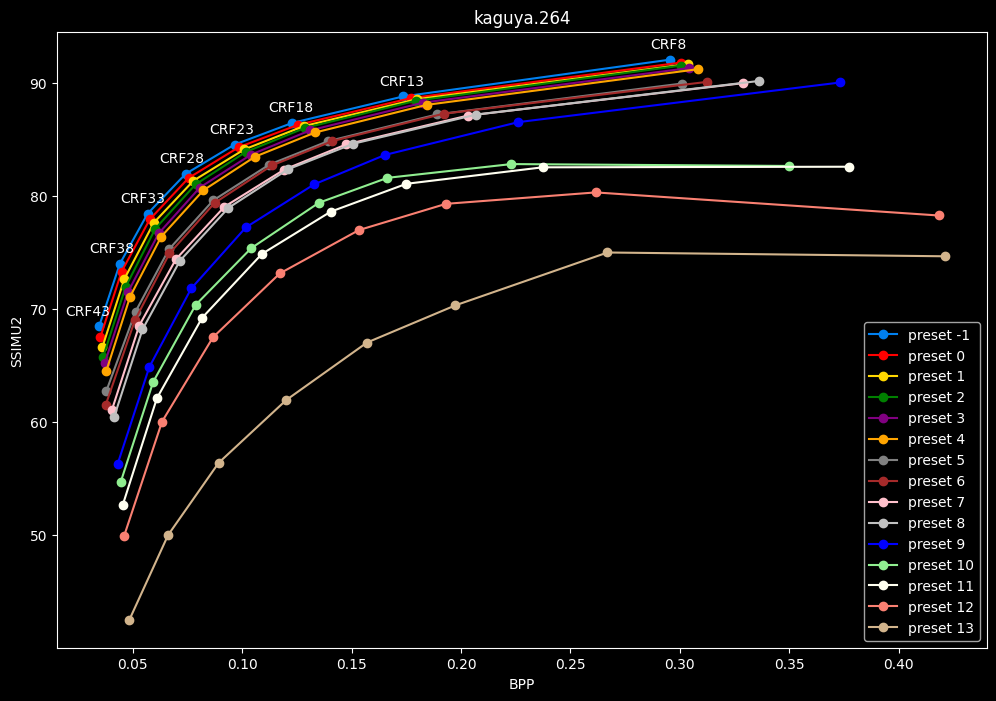
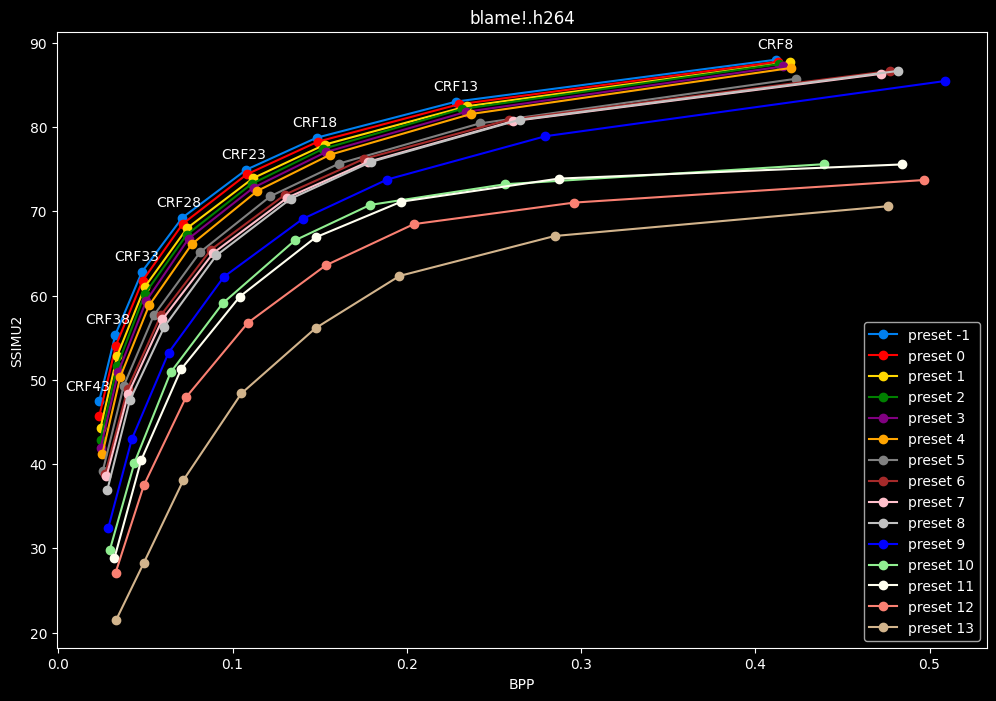
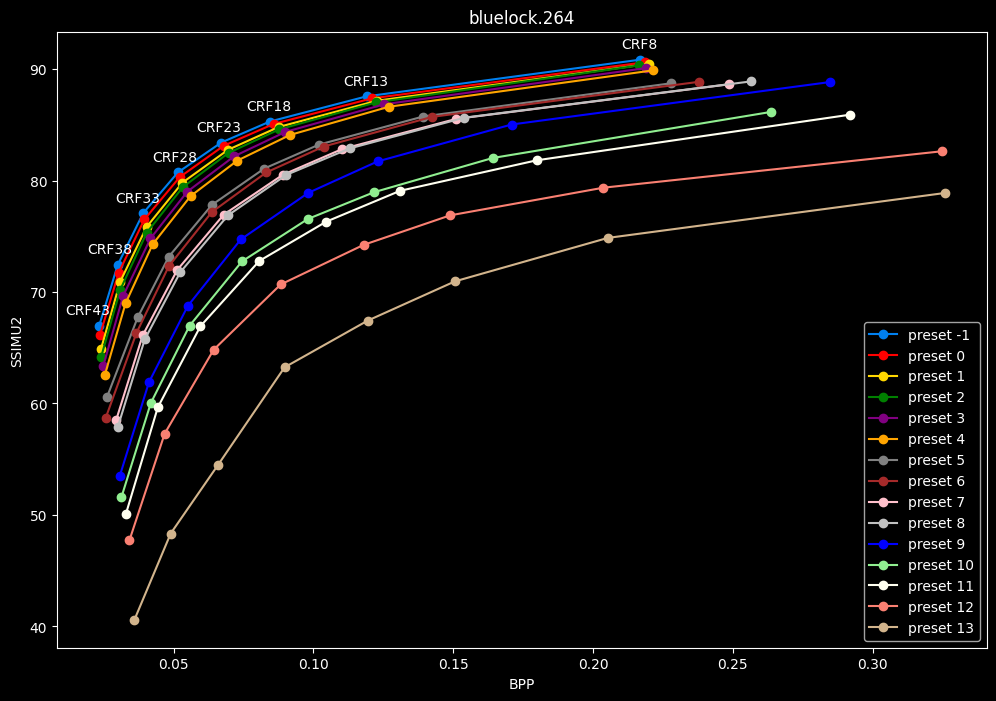
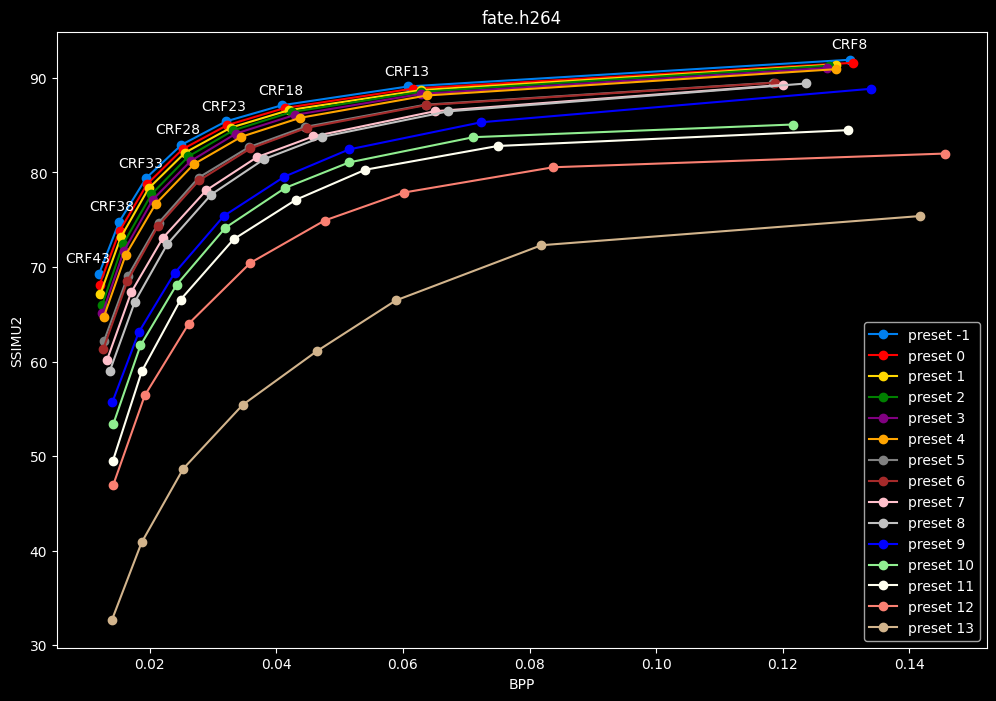
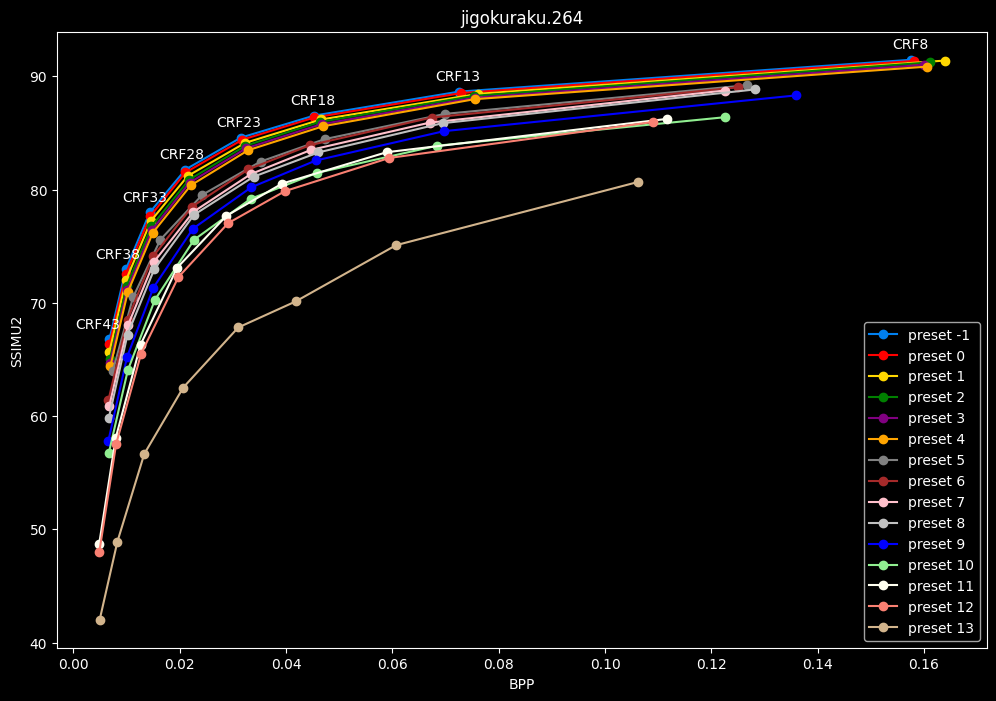
This could be too much information.
- Now the same graphs but focusing on the "high quality" range (CRF8 -> 23):
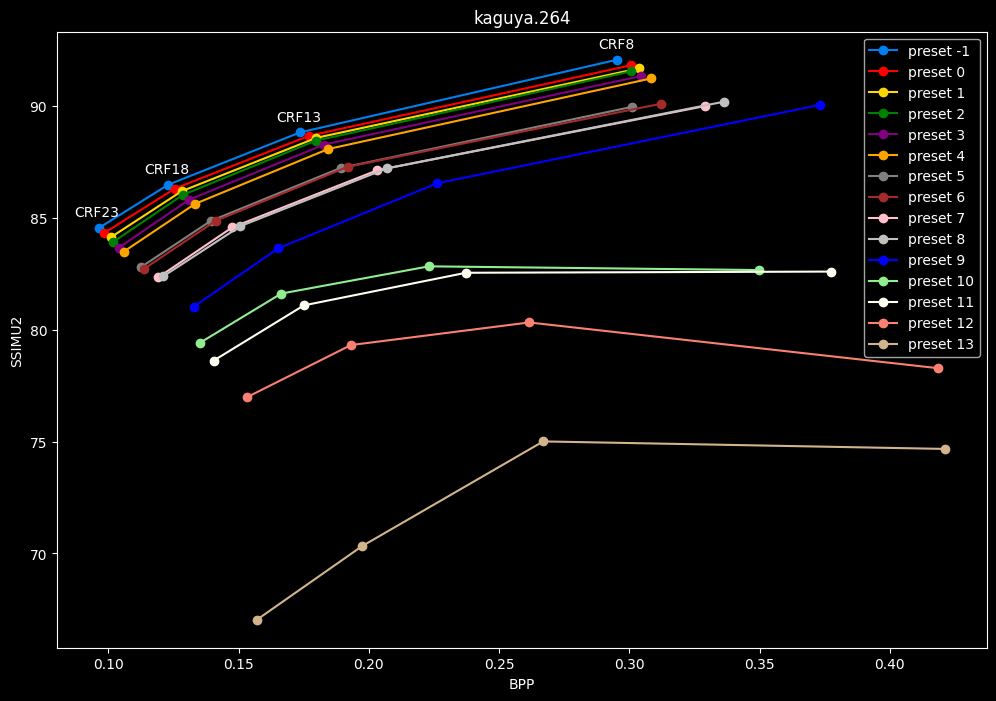
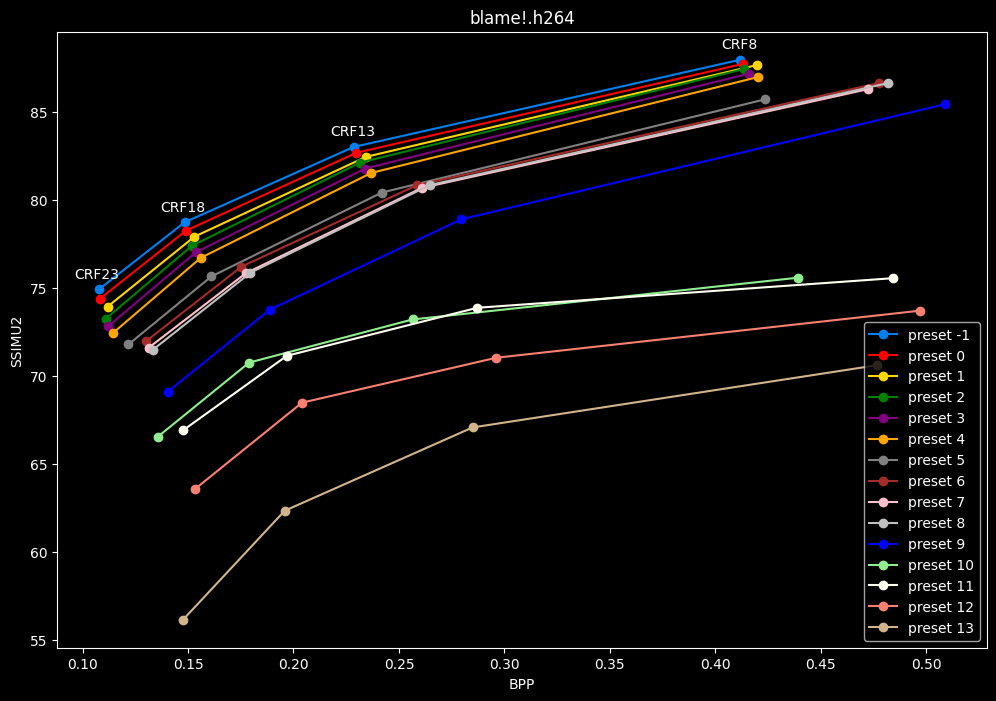
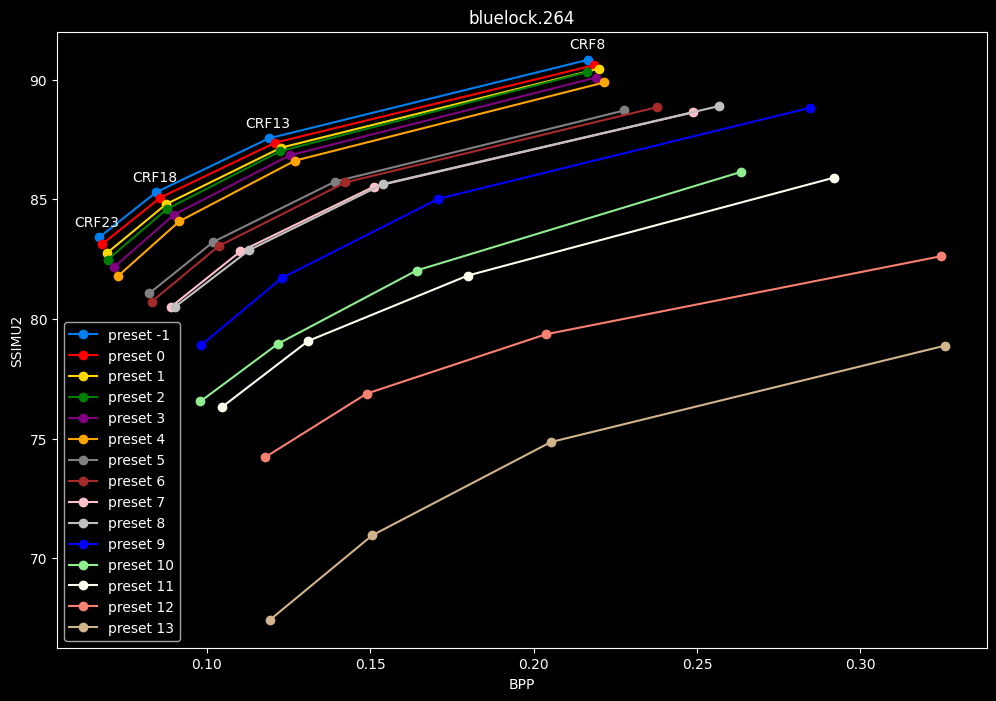
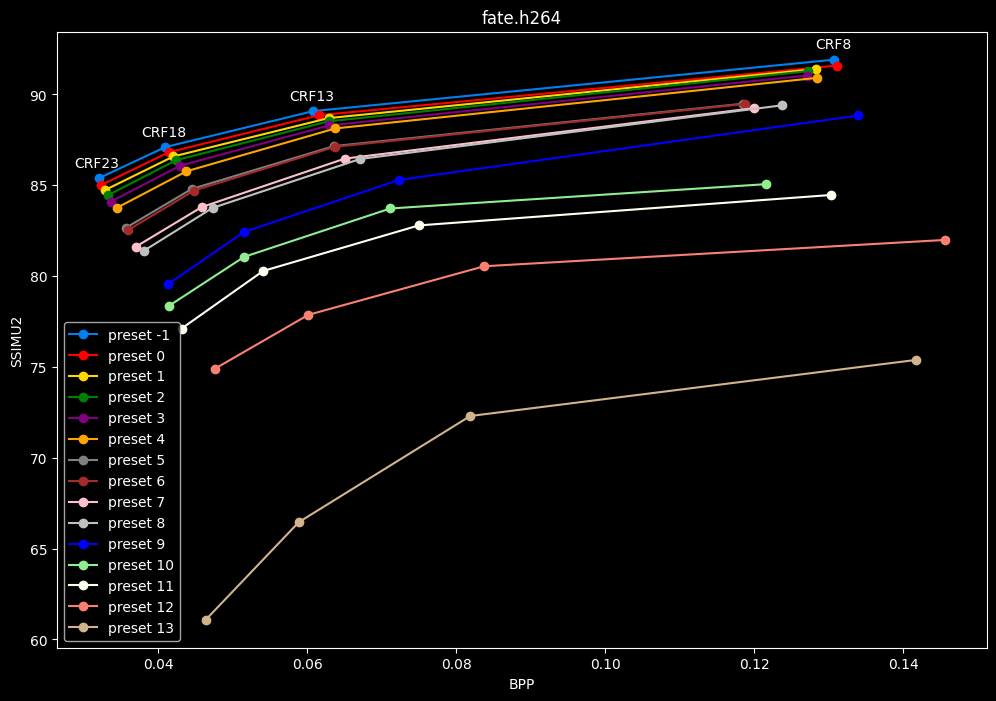
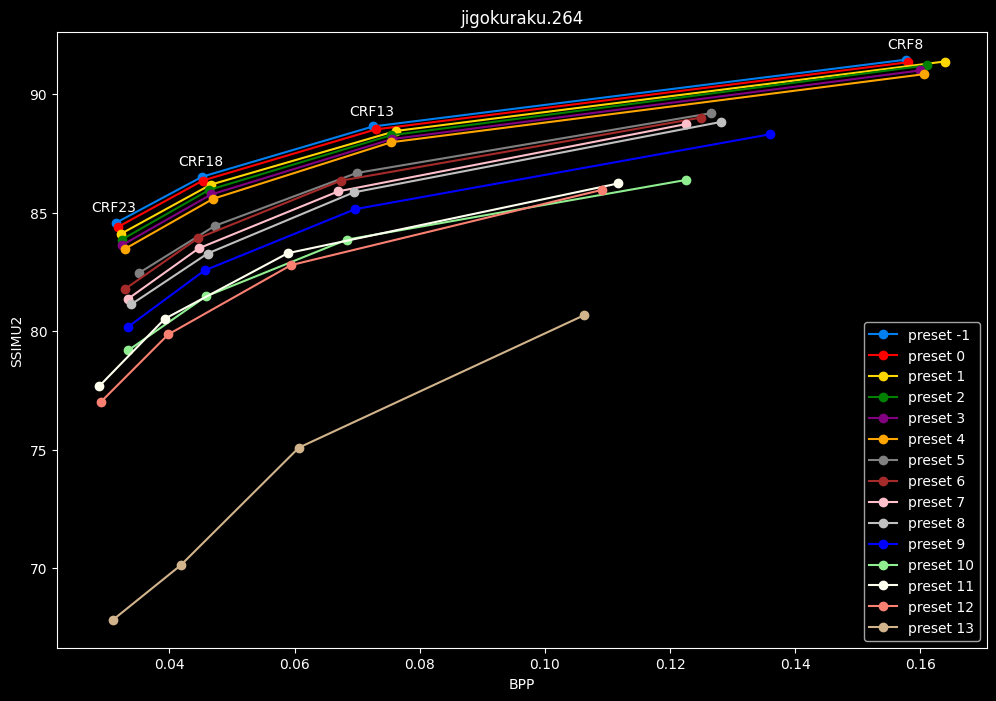
- Same again but without presets 9 to 13 for better clarity:
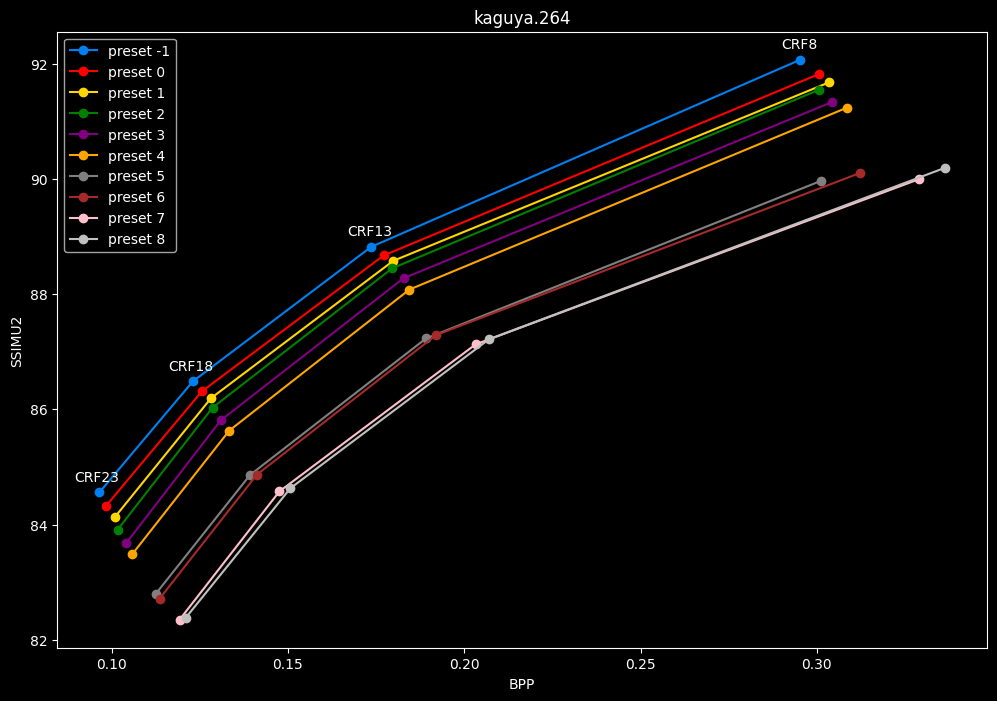
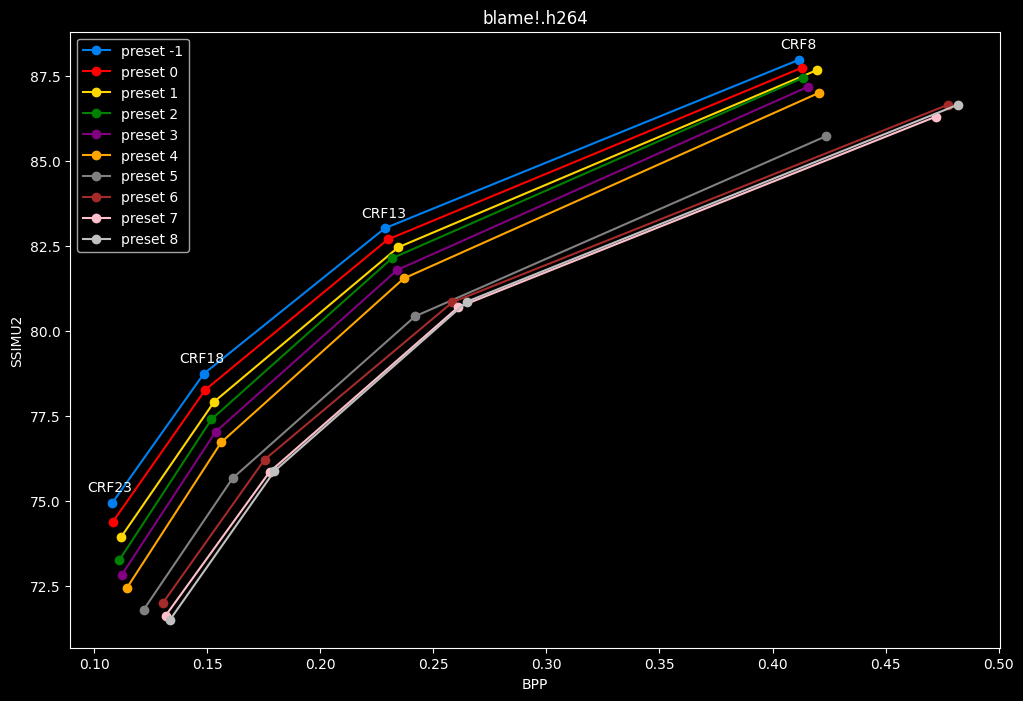
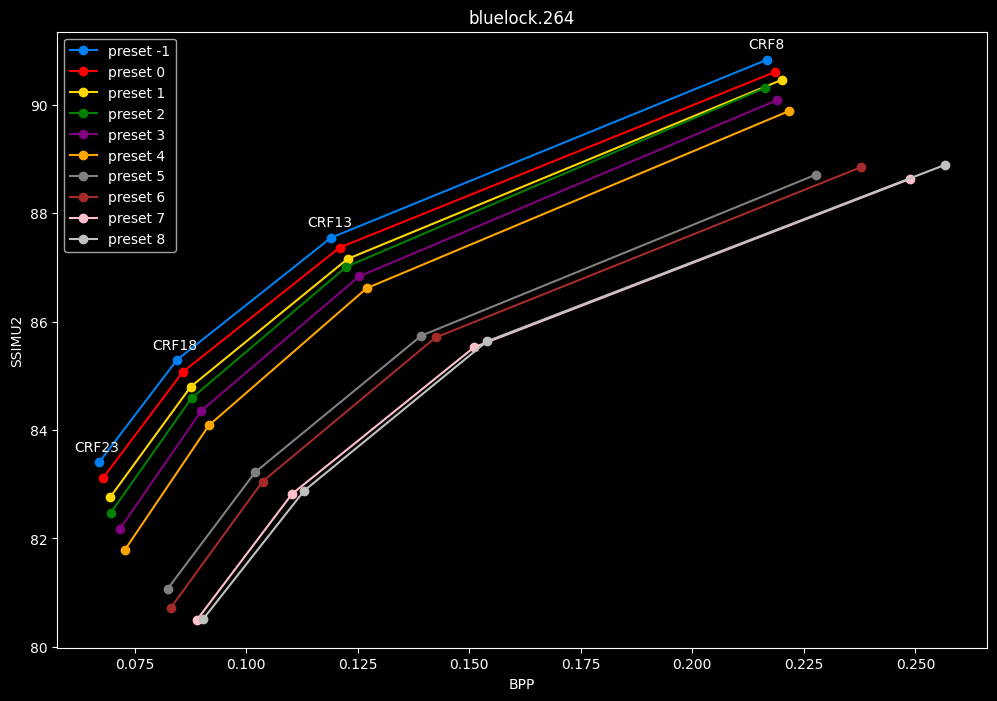
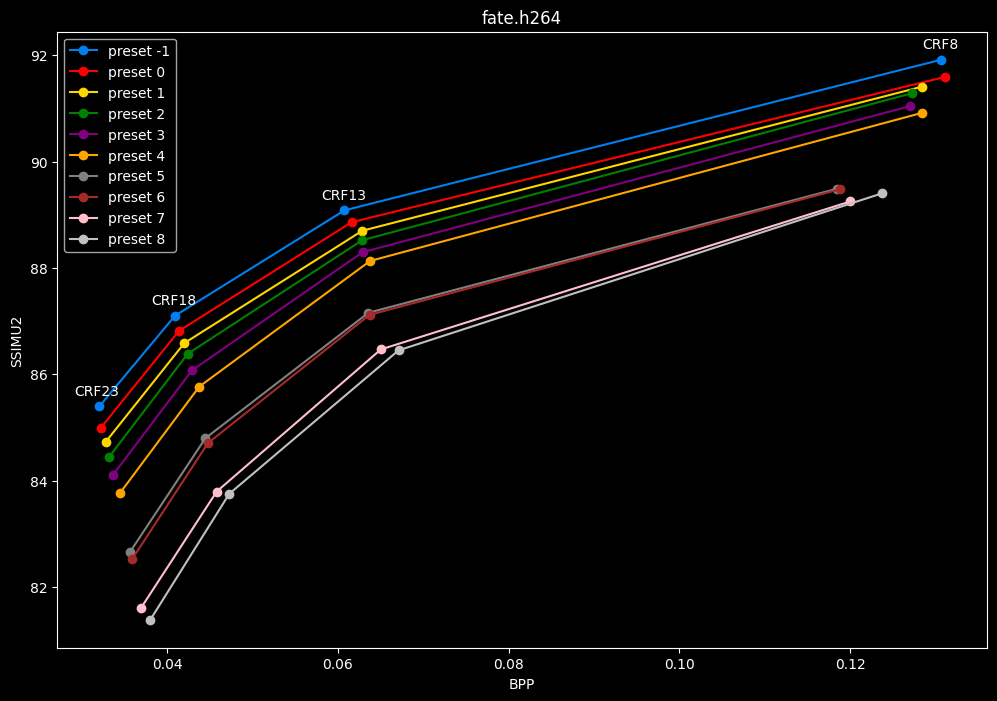
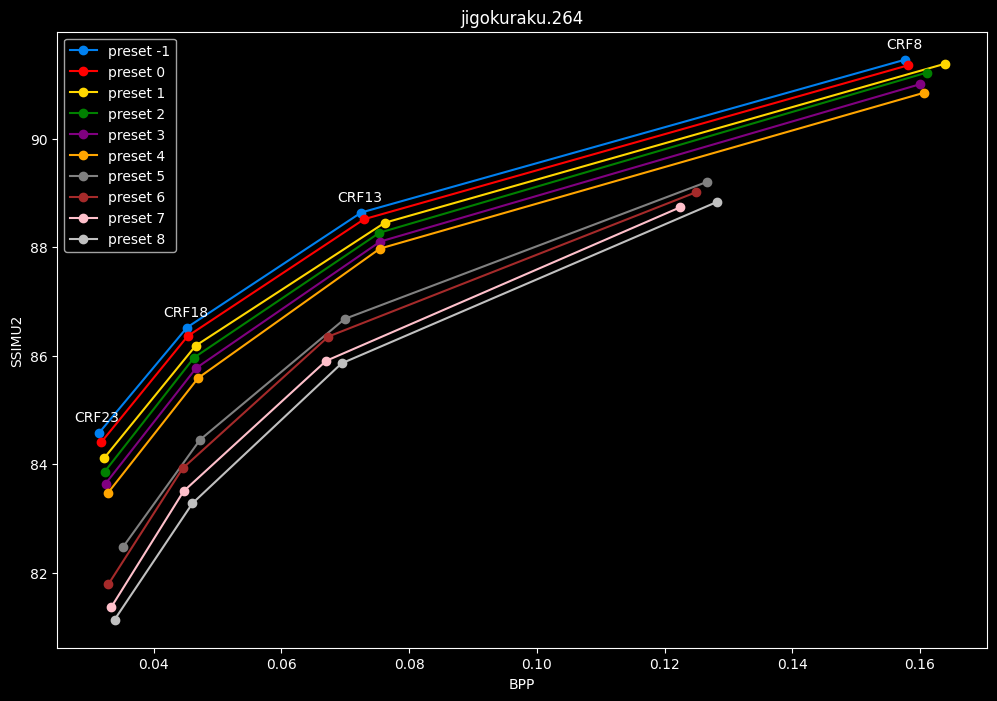
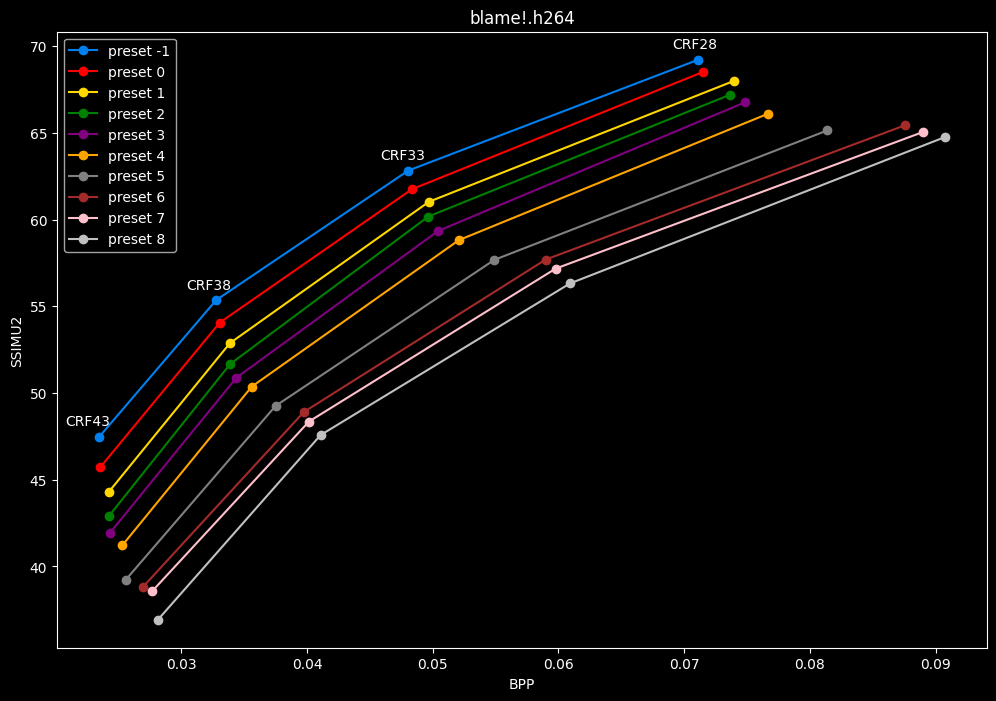
- Now for the "low quality" range (CRF28 -> 43):
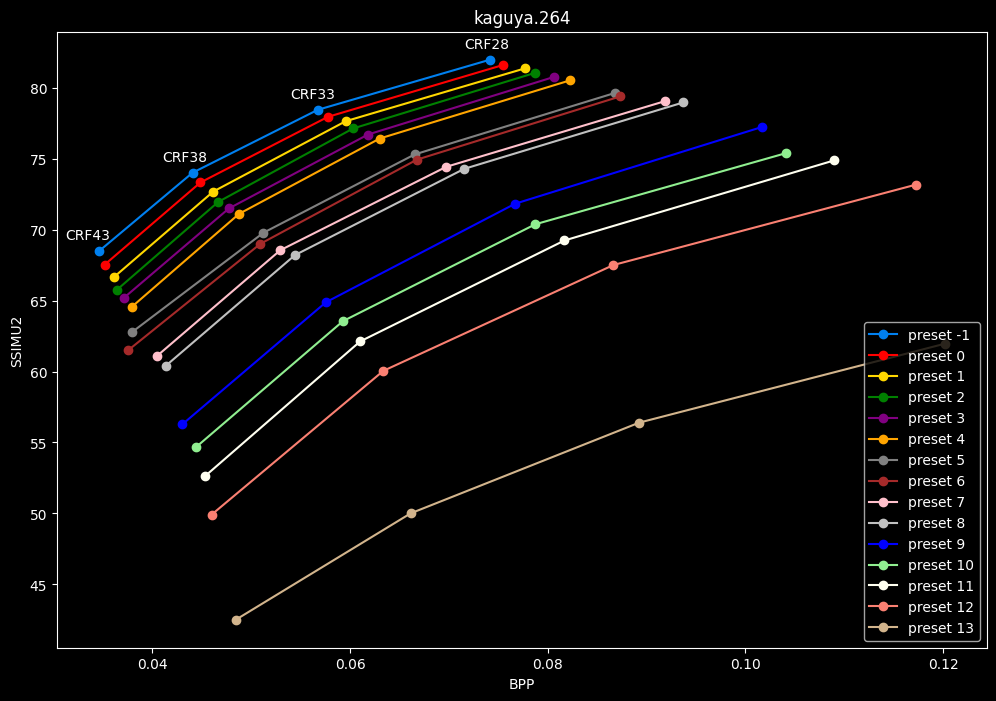

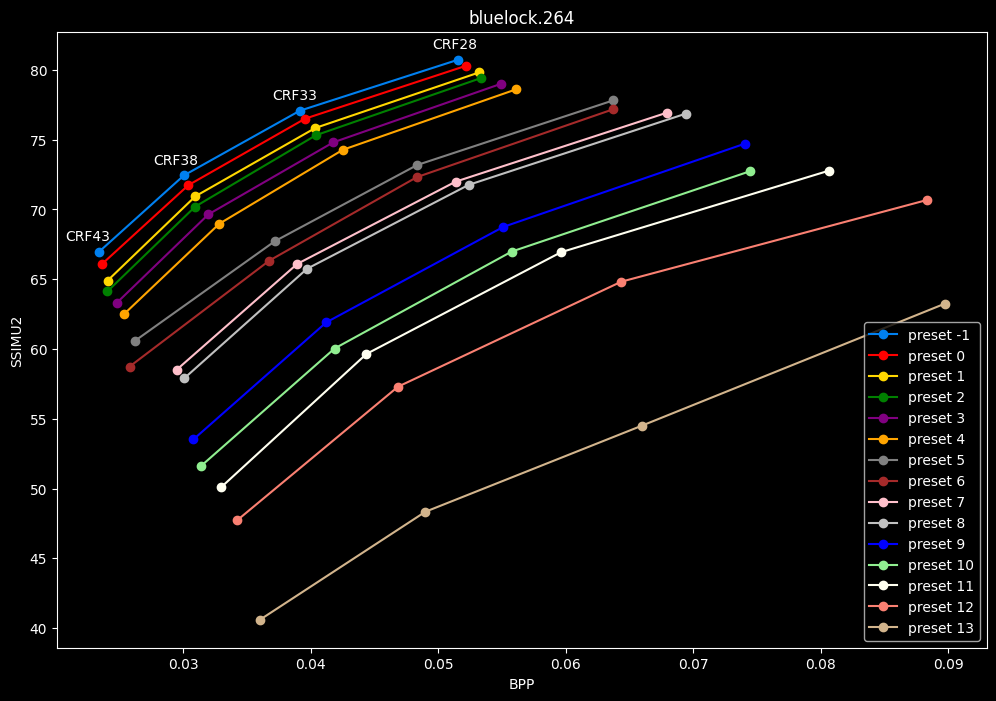
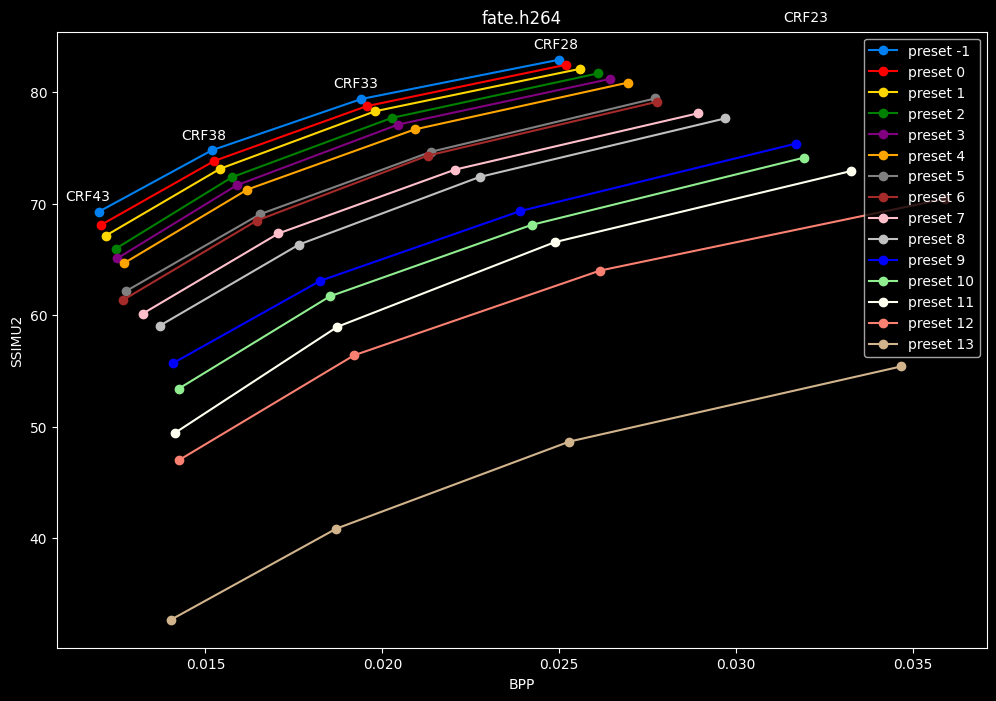
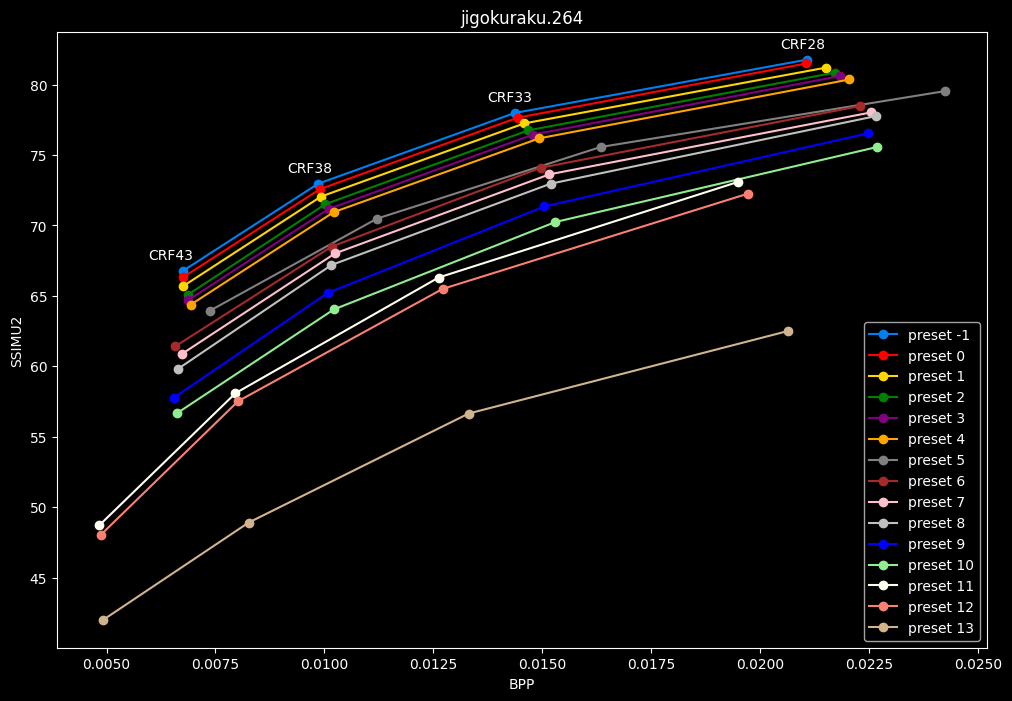
- Same but without presets 9 to 13 for better clarity:

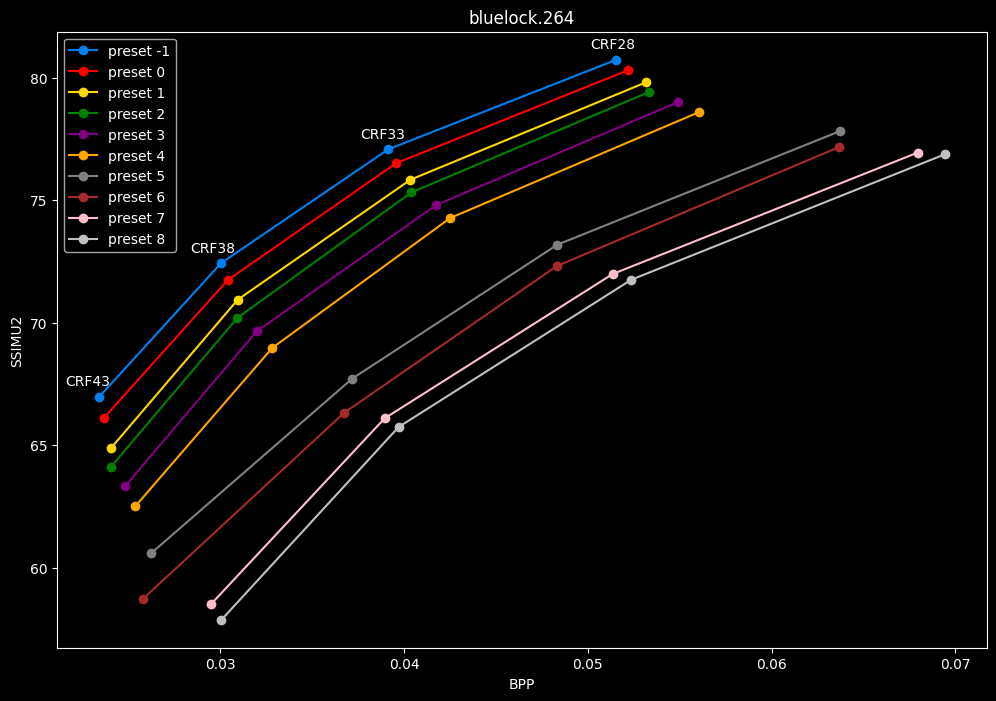
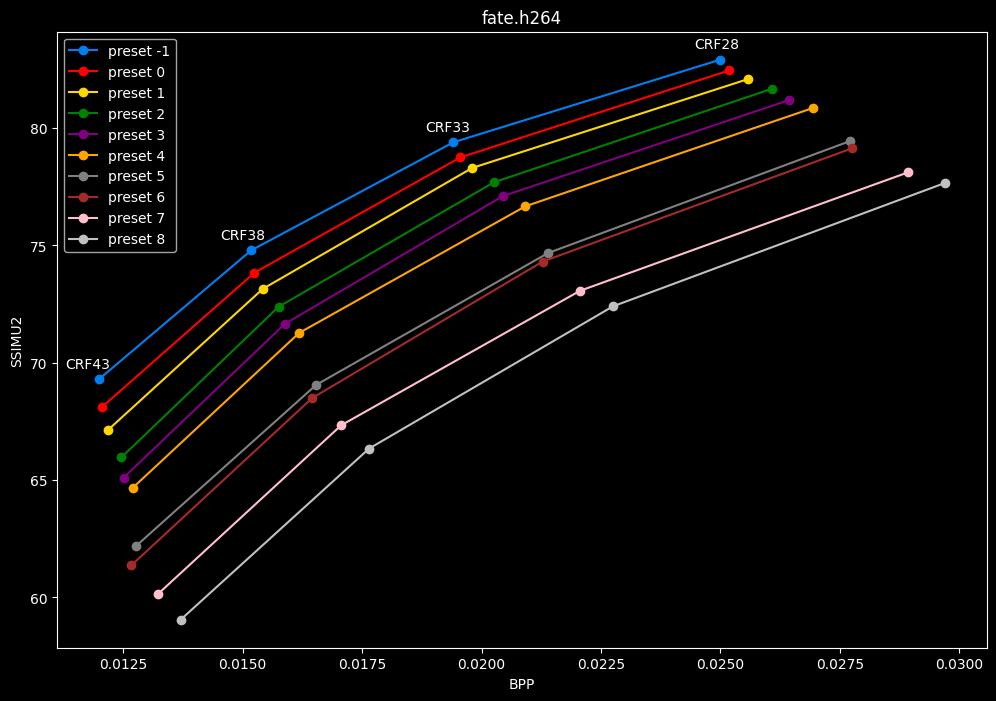
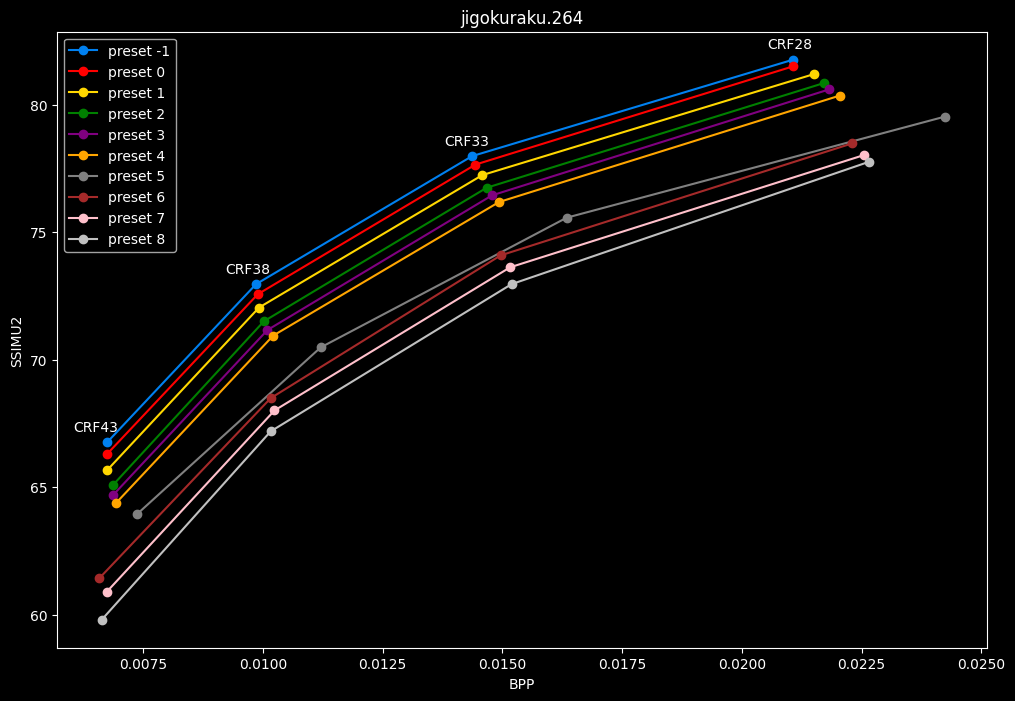
- Let's now see speed comparisons between all presets:
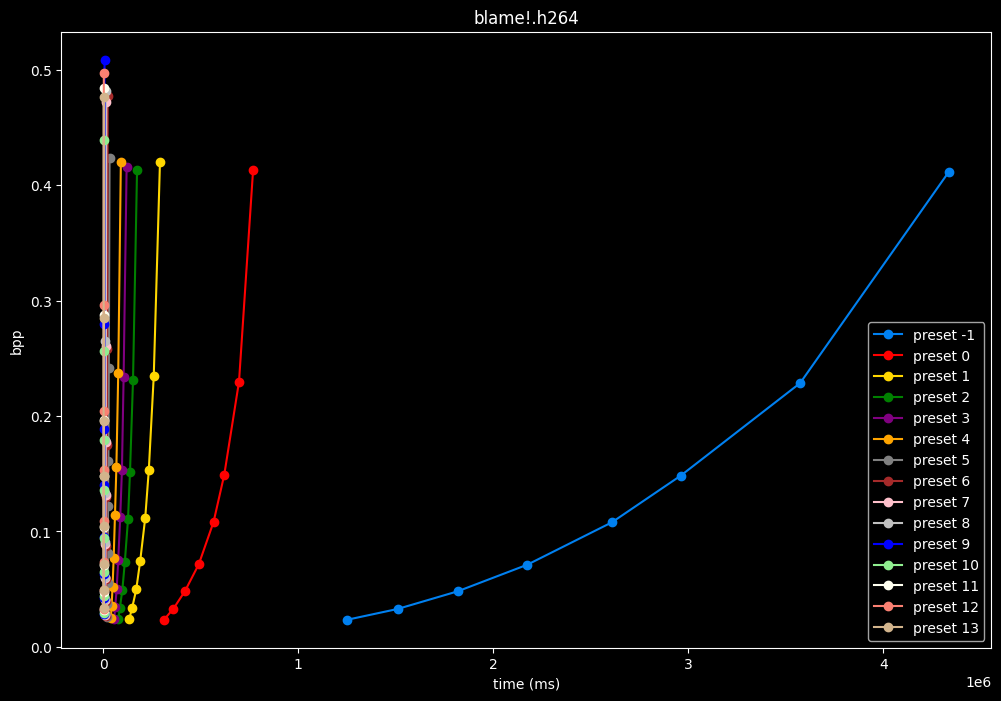
As we can see, preset -1 is so abysmally slow it makes the graph unusable
(BTW, notice the 1e6 in the lower right corner, it is obviously not encoding at 1 to 4 ms, but at 1 000 000 to 4 000 000 ms)
- Here is what it looks like with a logarithmic scale:
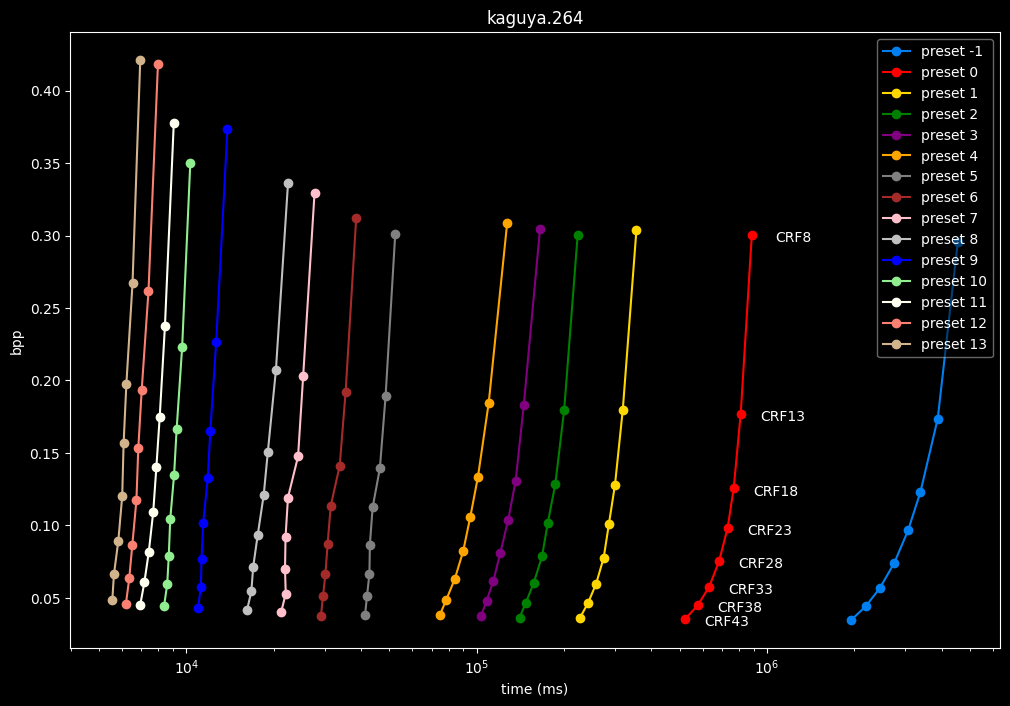
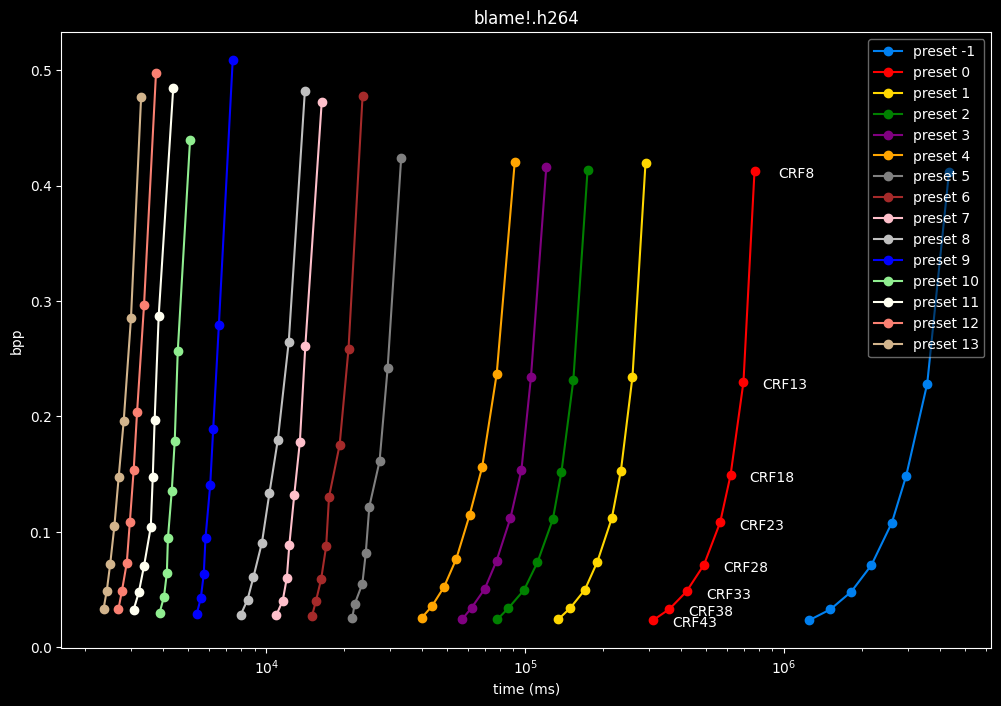
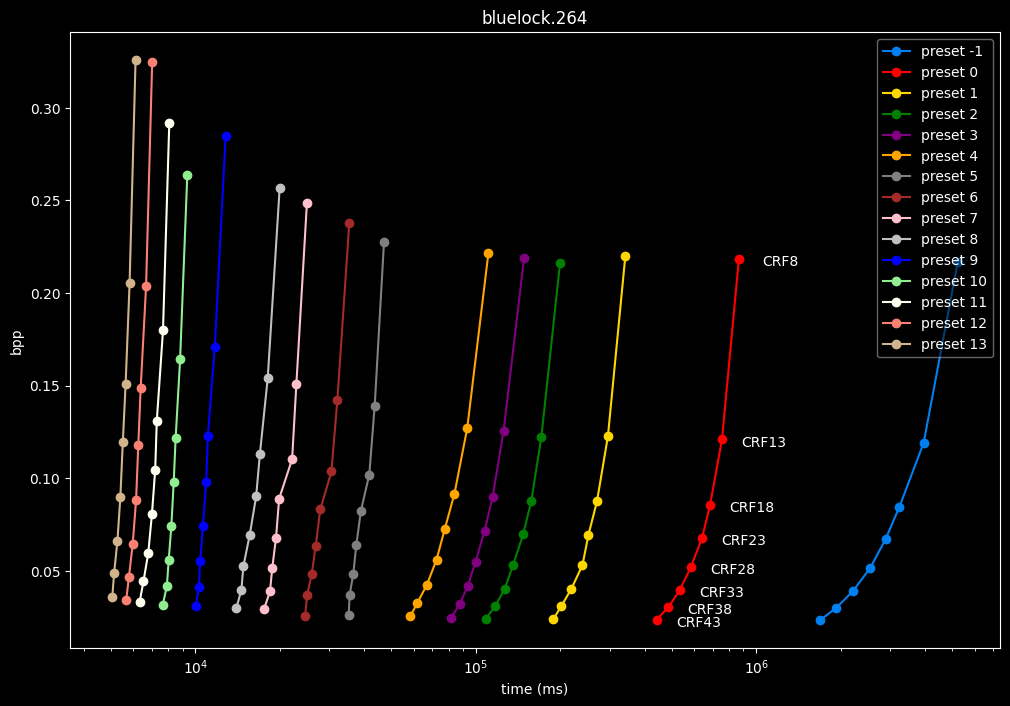
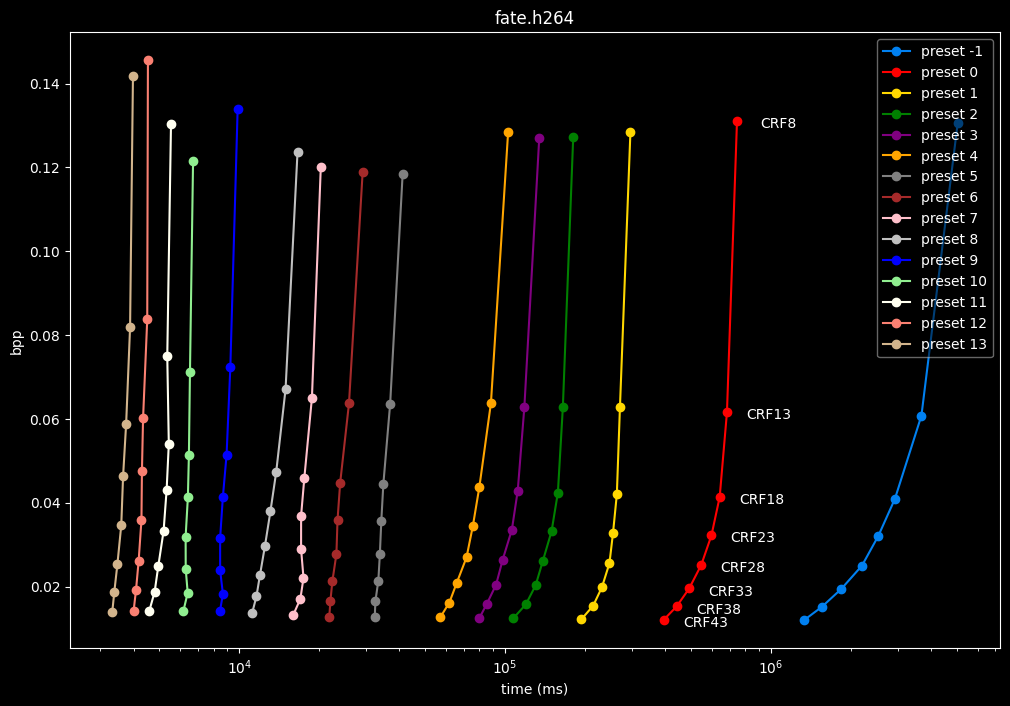
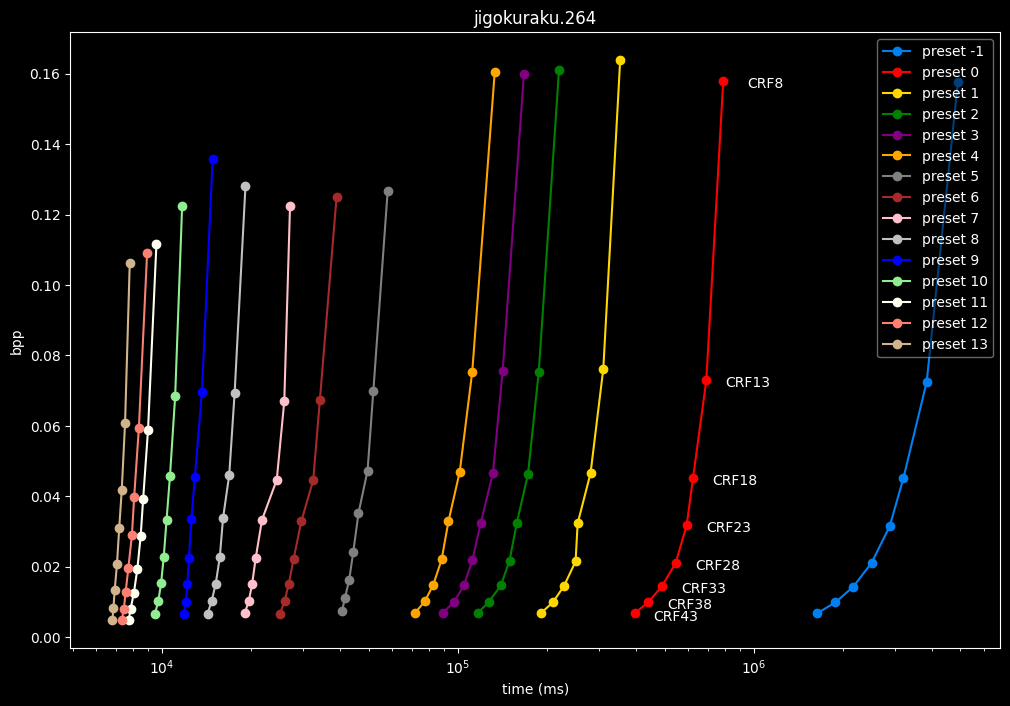
- Now the speed graphs but with SSIMU2 on the y-axis instead of BPP: (logarithmic scale)
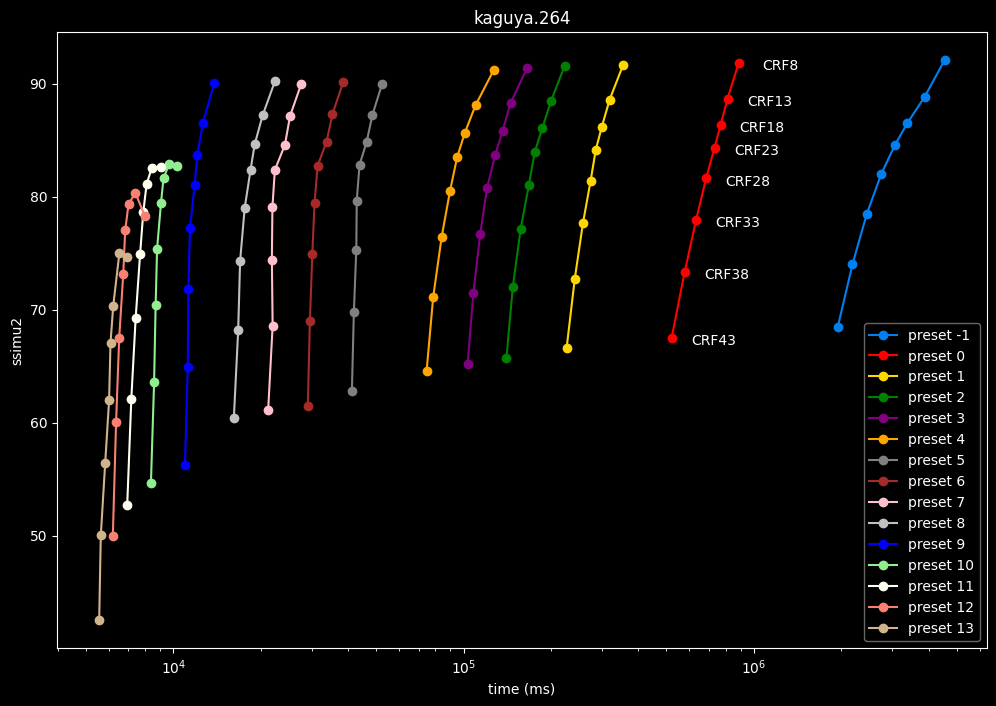
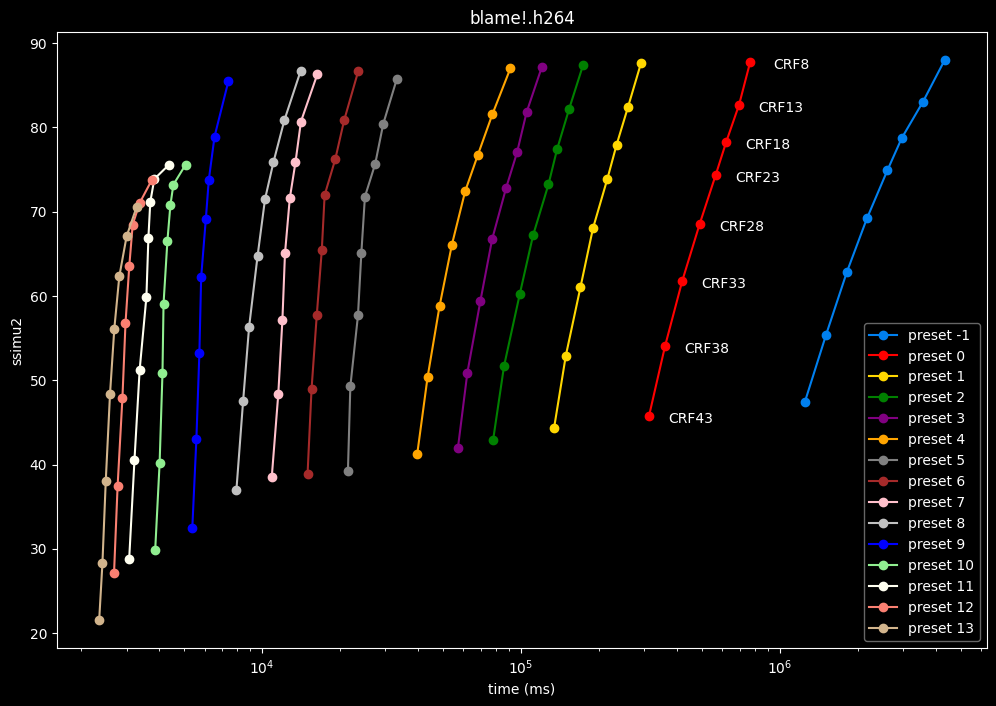
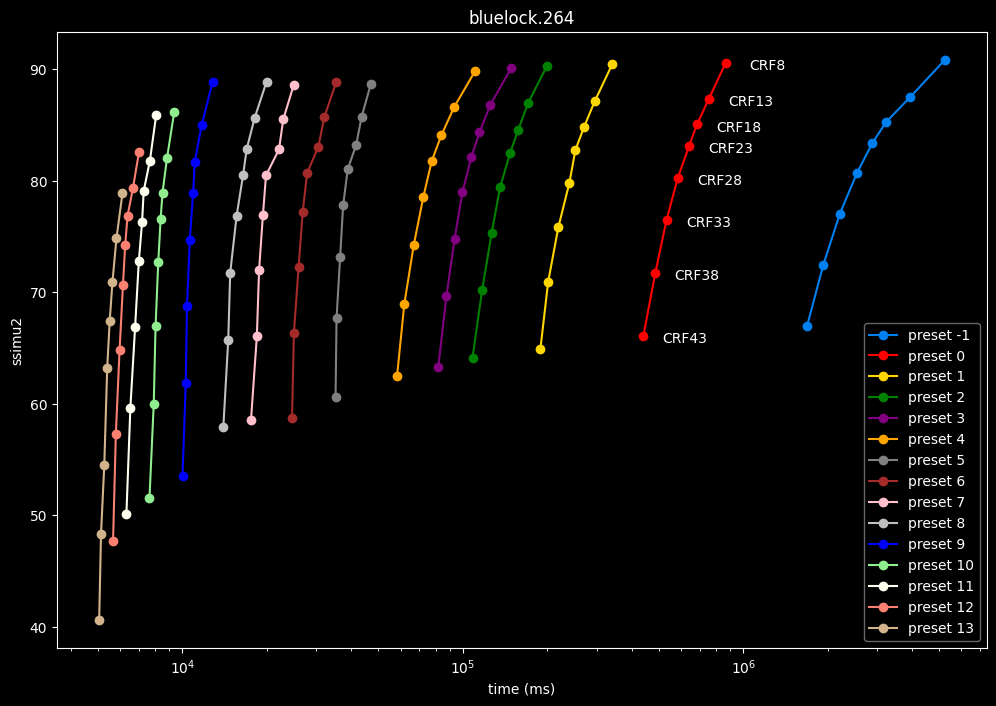
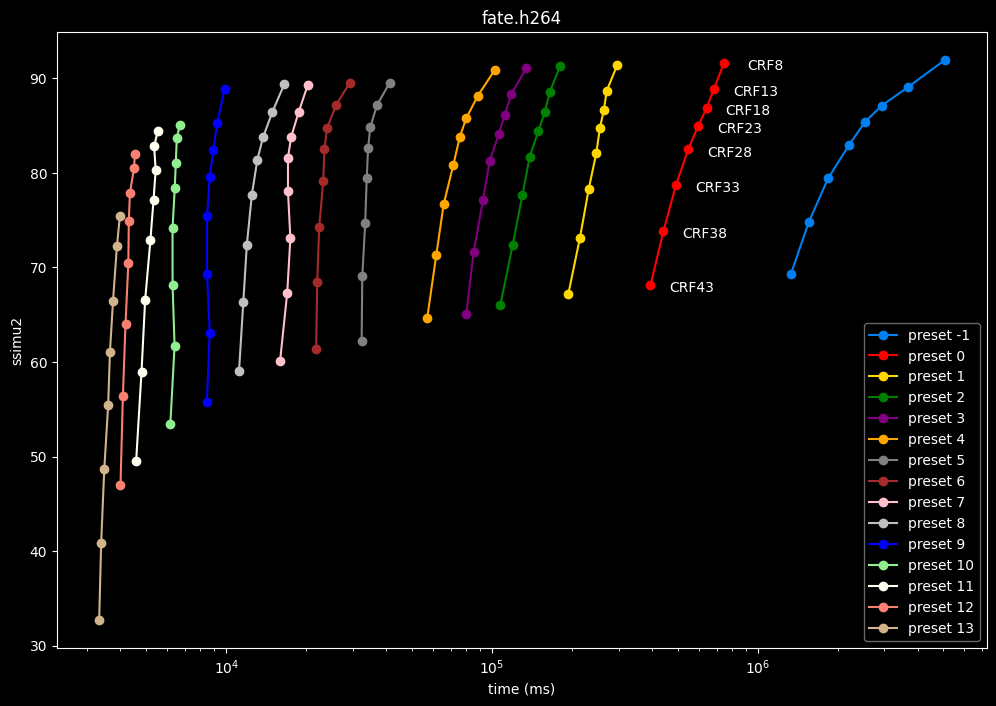
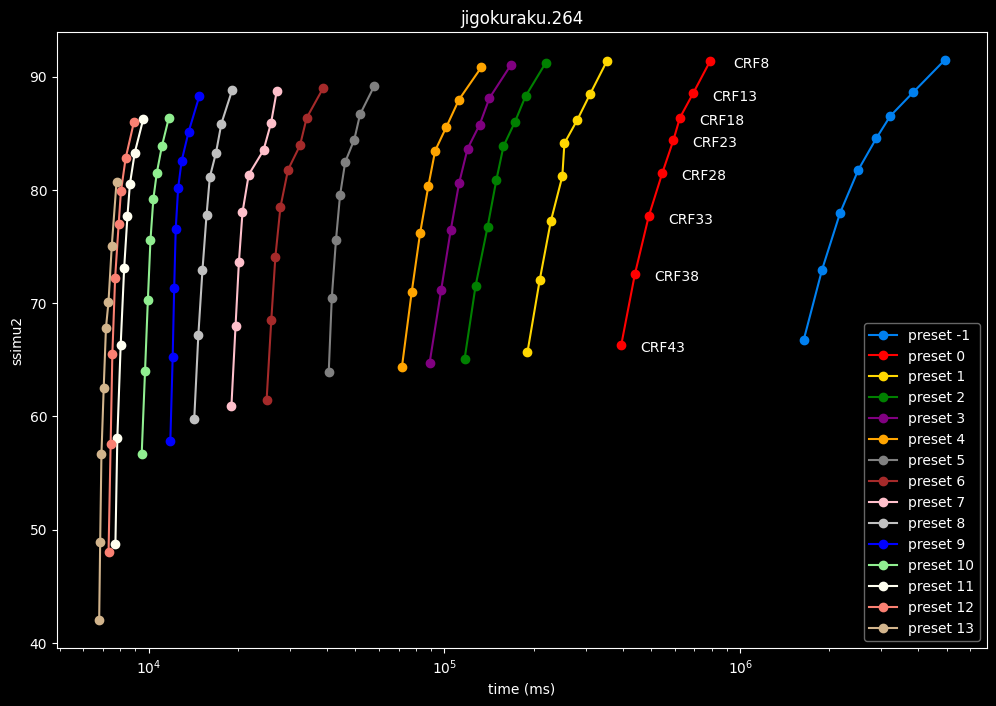
- Here are speeds graphs for preset 1 to 6 with a linear scale:
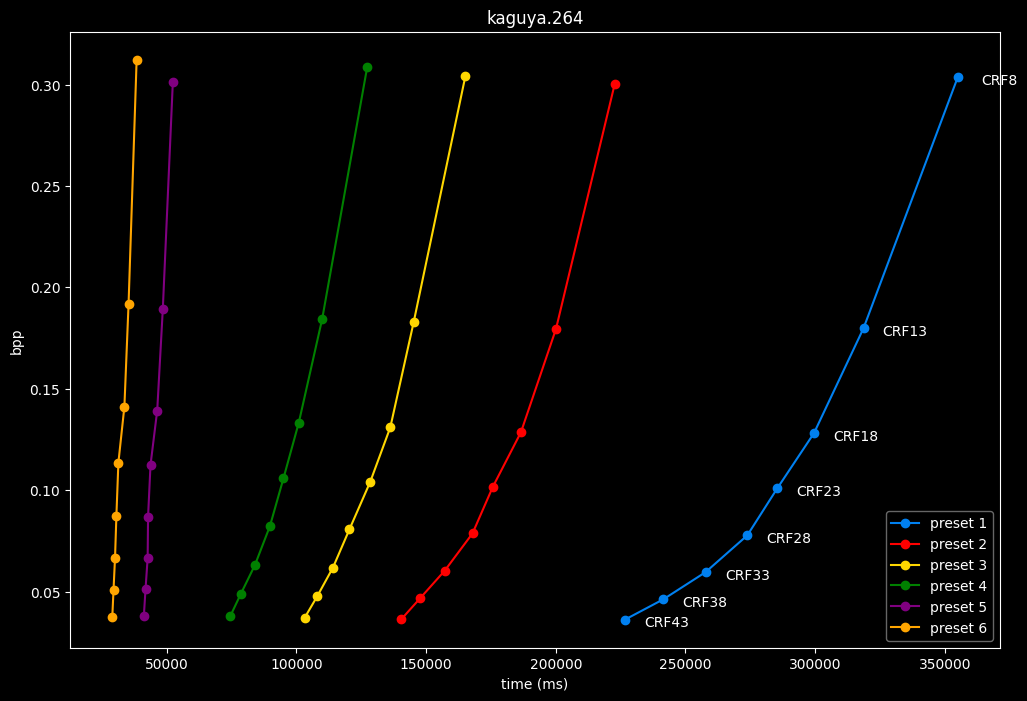
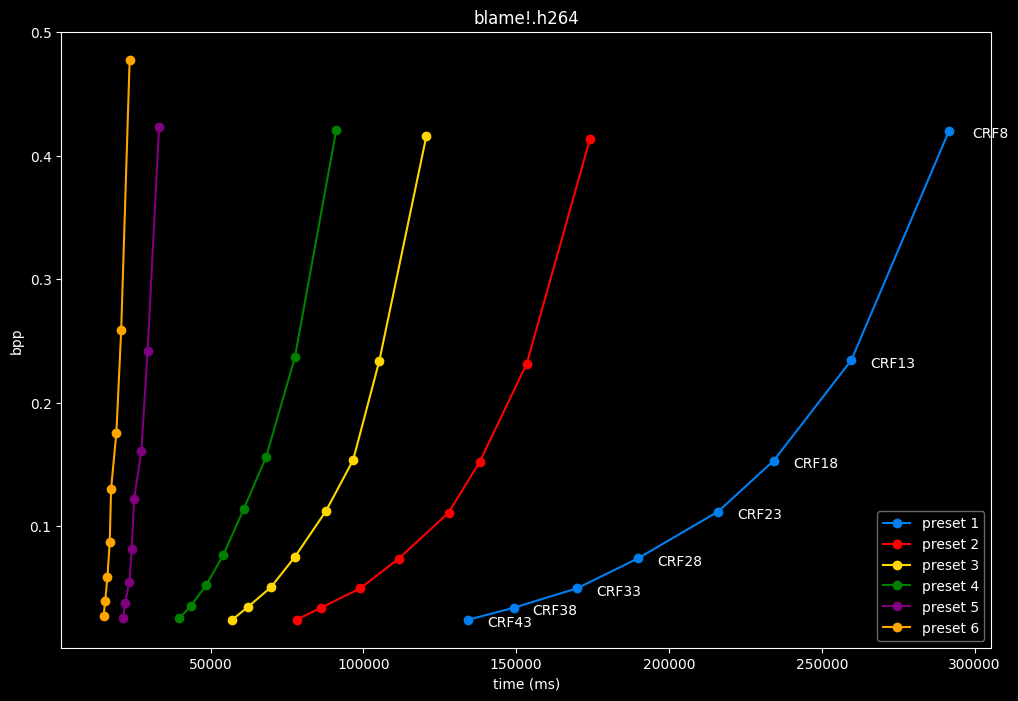
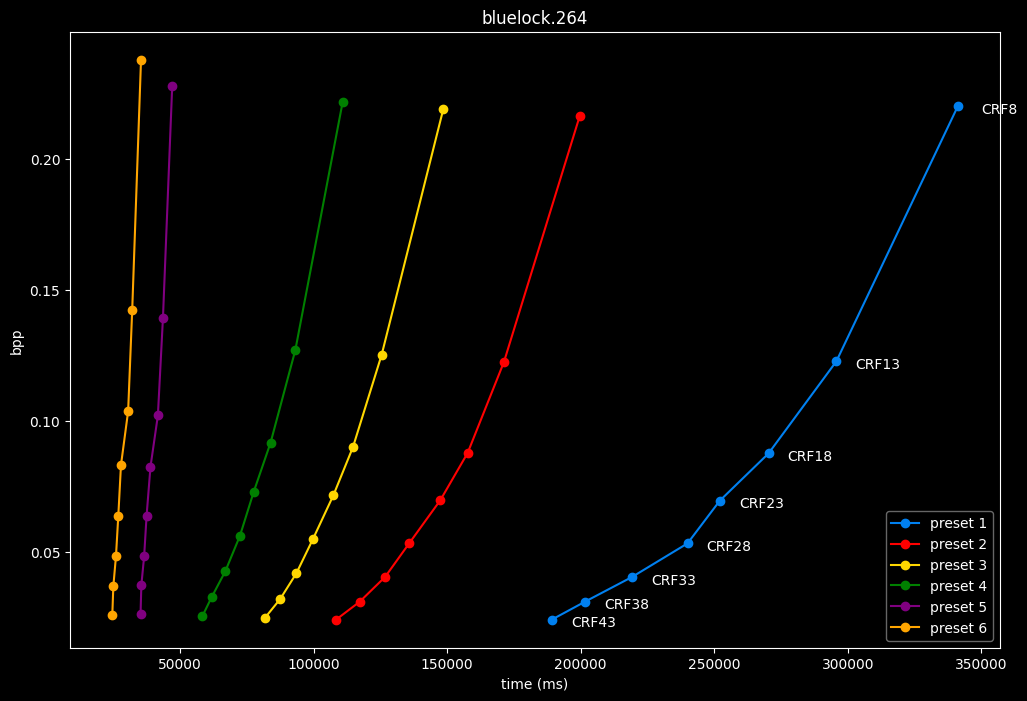
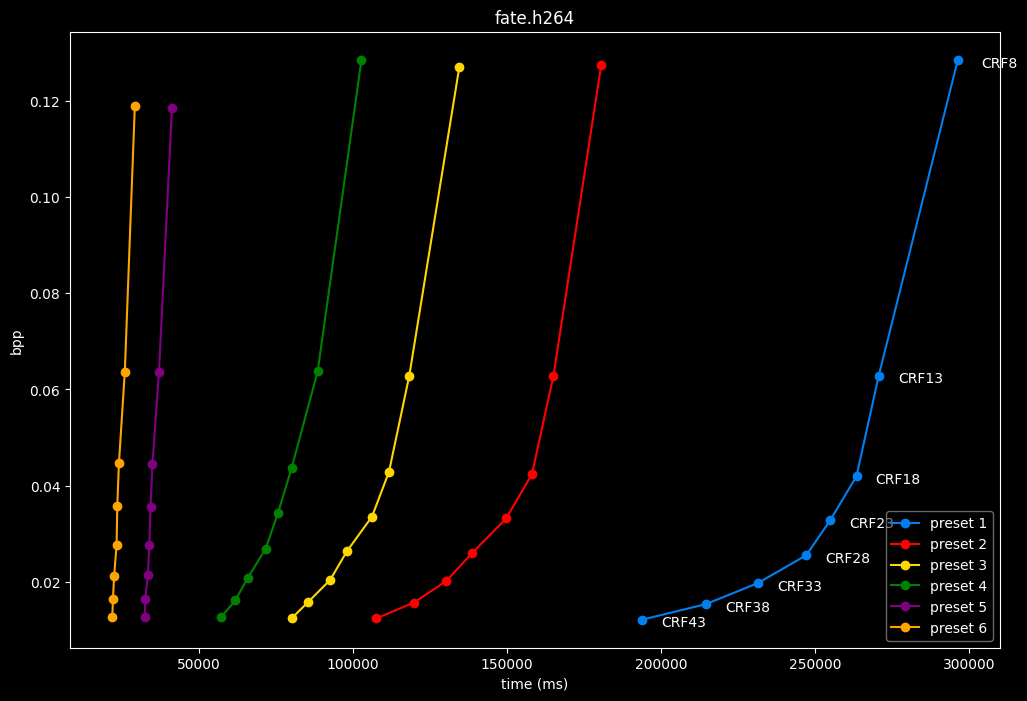
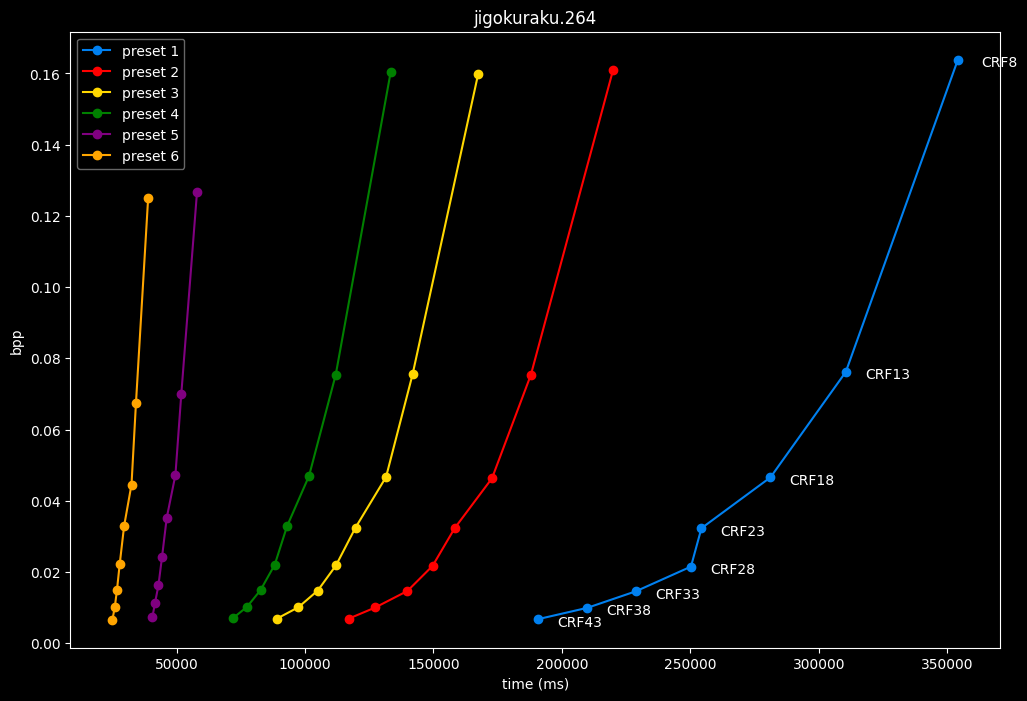
One interpretation we can have is that presets 2 to 4 have actually pretty close scores (pretty much the same at HQ, 2 points at max in the low quality range) but preset 2 is 2x slower than preset 4. The quality gap between preset 2 and preset 1 is even narrower but the speed penalty is also ~2x.
That makes it hard to recommend preset 1, while preset 3 is in a strange middle ground between 2 and 4 where it makes little sense to choose it over those two: it's better to choose preset 2 for the higher efficiency at 1.5x slower speeds, or preset 4 for the 1.33 to 1.5x higher speeds. At least the option exists.
A similar observation can be made between preset 5 and 6. They can be so close in scores in many samples (especially at HQ) while also being close in speeds that preset 5 becomes rather obsolete most of the time.
TLDR
Clear quality gains can be observed as we decrease presets, until the very last one, however the effectiveness of dropping presets becomes less and less impressive the higher in quality you go.
-
For instance, in worst-case scenario, we observe that (for the CRF23 to CRF8 range), preset 4 only loses at maximum 2 SSIMU2 points compared to preset -1 while being 50-60x faster. Though to be fair, the speed loss from preset 4 to preset 0 is "only" 5-10x for a maximum SSIMU2 difference close to 1.5 point.
-
From CRF43 to CRF28, the difference between preset 4 and preset -1 can be as much as 5 SSIMU2 points, so lower presets become more attractive.
Tunes comparisons
In the following graphs, you may find comparisons between SVT-AV1 tunes, from the default --tune 1 (PSNR) to the other two tunes: --tune 0 (VQ) and --tune 2 (SSIM).
Except for the tunes, --preset 4 is set due to its good balance of quality and speed, in conjunction with the CRF values. That means everything else is default. The defaults have been mentioned earlier above.
- Let's compare the efficiency of every tunes:
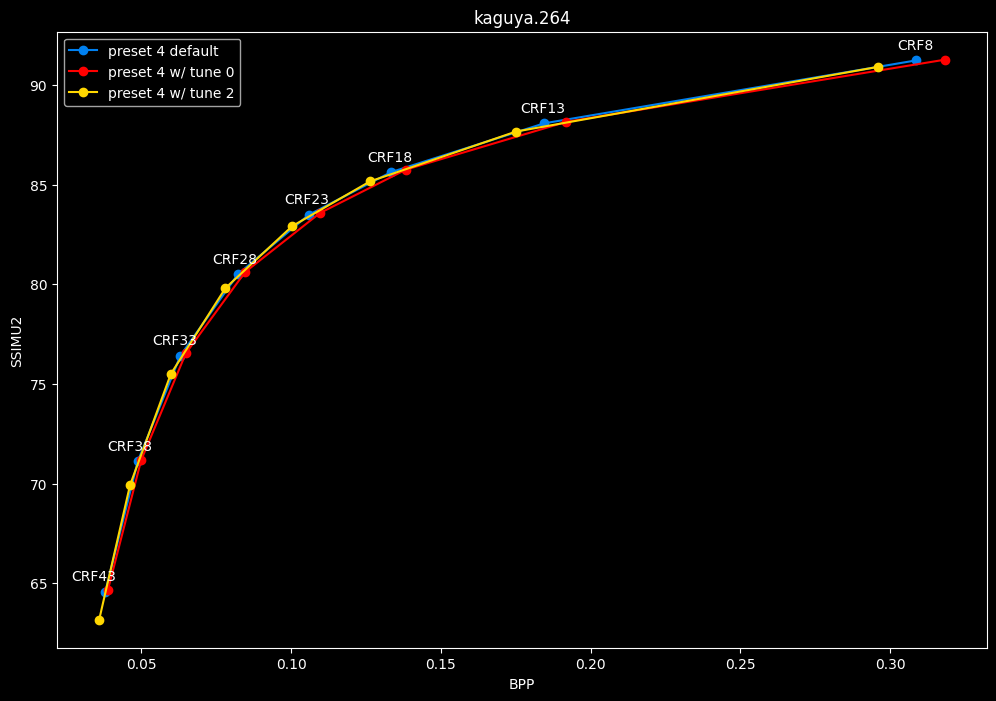
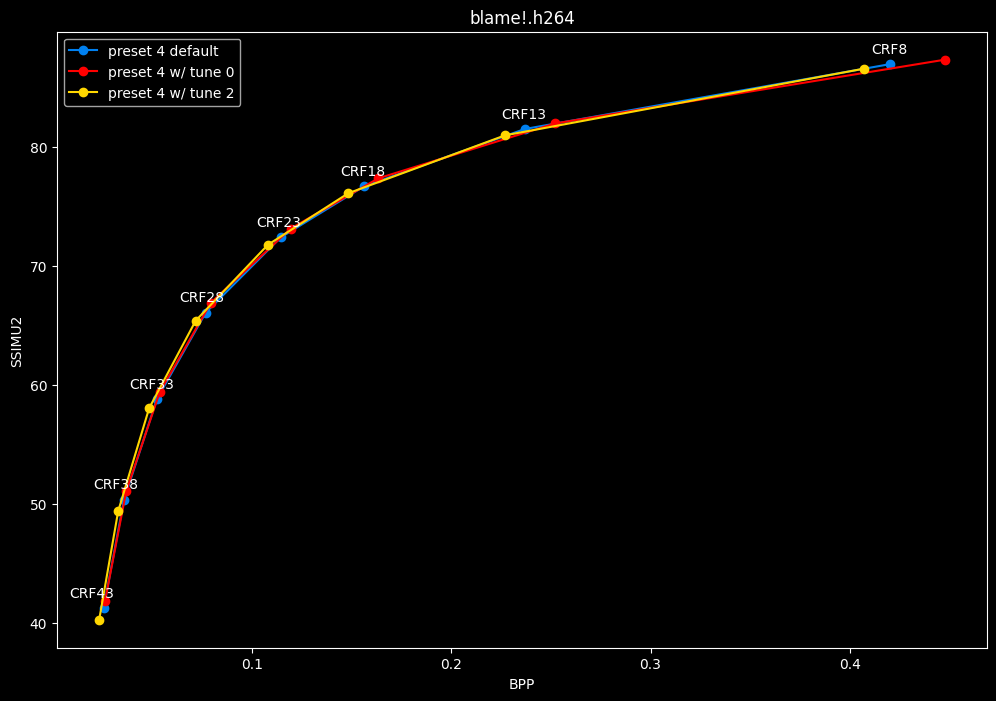
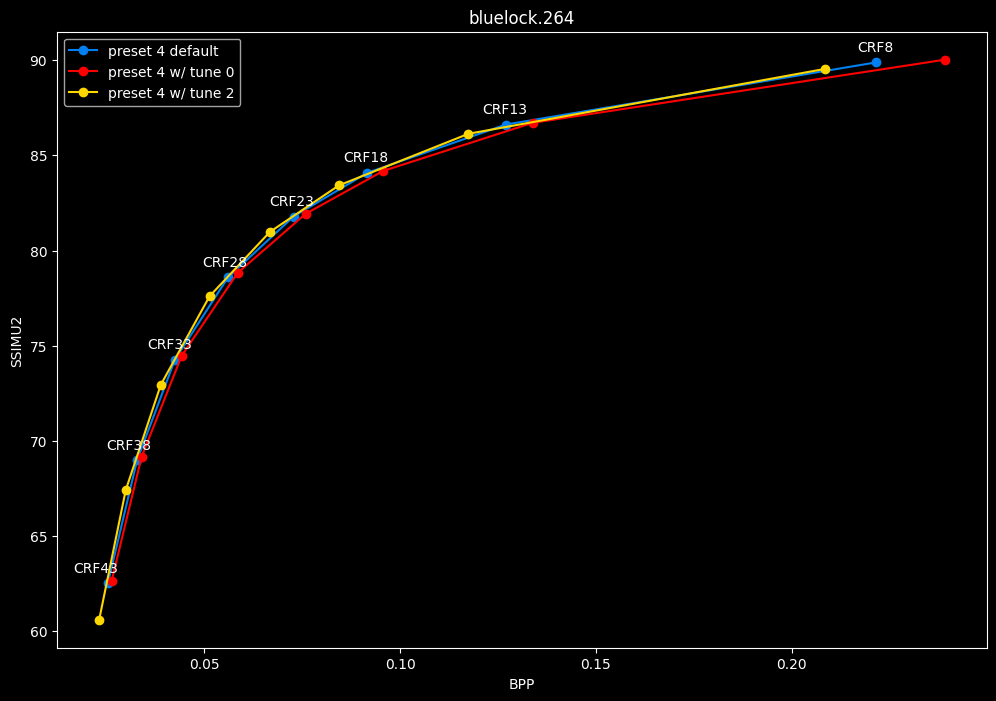
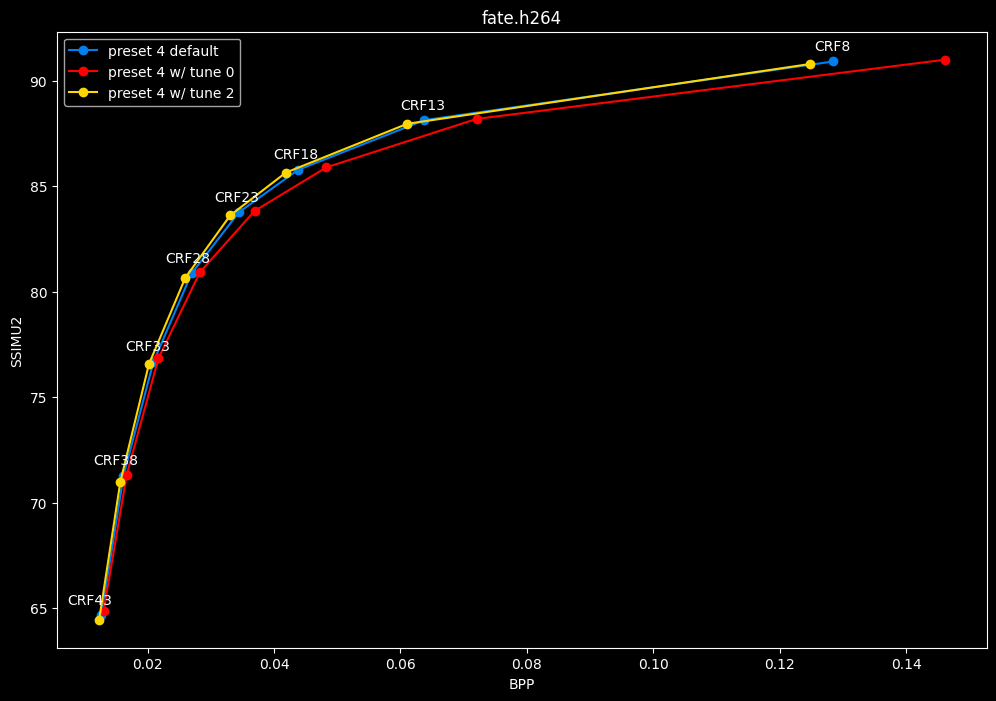
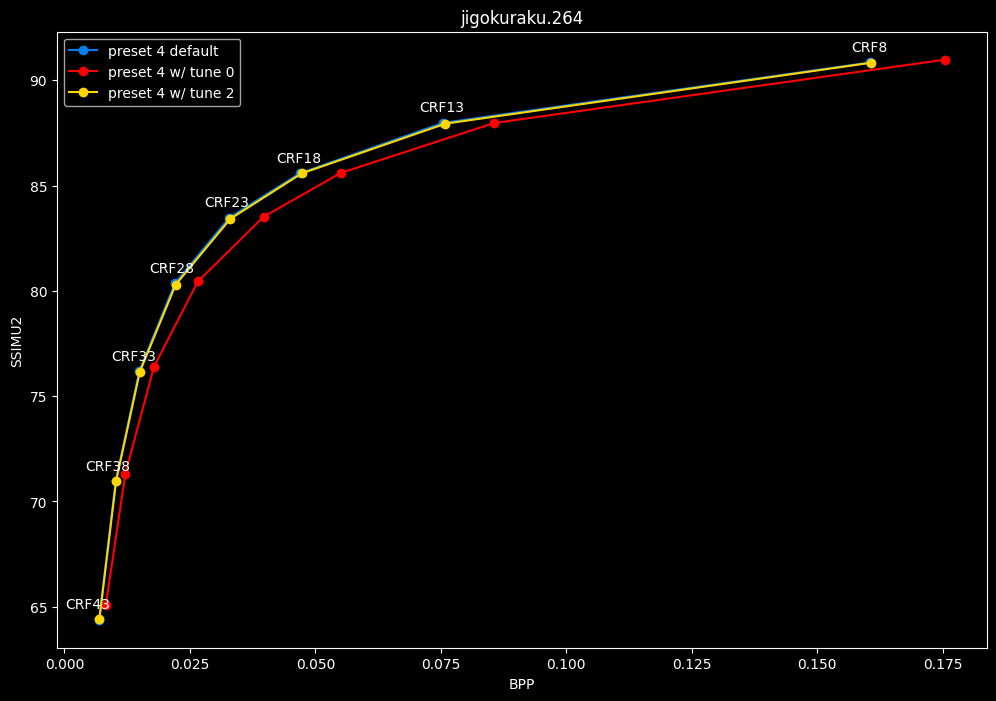
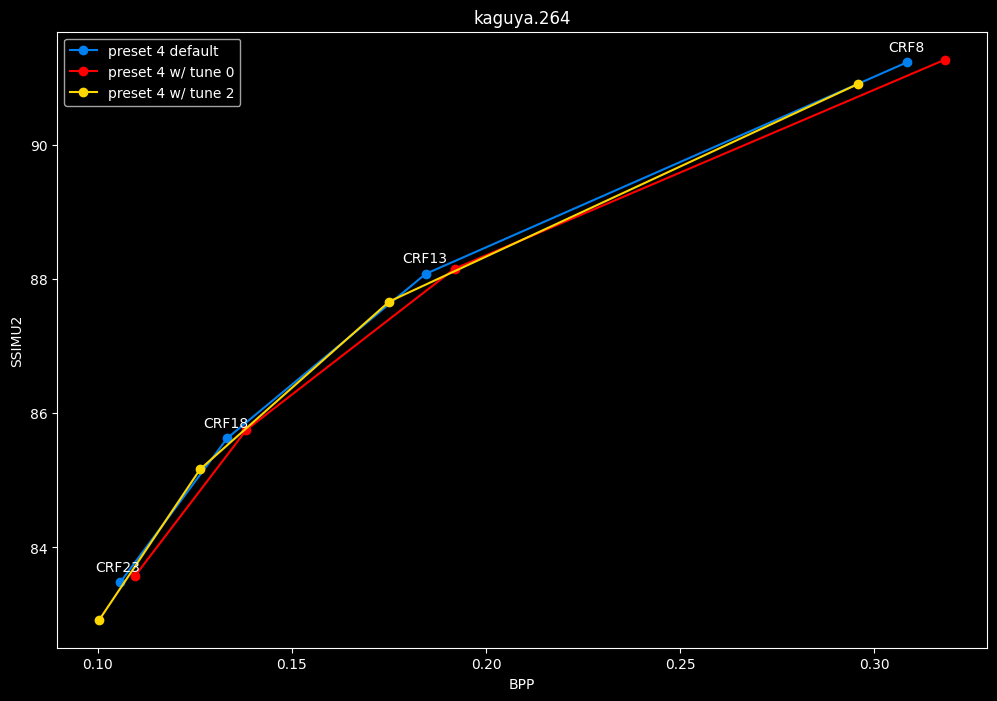
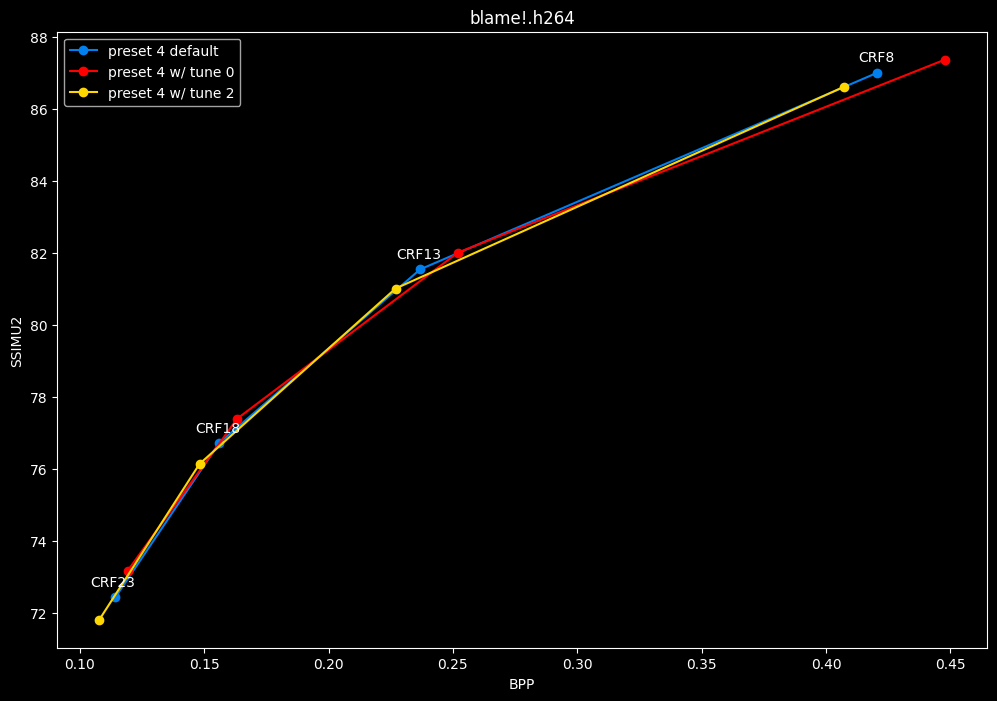
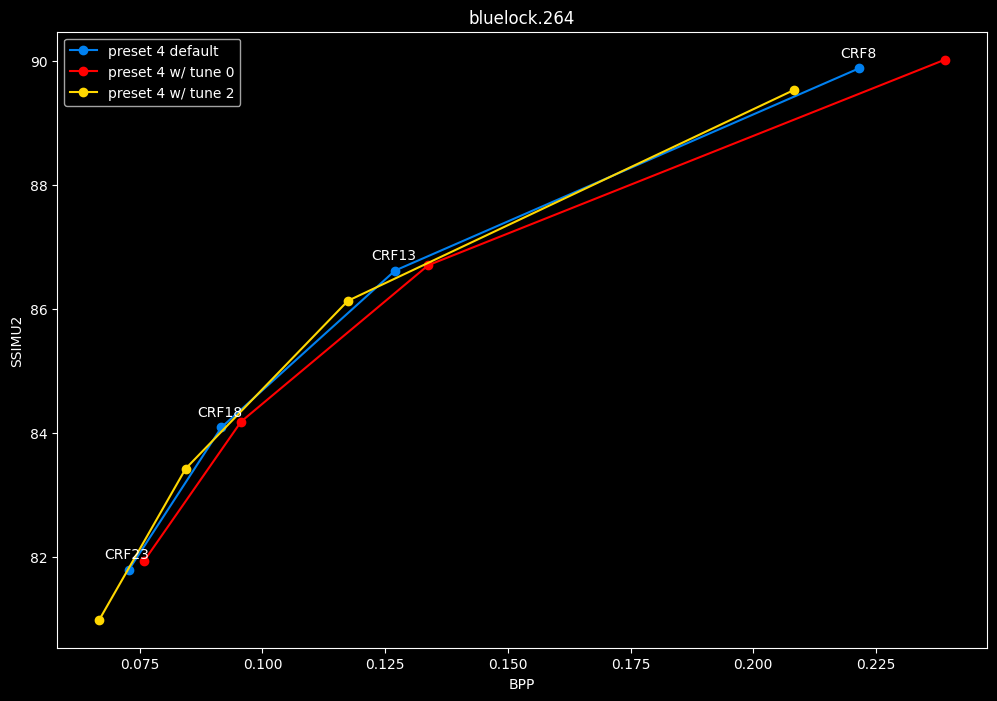
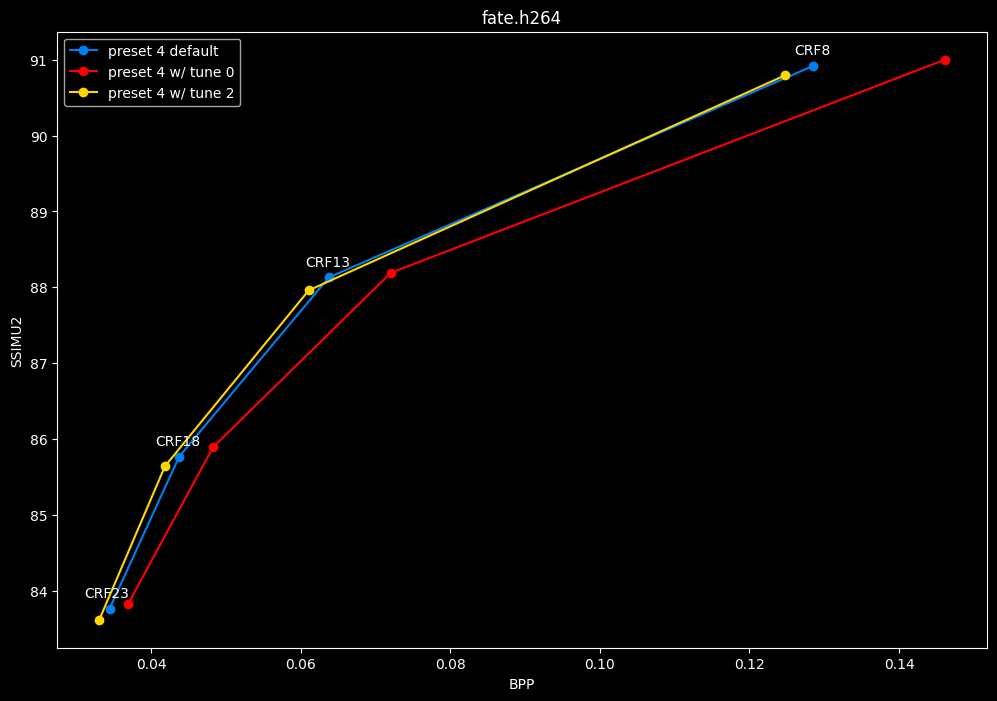
- Now let's focus on the "high quality" range (CRF8 -> 23):
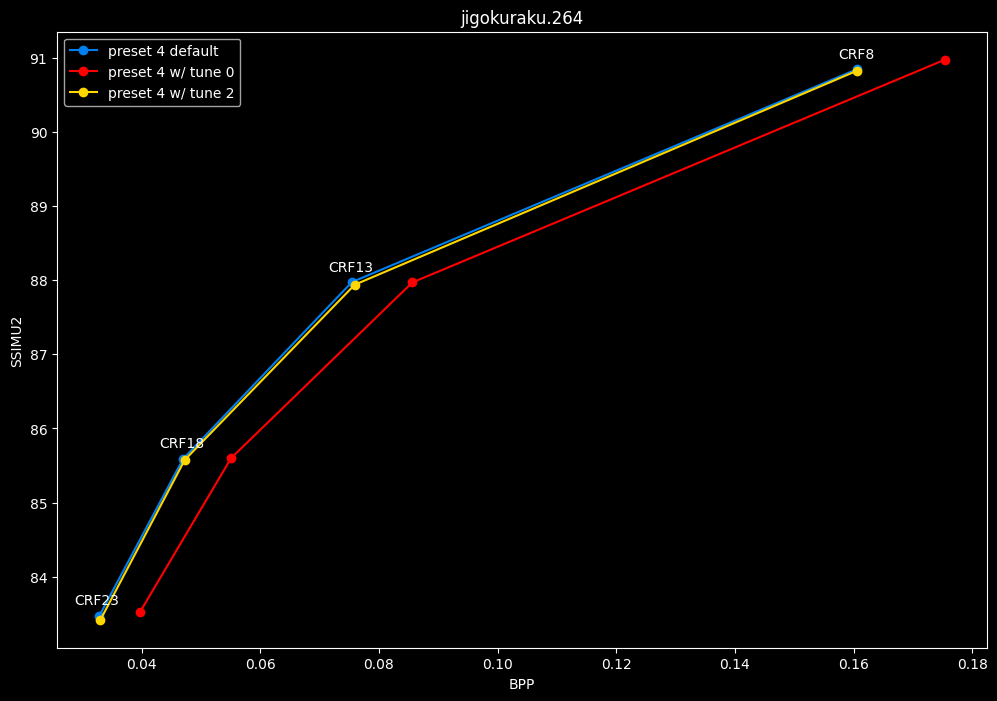
- And the "low quality" range (CRF28 -> 43):
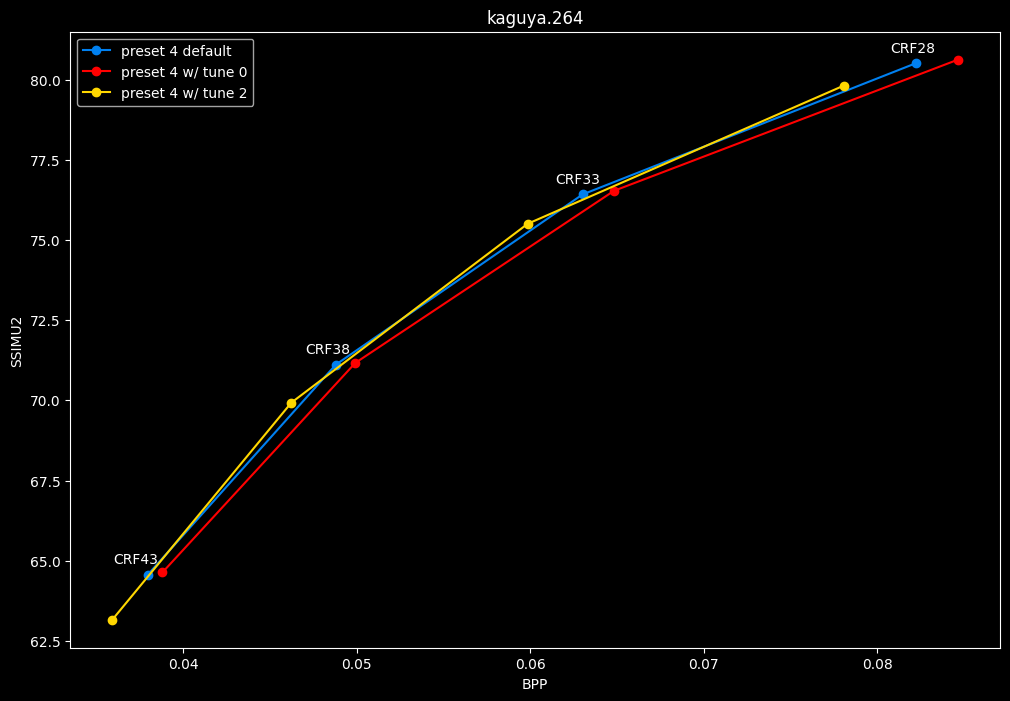
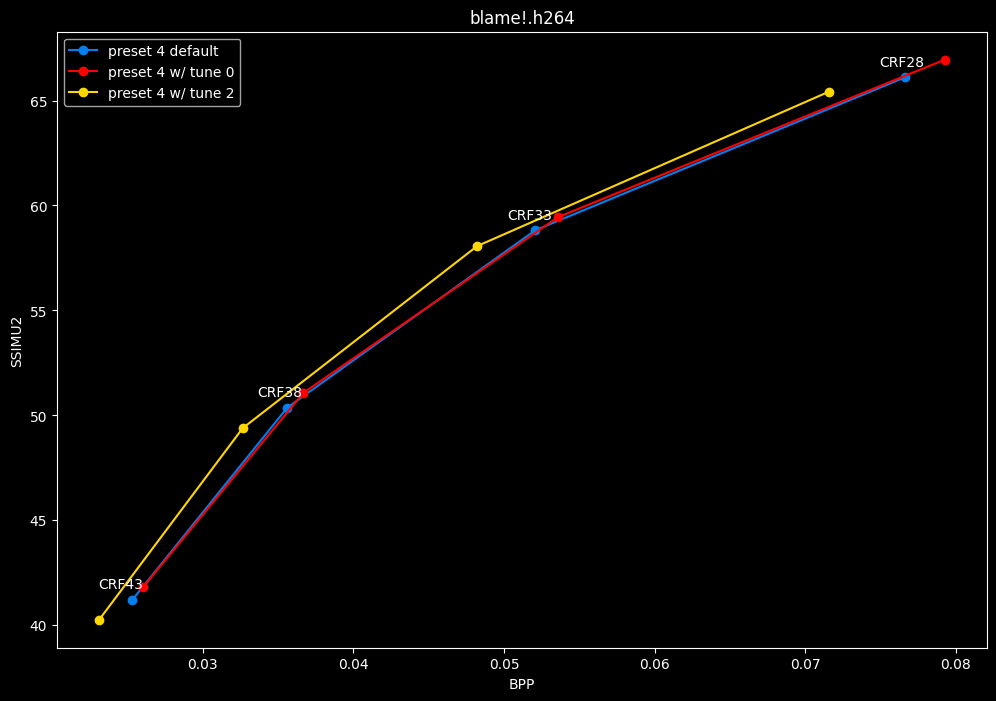
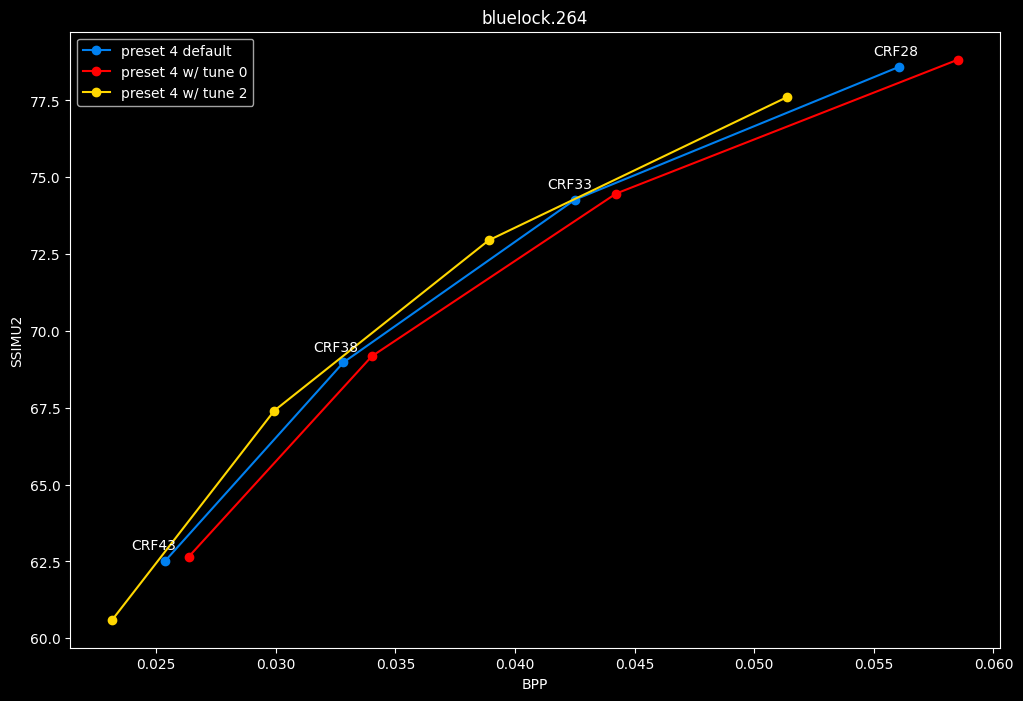
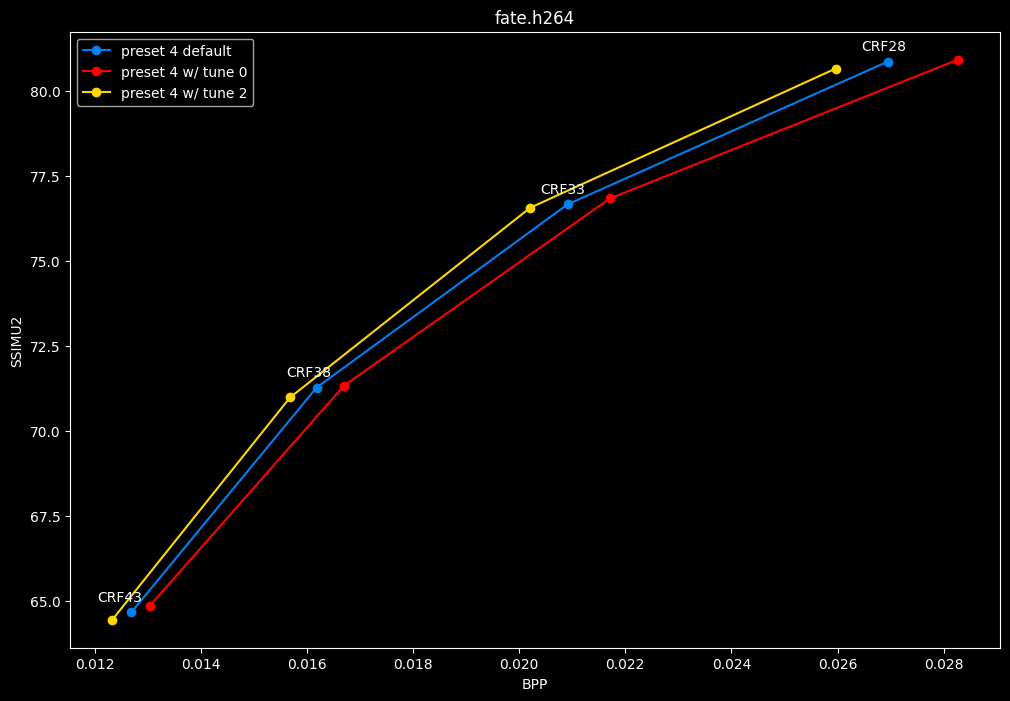
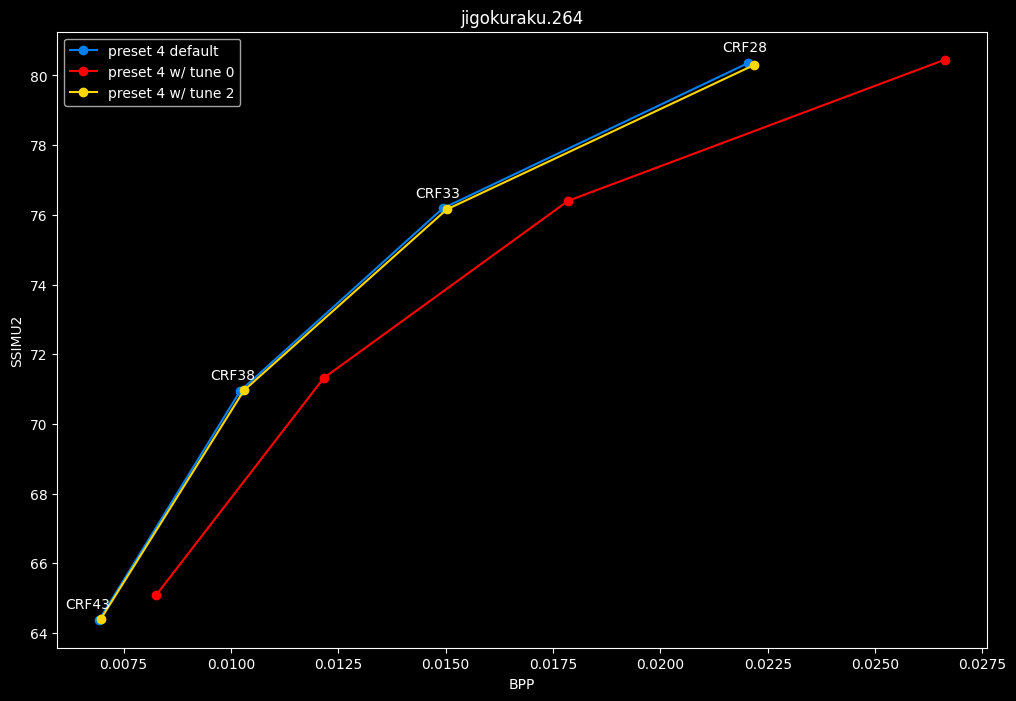
- And here is the speed difference:
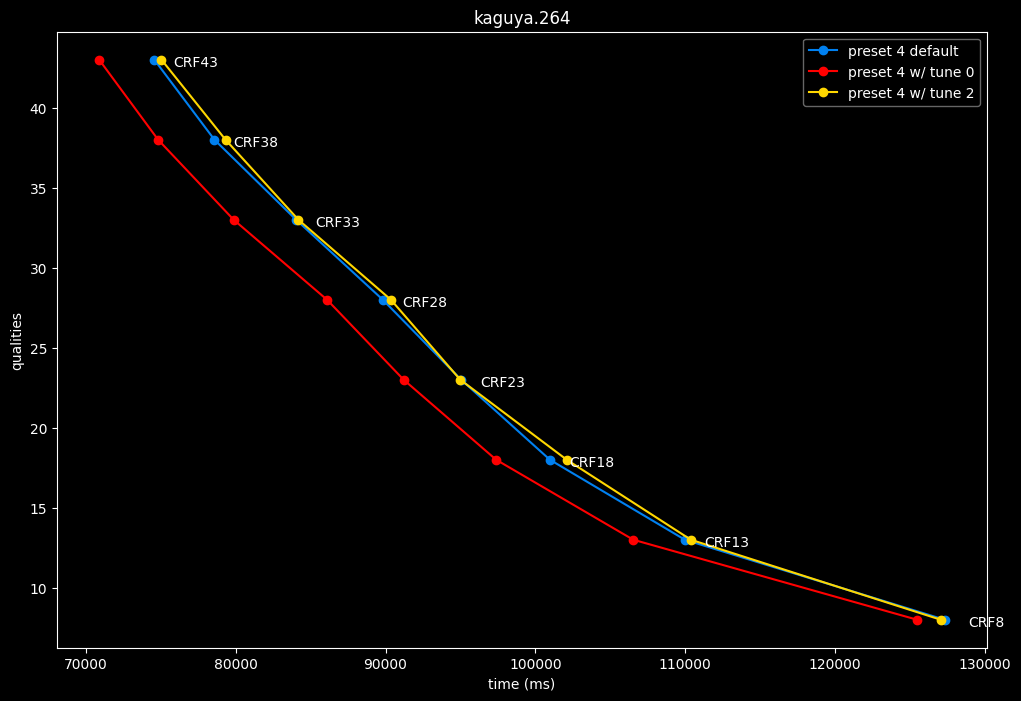
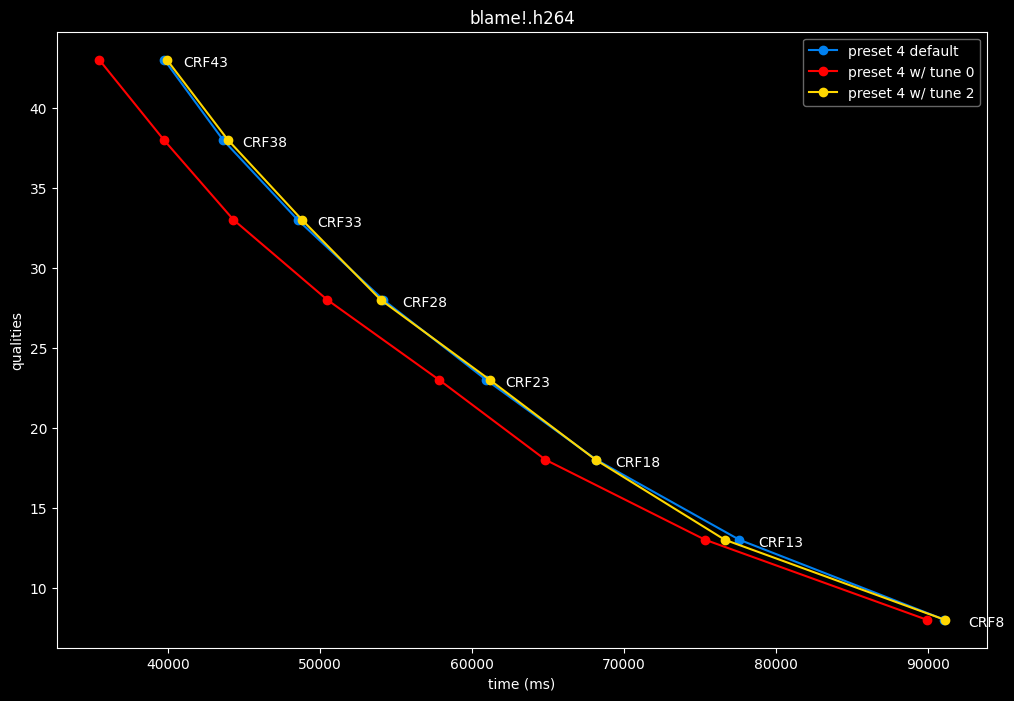
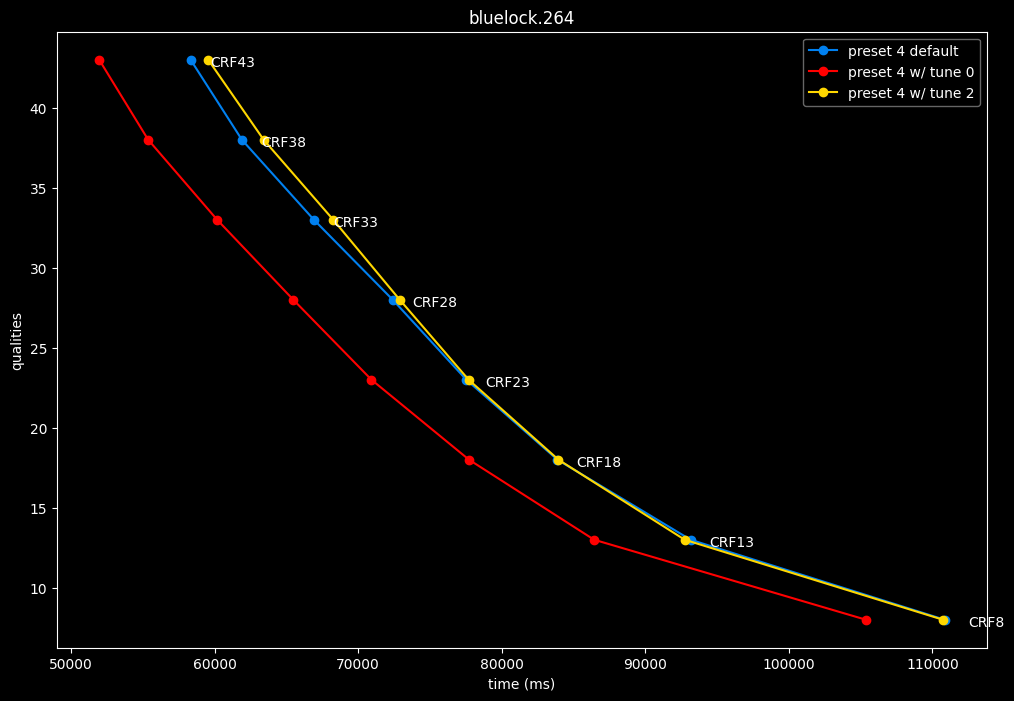
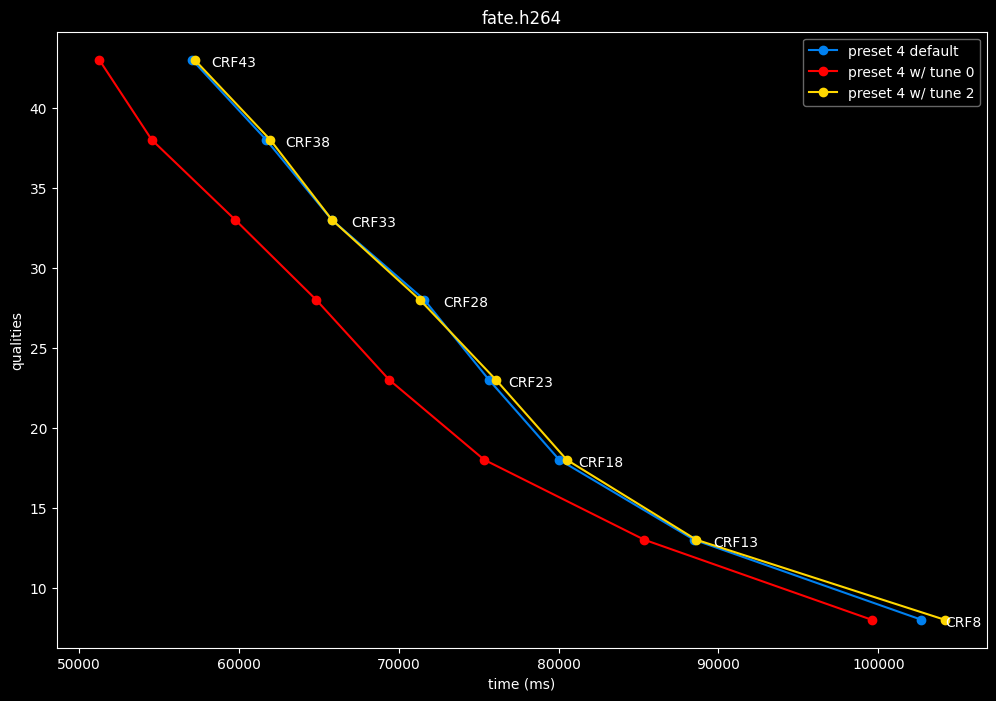
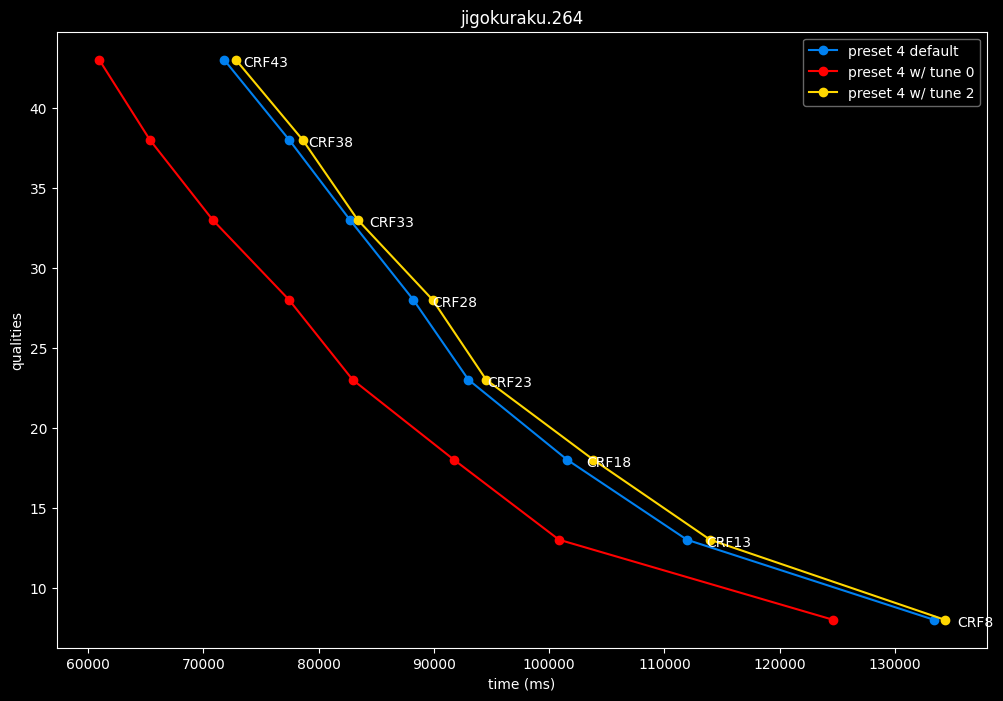
- Graphs comparing the tunes individually between each others will be made available soon.
- The image comparisons will make the conclusion quite more nuanced, stay tuned (heheh) for that.
TLDR
SSIMU2 favors tune 1 and 2 above tune 0. At high quality, tune 1 and 2 are matched, while at low quality tune 2 takes the edge. Tune 0 is sometimes a match for the other two on certain clips and other times fare pretty badly. For some reason, tune 0 is quite a bit faster now, compared to 1 and 2 which are basically the same.
Keep in mind that I have observed multiple times in the past that tune 0 kept more fine detail and was sharper than the other tunes, at the expense of potential artifacting, like ringing and distortion. It may very well explain why the metric doesn't like its results. The image comparisons may give a different interpretation than what we concluded here, please stay tuned for these subjective comparisons.
Parameters comparisons
In the following graphs, you may find comparisons between many SVT-AV1 parameters. Additional graphs focusing on the high and low qualities will be made available later down the line
--preset 4 is used here due to its good balance of quality and speed, in conjunction with the CRF values. That means everything else is default. The defaults have been mentioned earlier above.
--tile-rows 1 --tile-columns 1 vs default --tile-rows 0 --tile-columns 0
- Efficiency graphs:
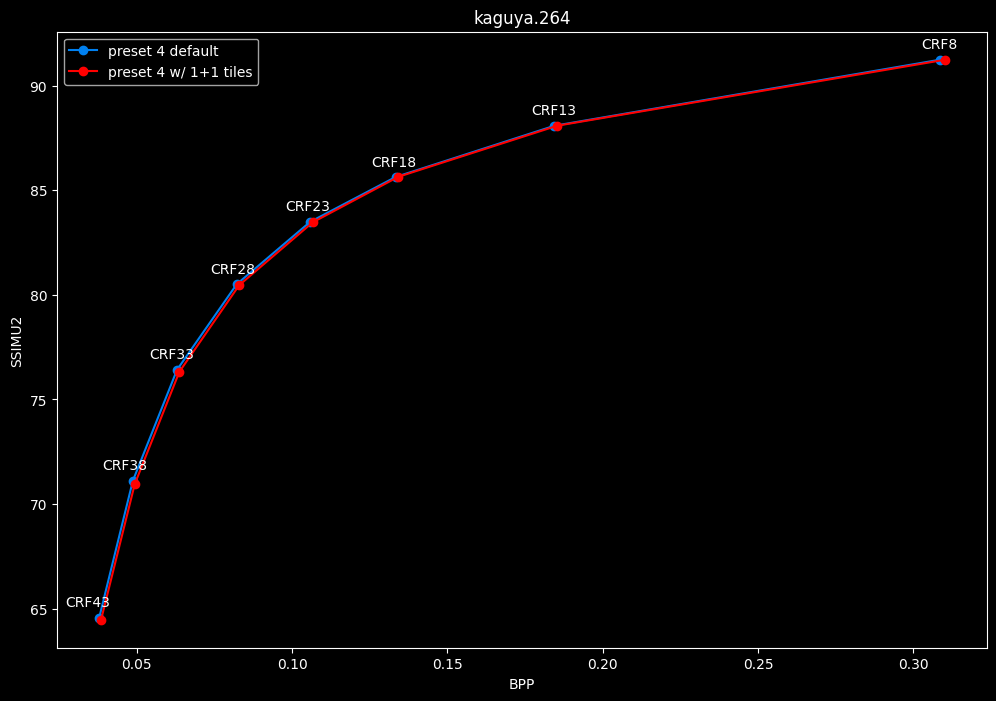
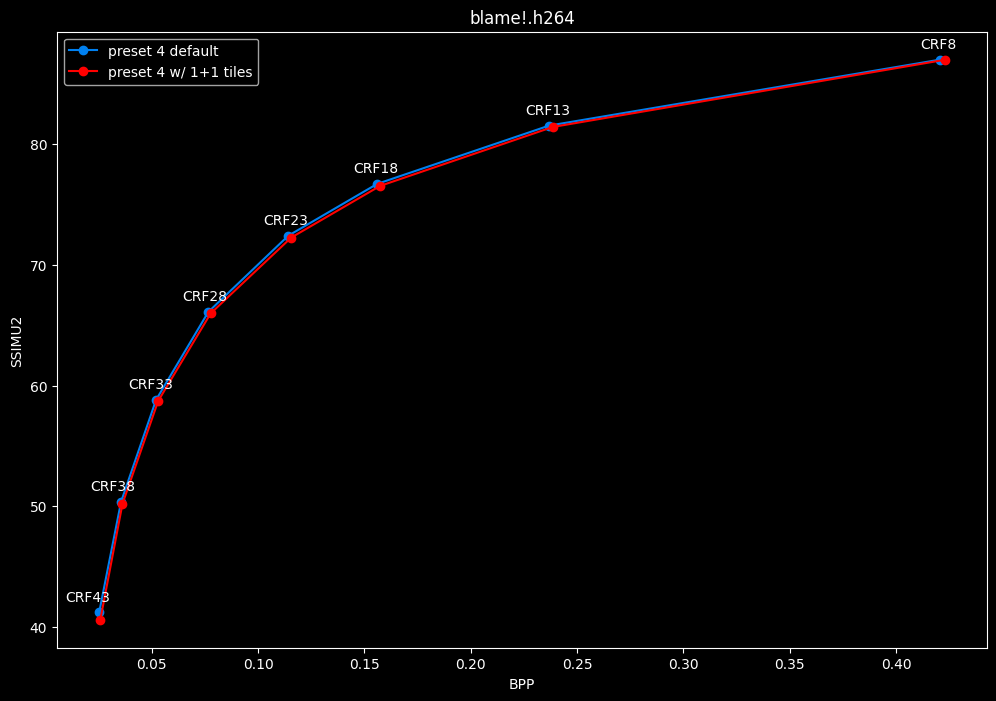
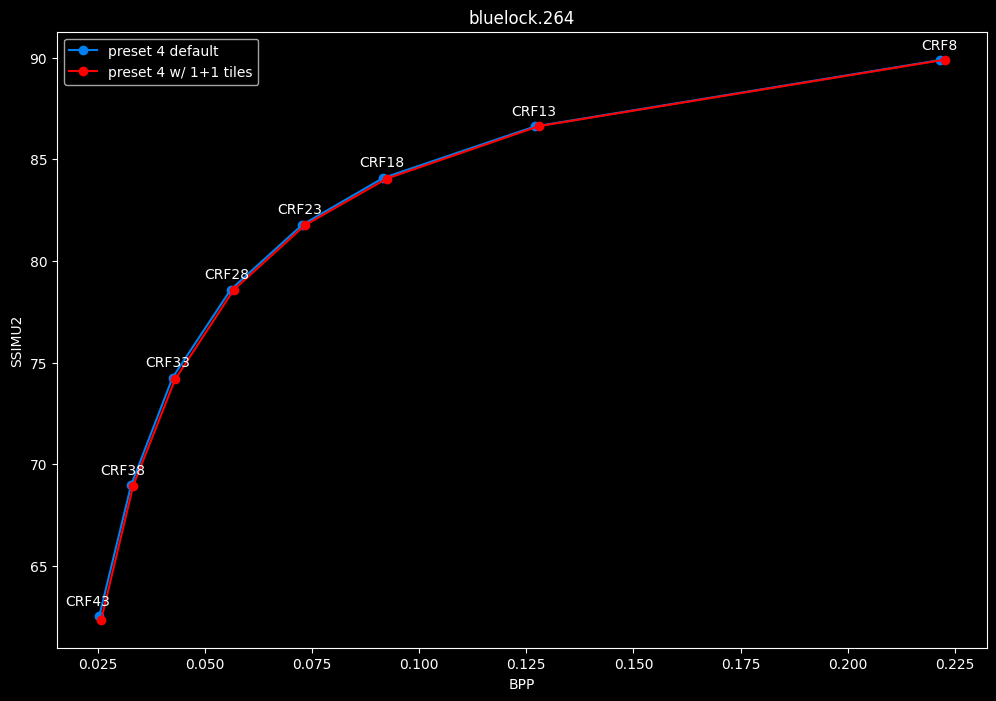
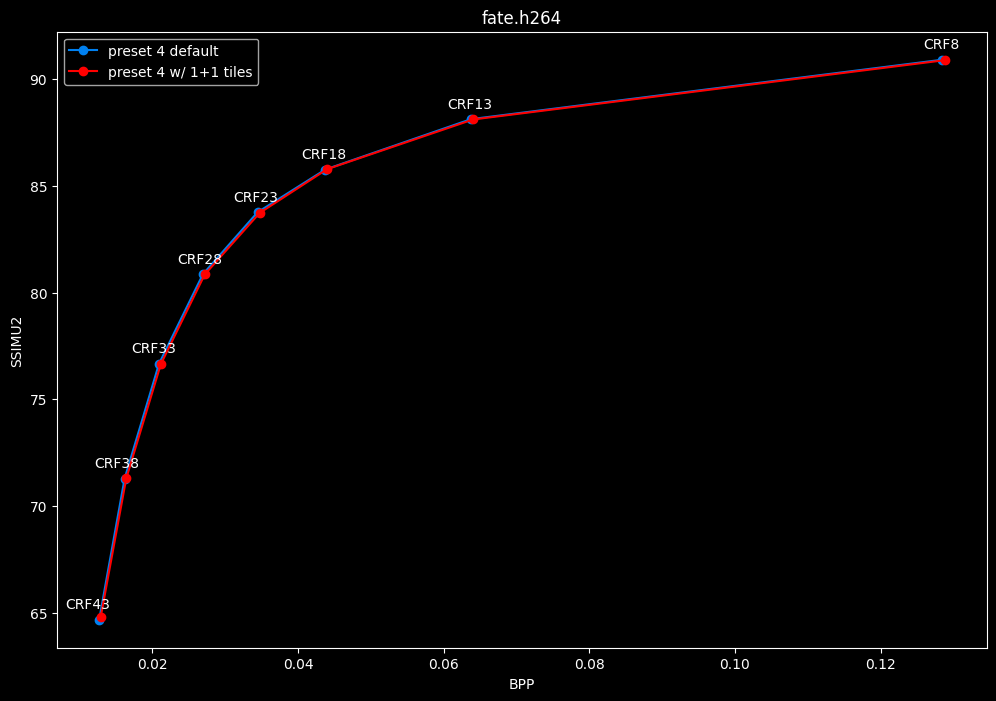
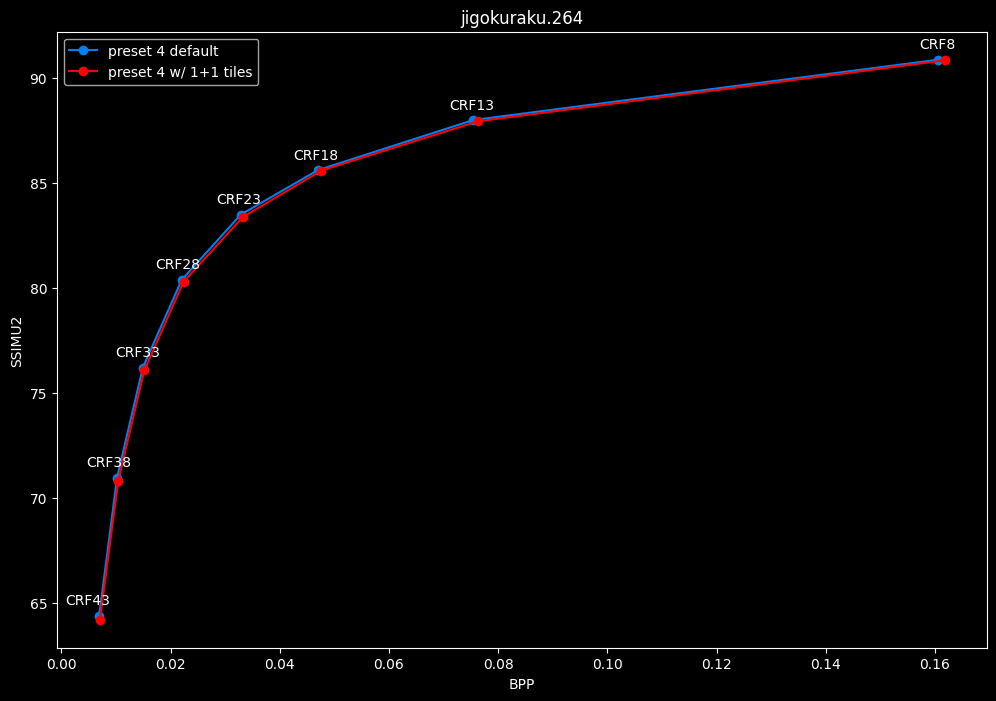
- Speed graphs:
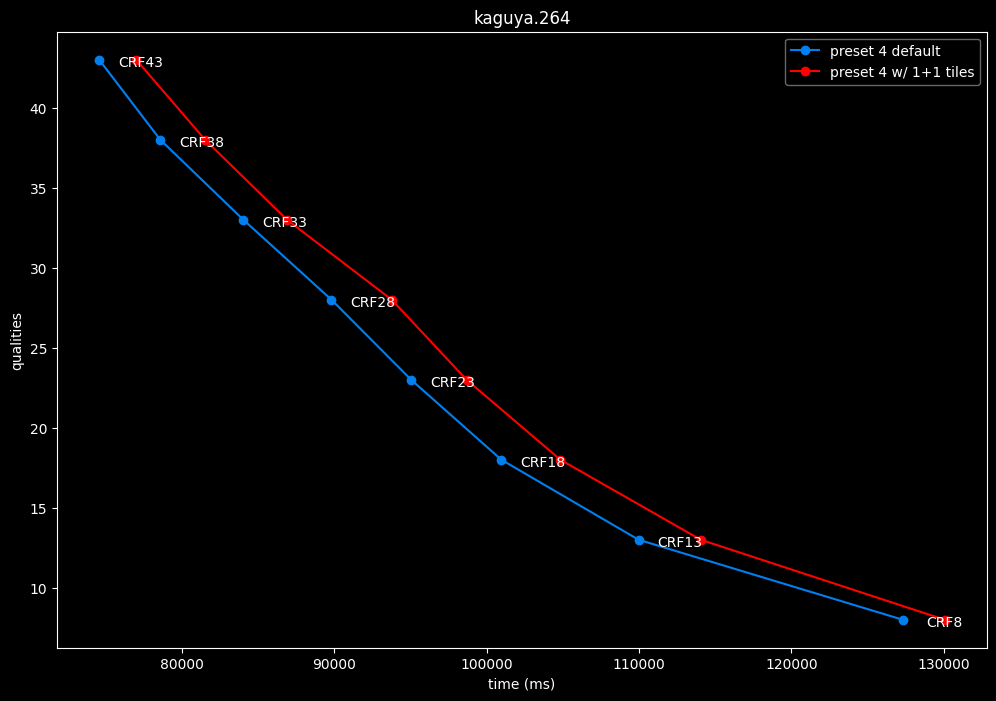
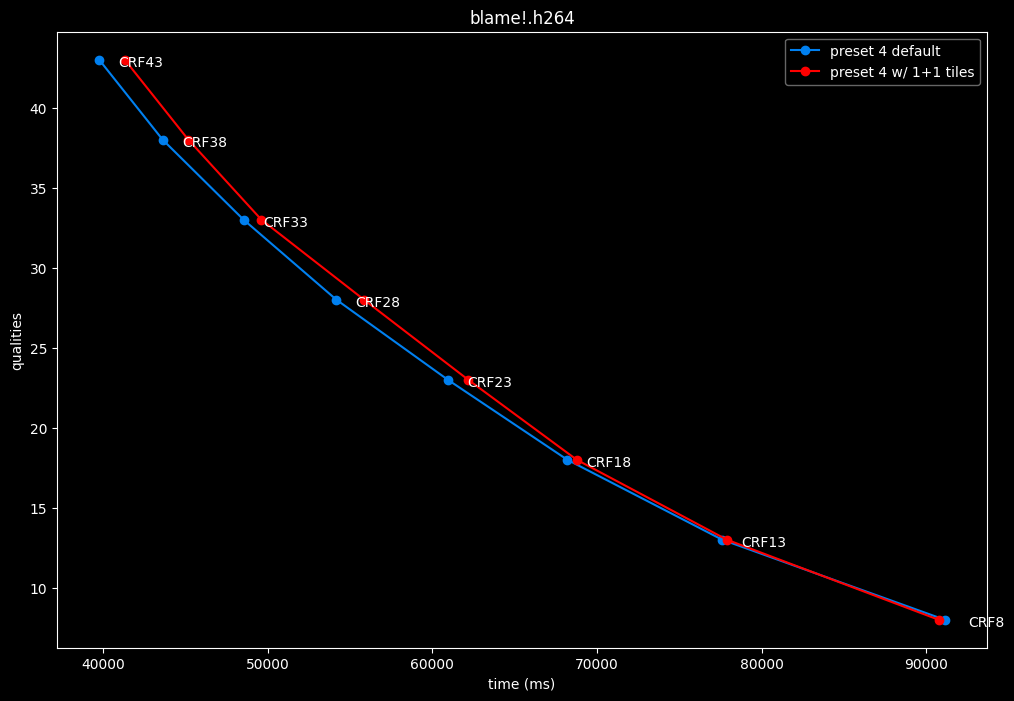
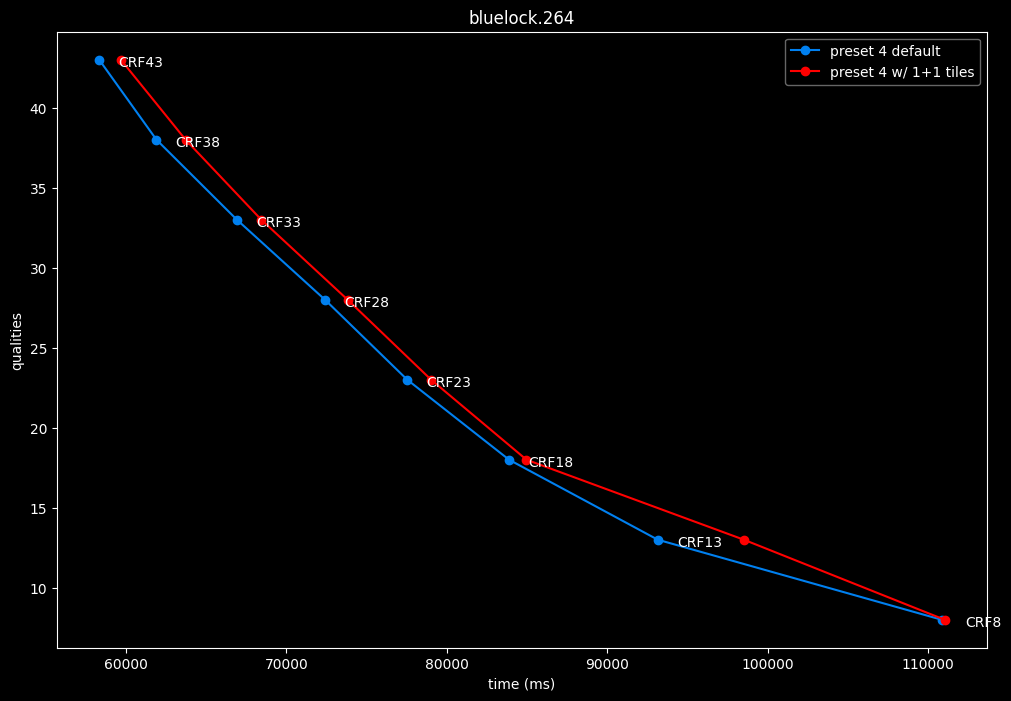
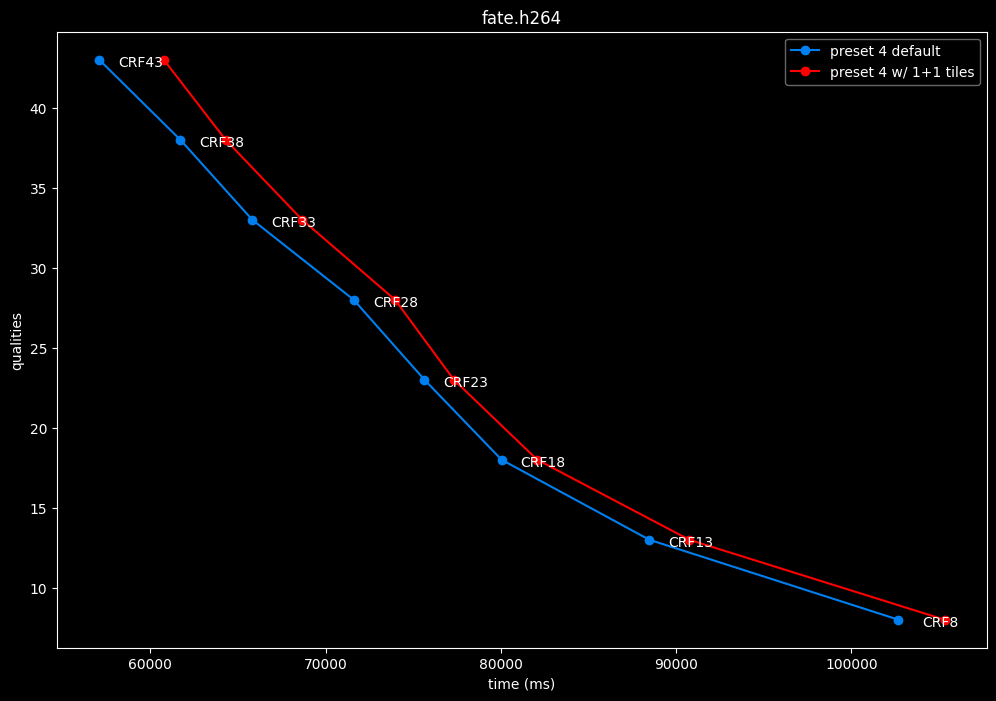
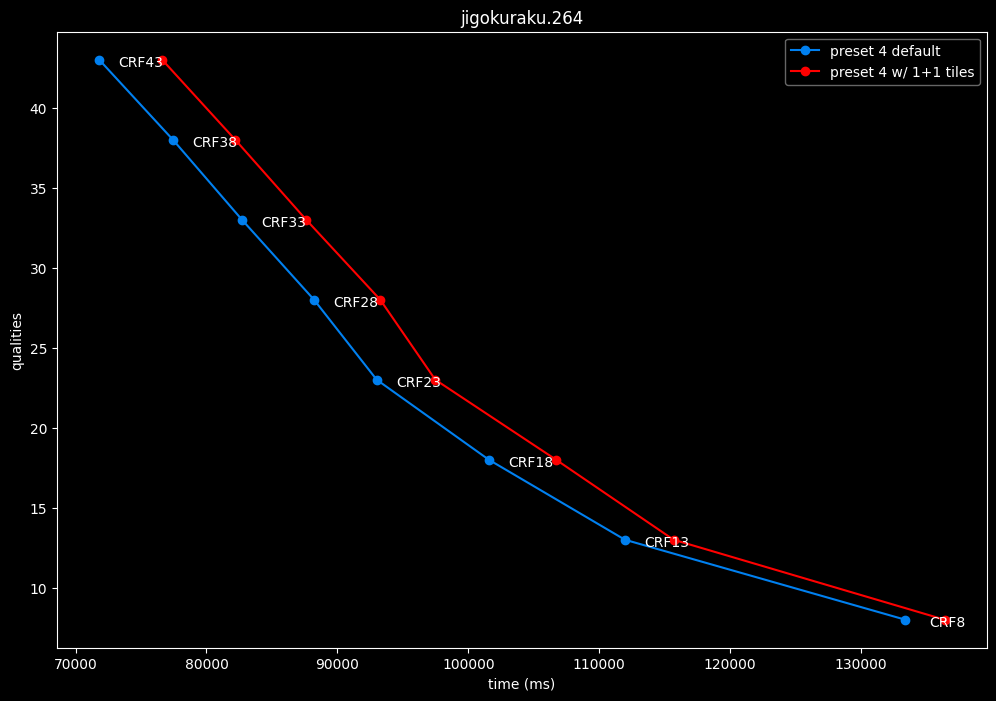
tiles here are both slightly harmful and slower.
--aq-mode 0 vs default --aq-mode 2
- Efficiency graphs:
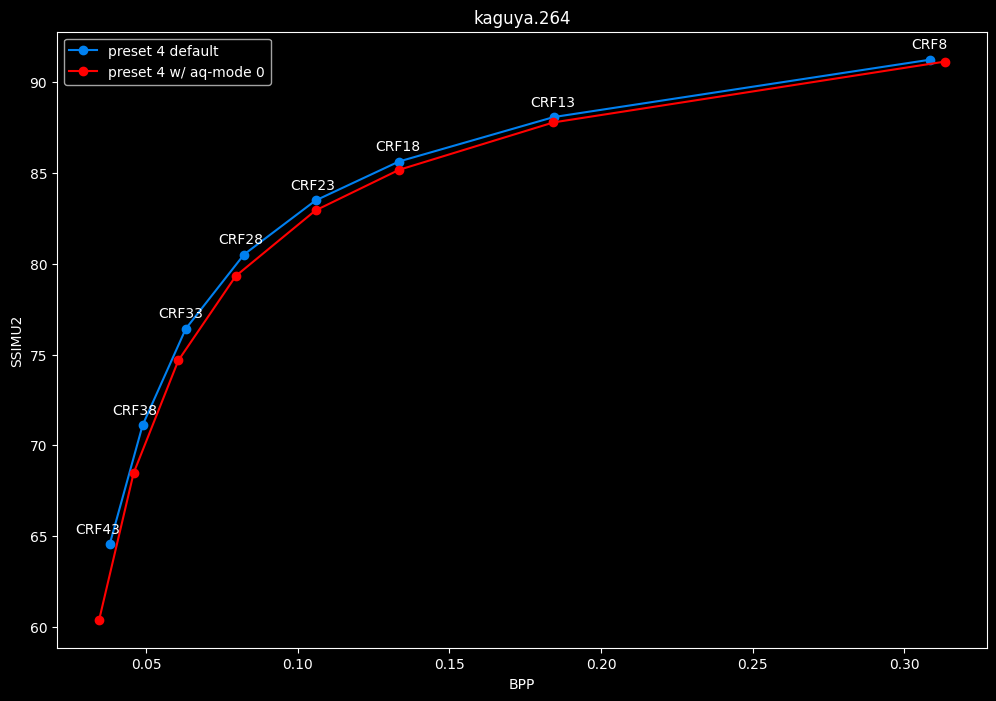
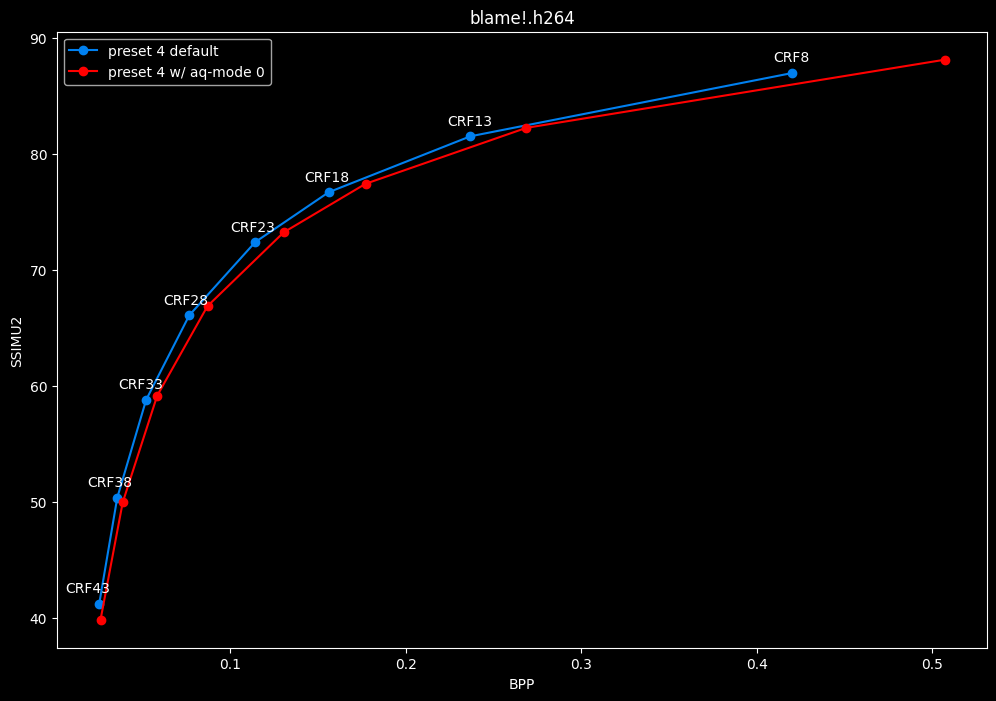
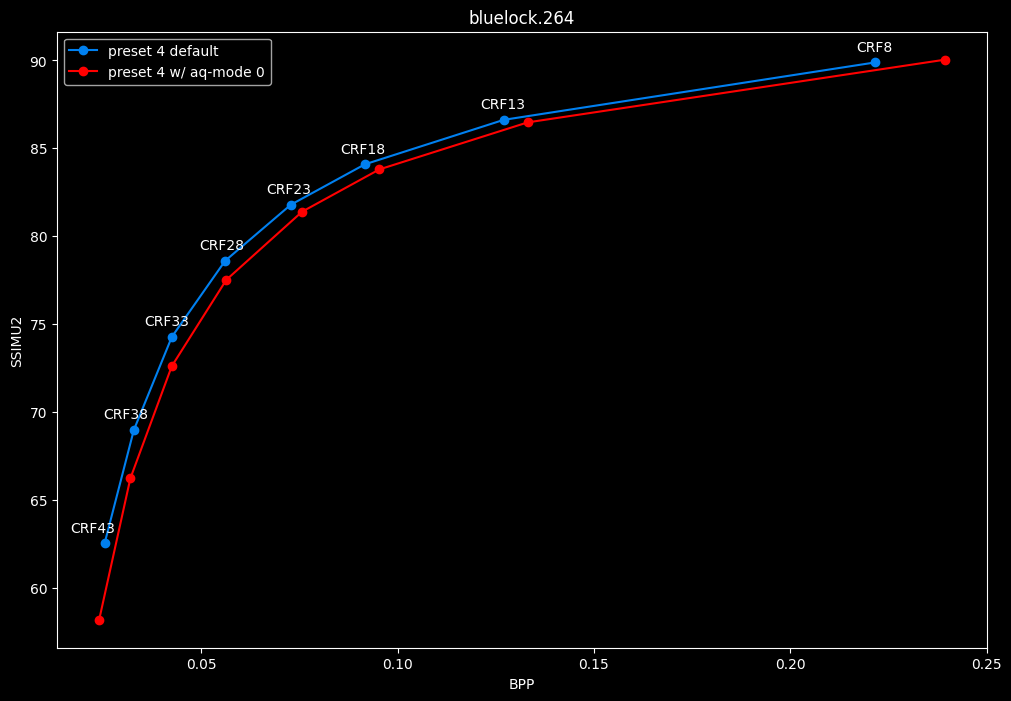
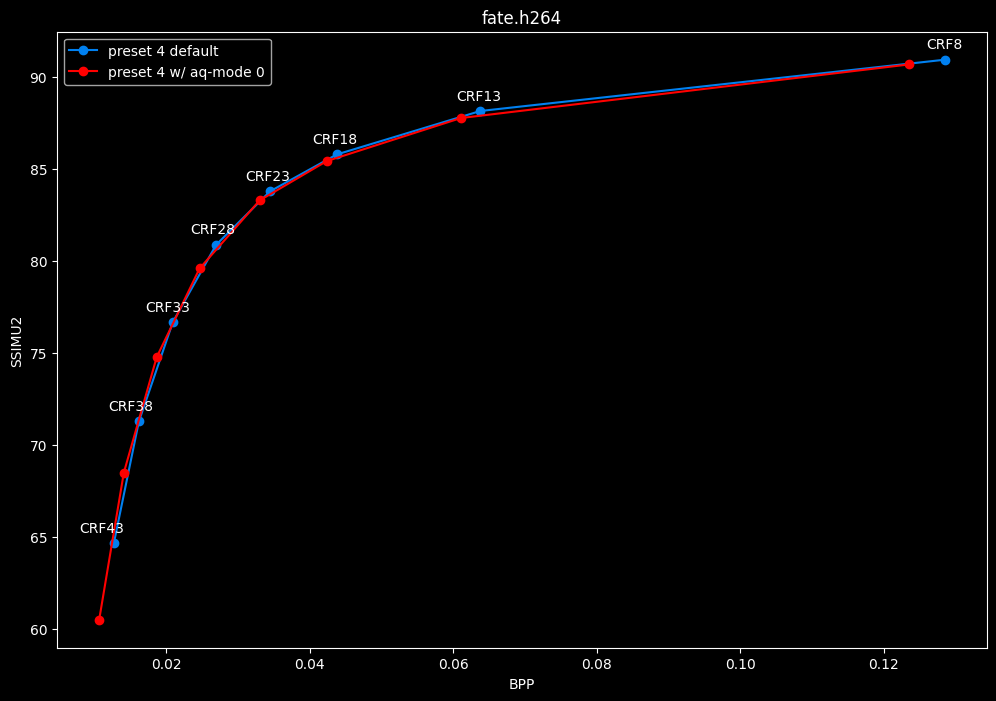

- Speed graphs:
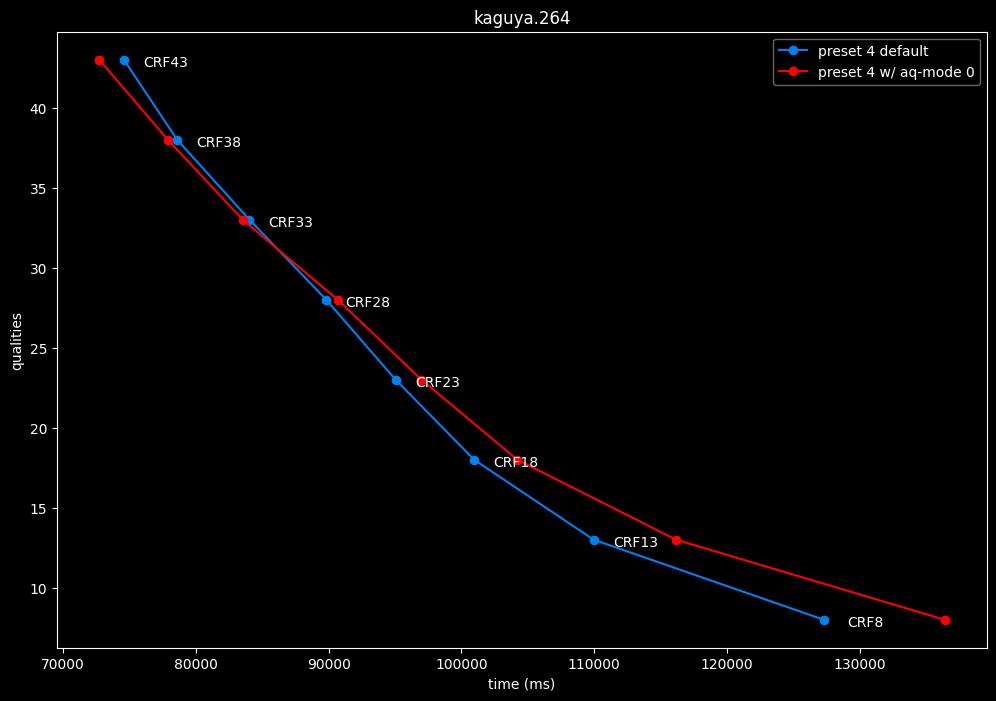
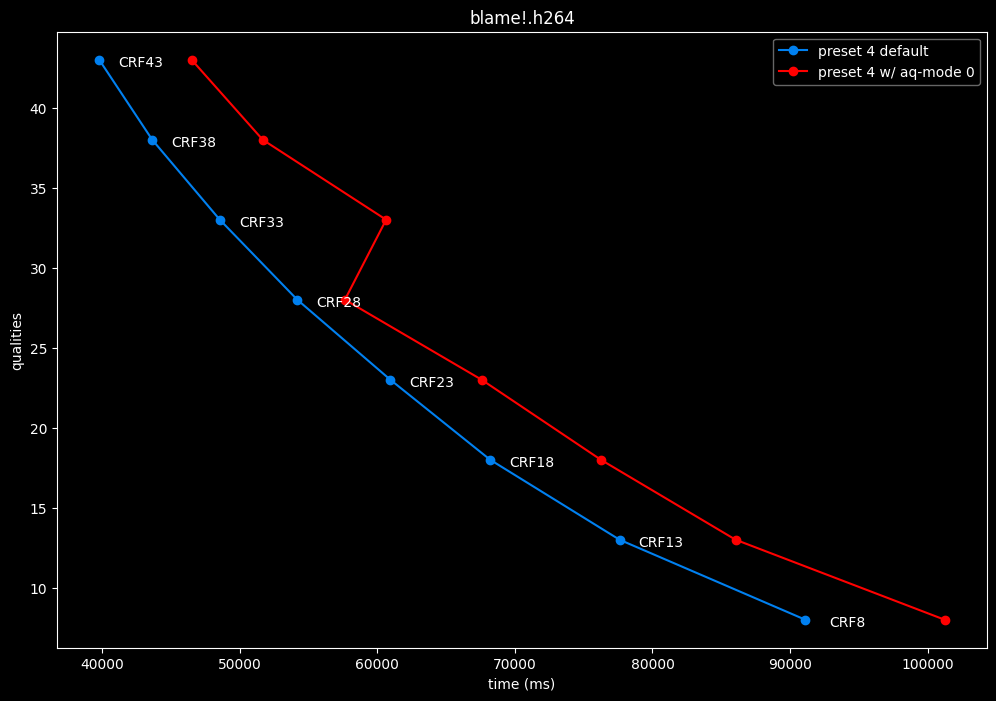
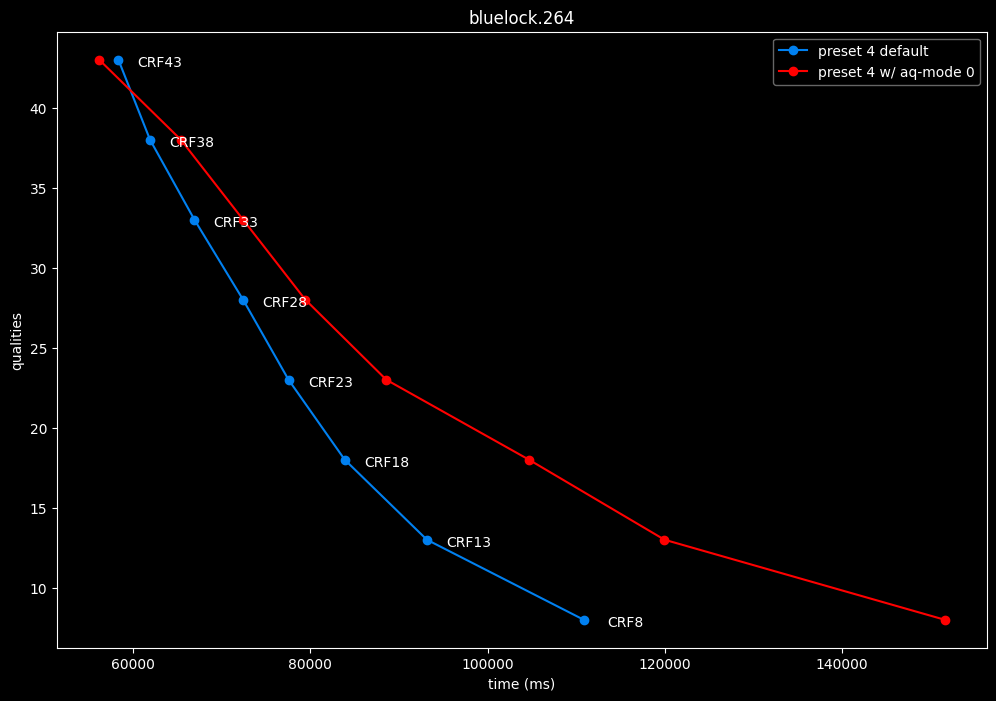
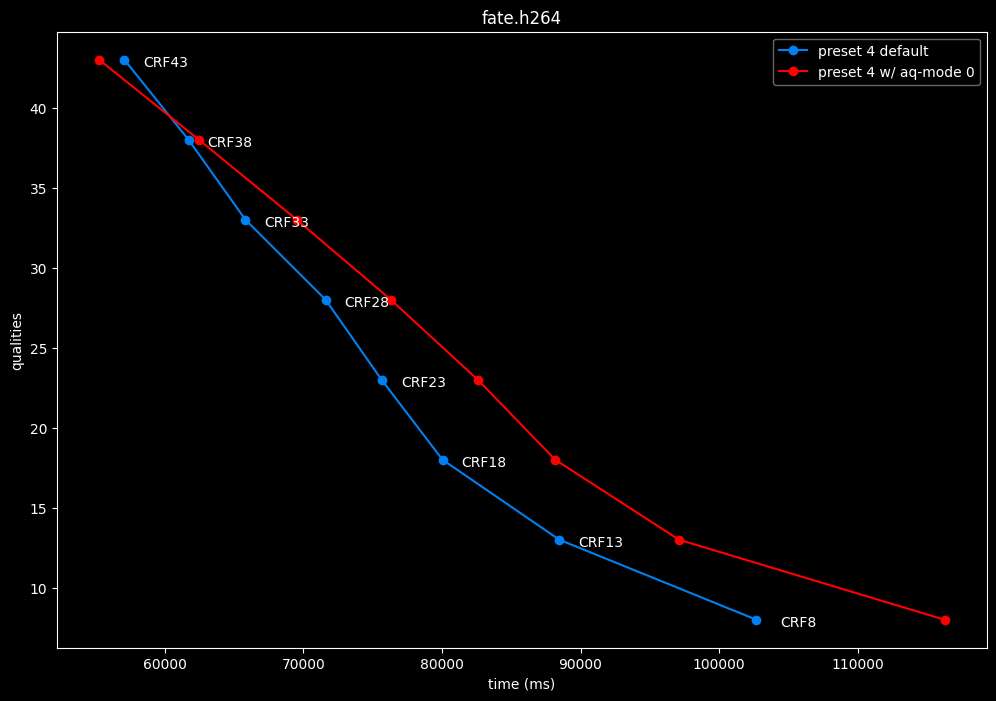
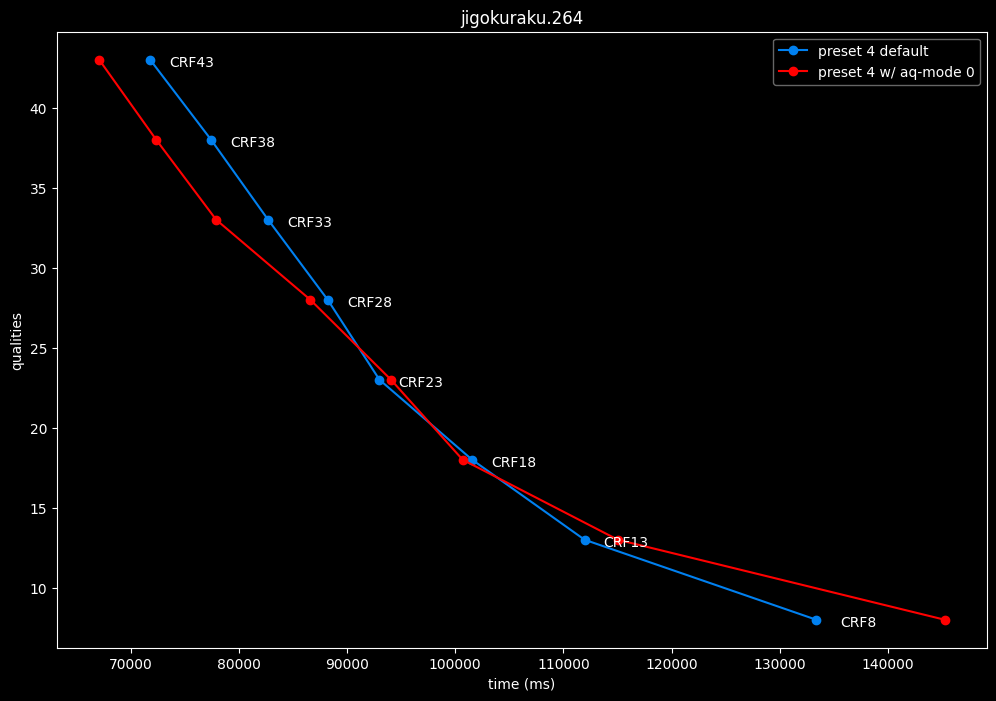
Except for the Jigokuraku clip, aq-mode 0 is harmful in the eyes of SSIMU2, while being slower at low CRF levels, and sometimes a match or faster at high CRF levels.
--aq-mode 1 vs default --aq-mode 2
- Efficiency graphs:
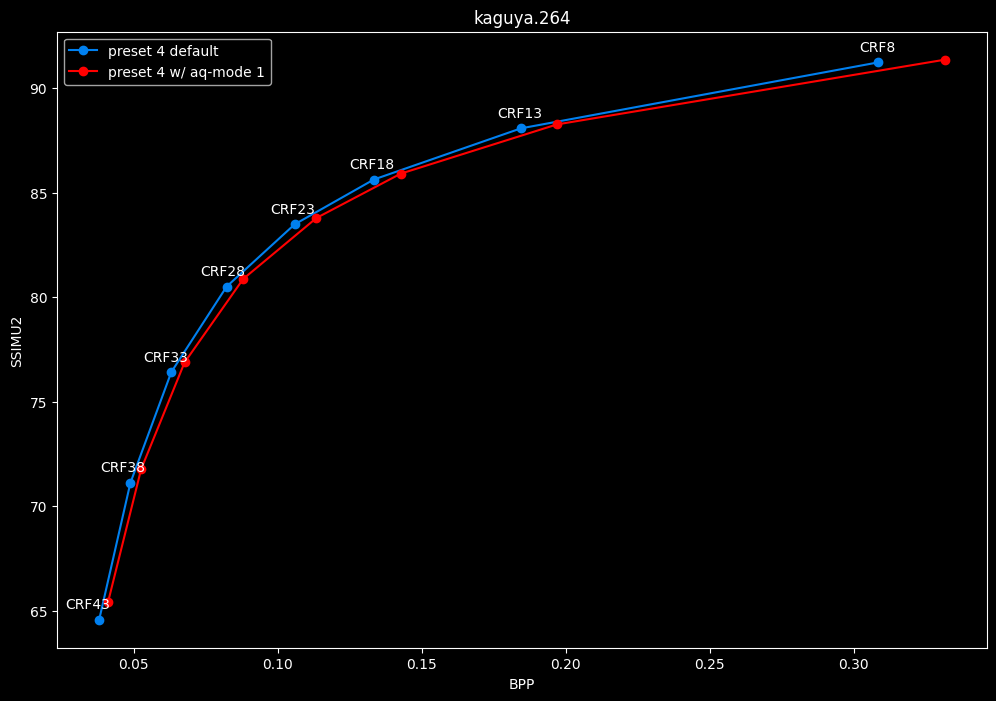
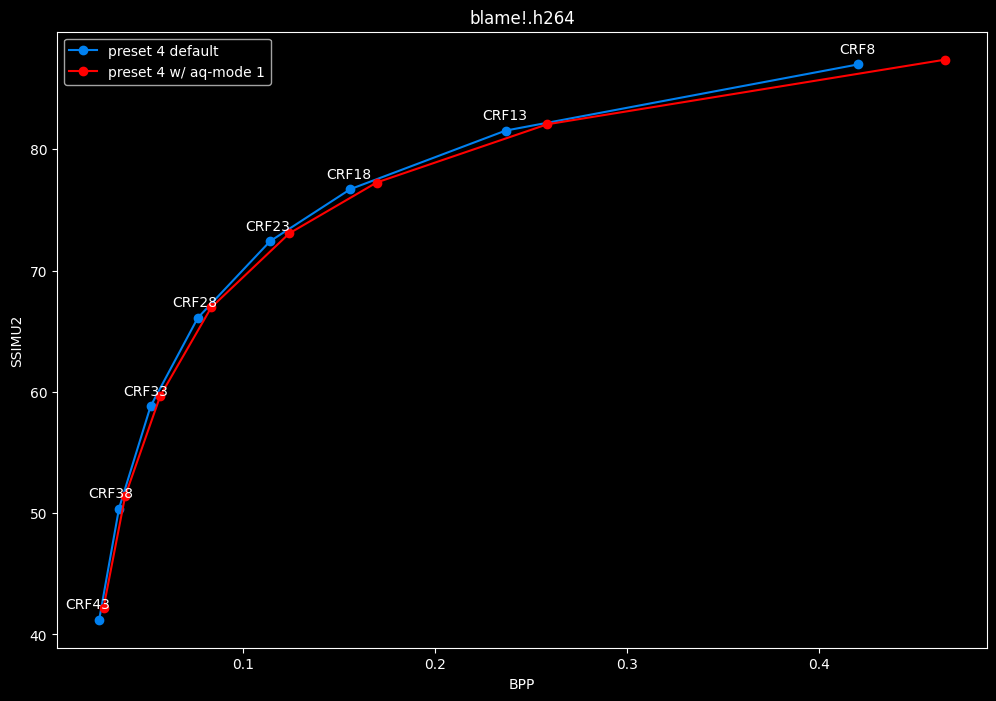
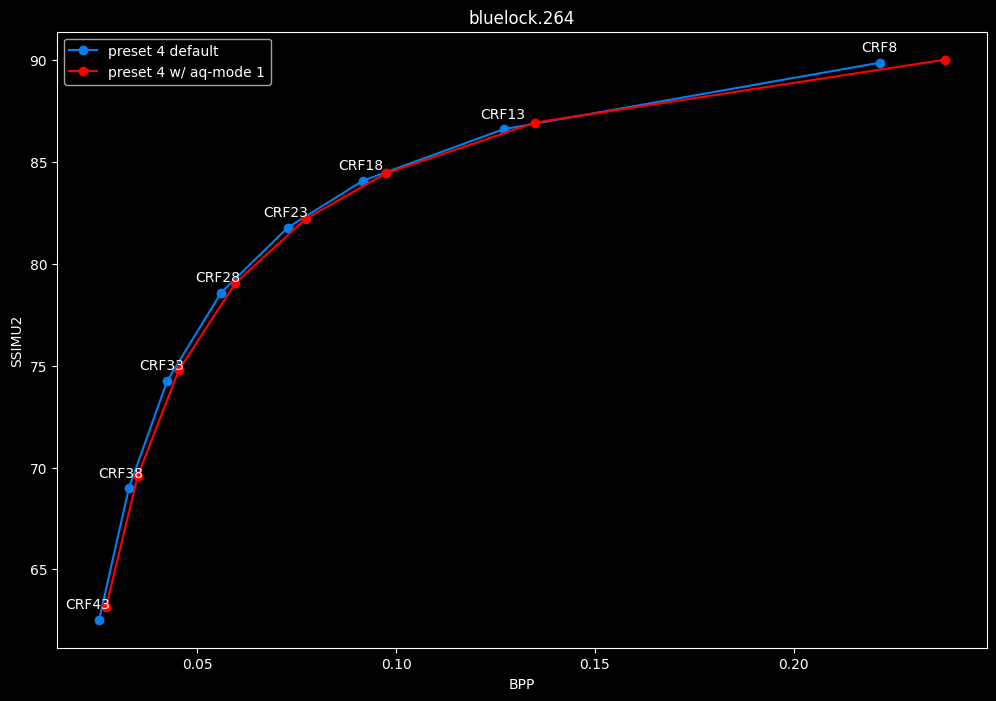
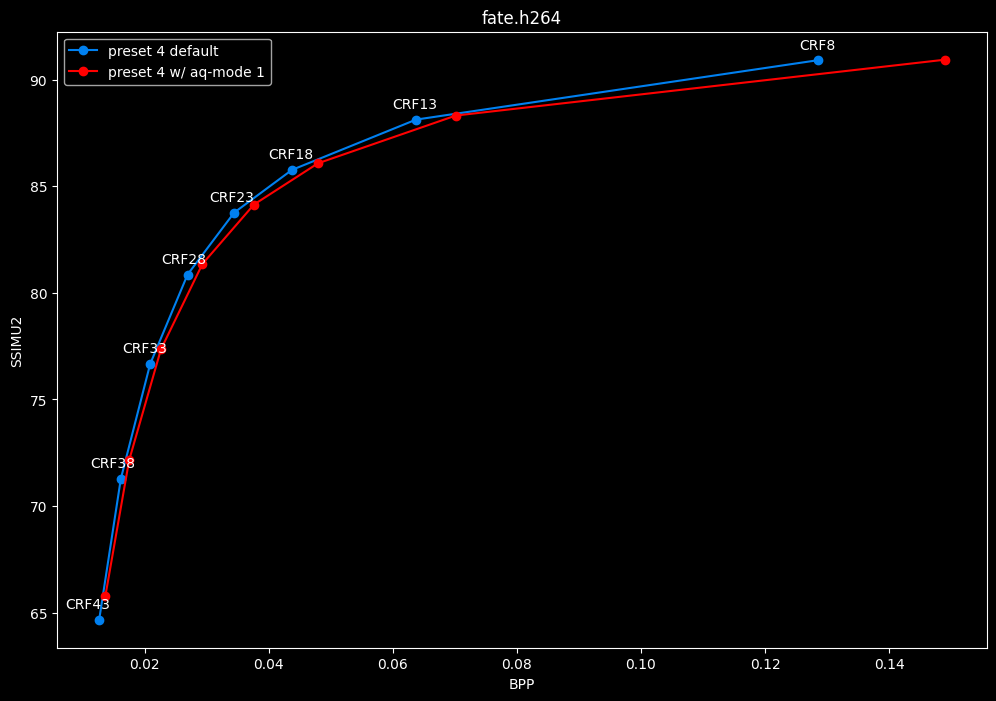
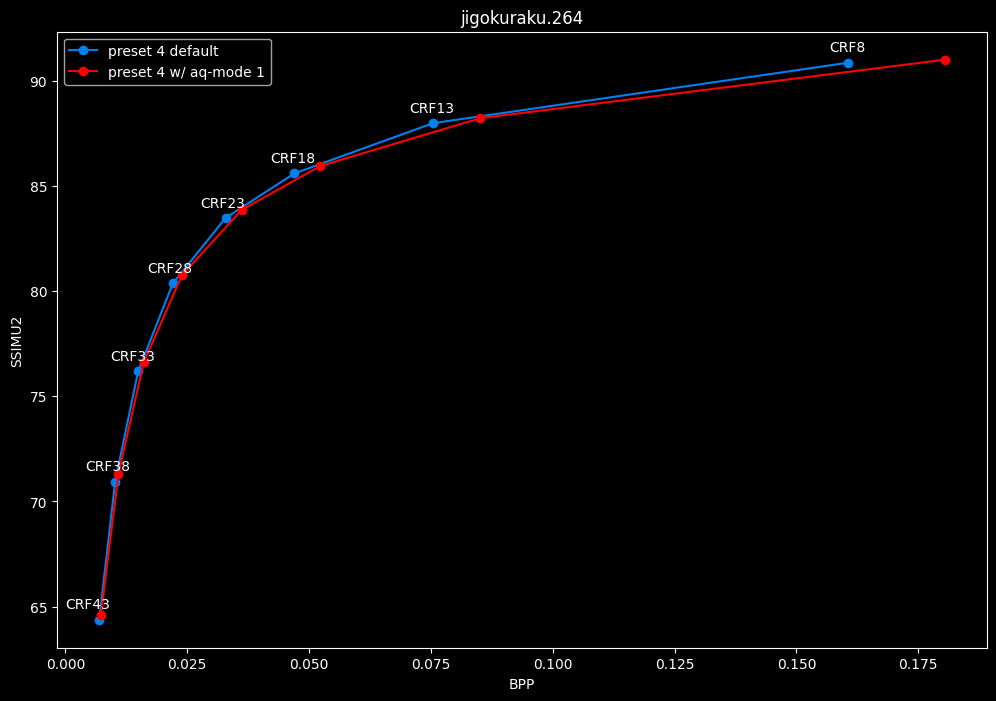
- Speed graphs:
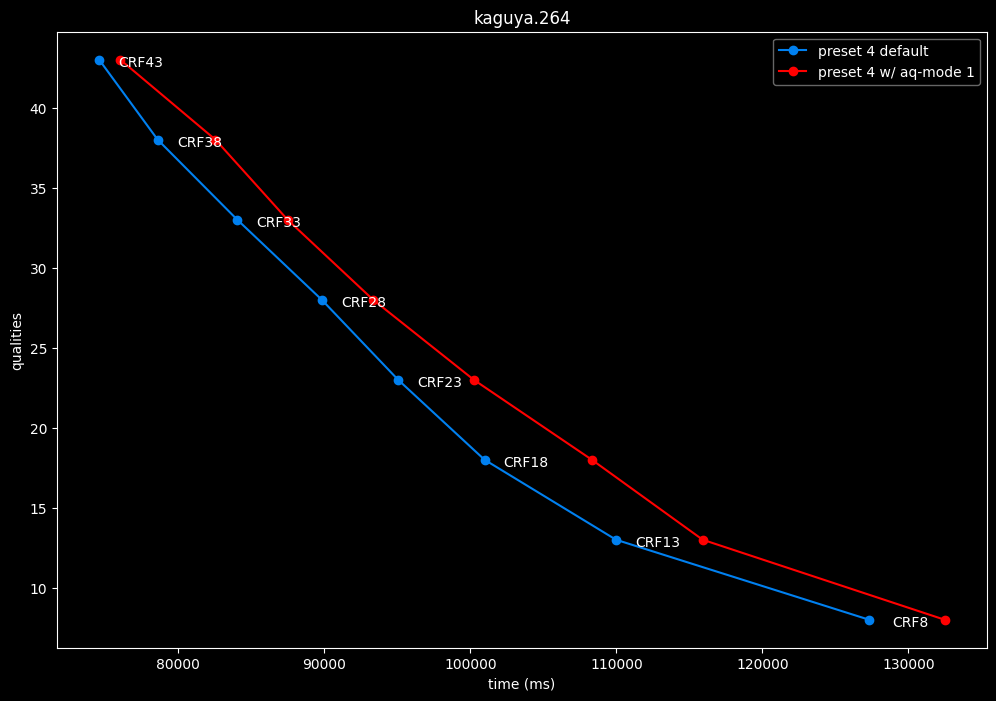
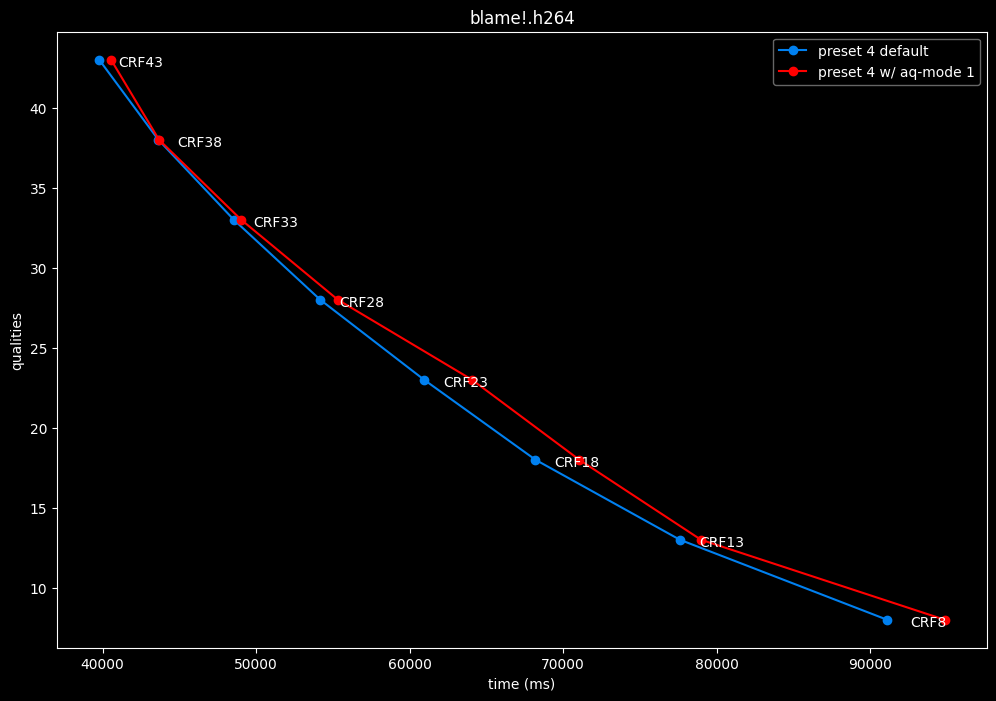
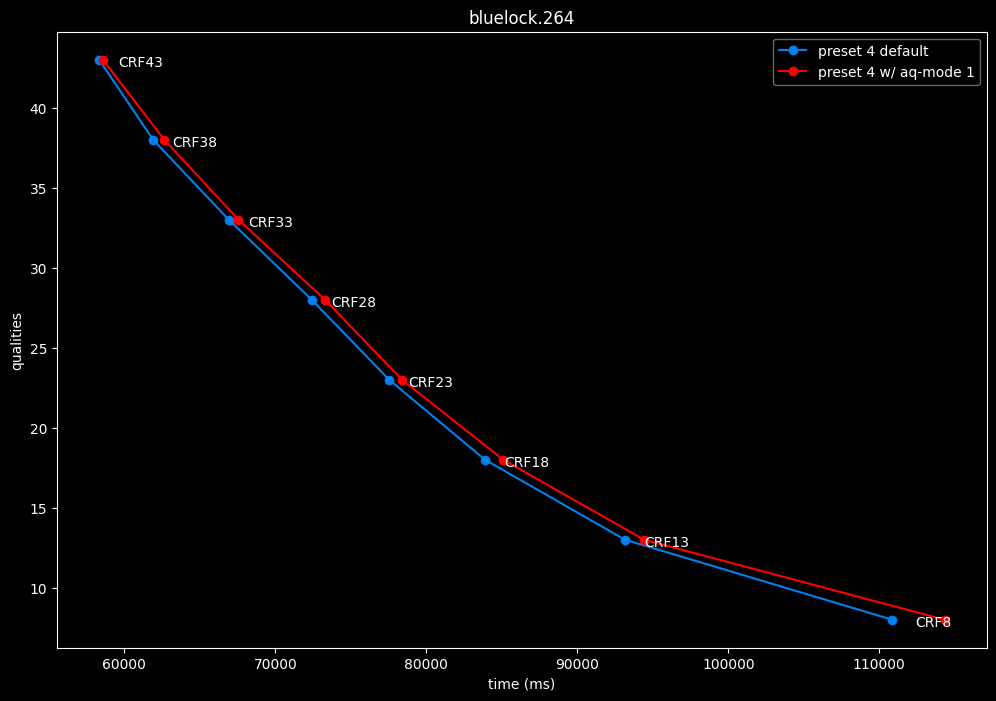
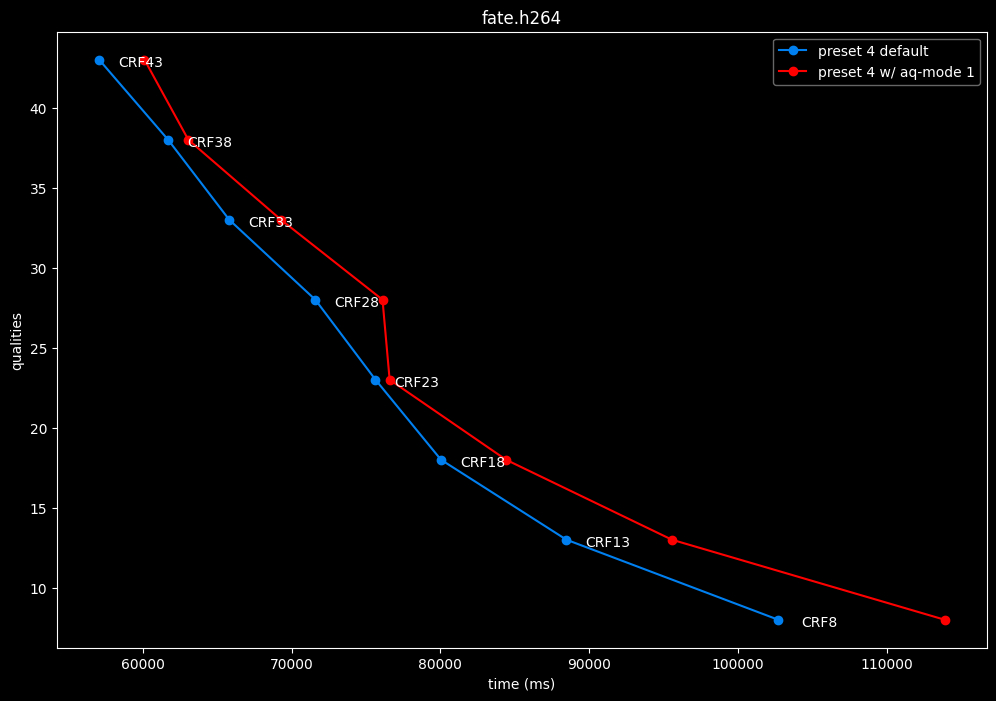
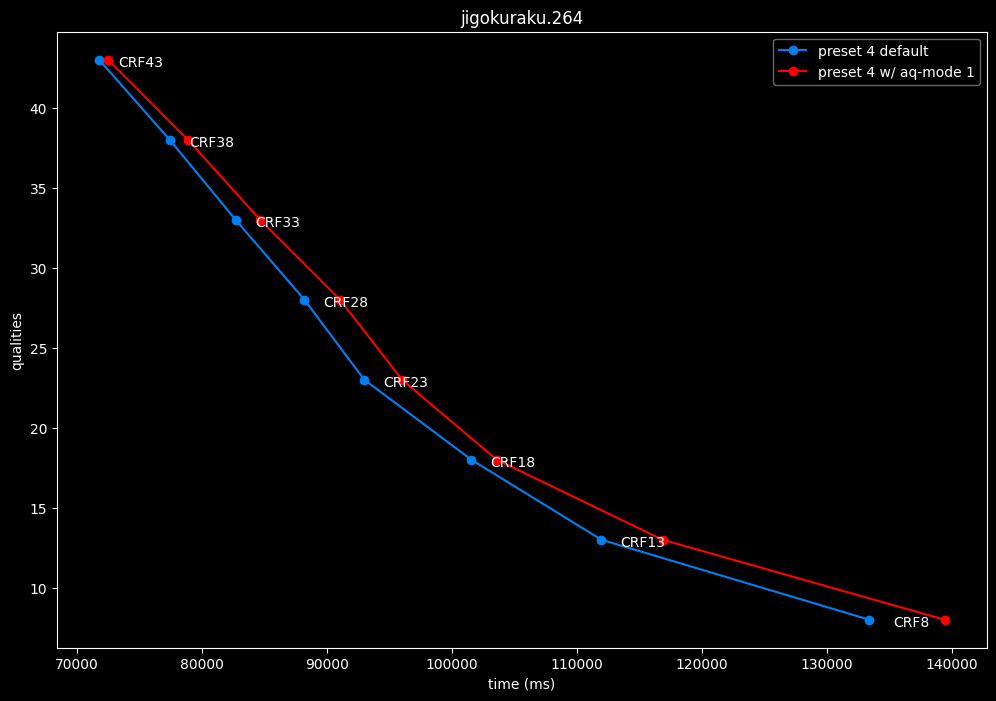
aq-mode 1 fares closer to aq-mode 2 than aq-mode 0 did, both in quality and speed, but is still overall inferior according to SSIMU2
--enable-cdef 0 vs default --enable-cdef 1
- Efficiency graphs:
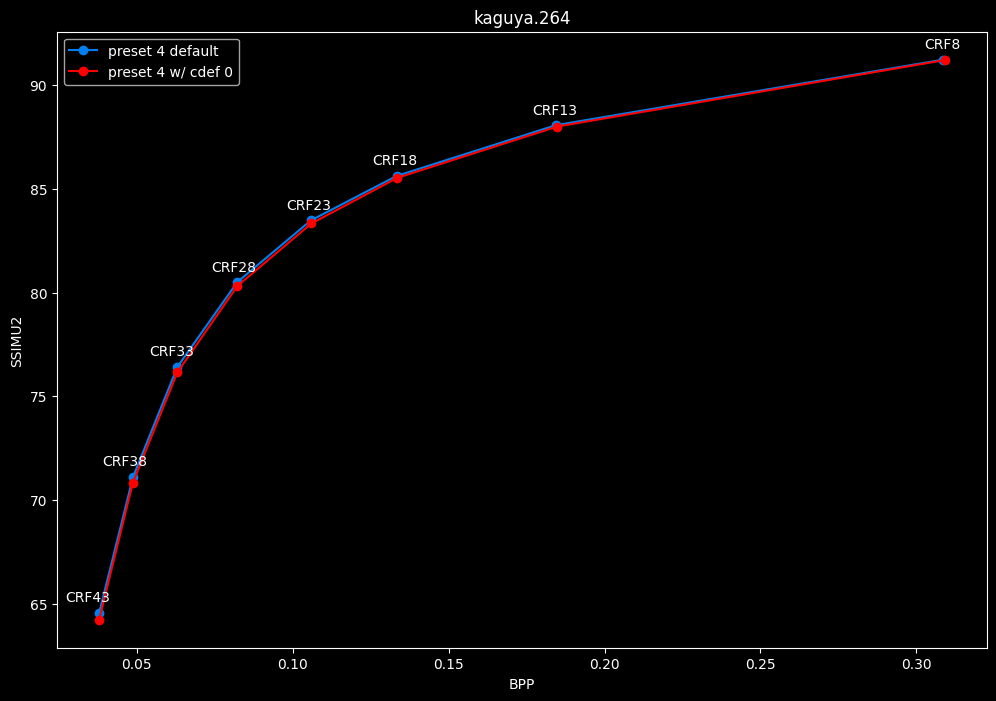
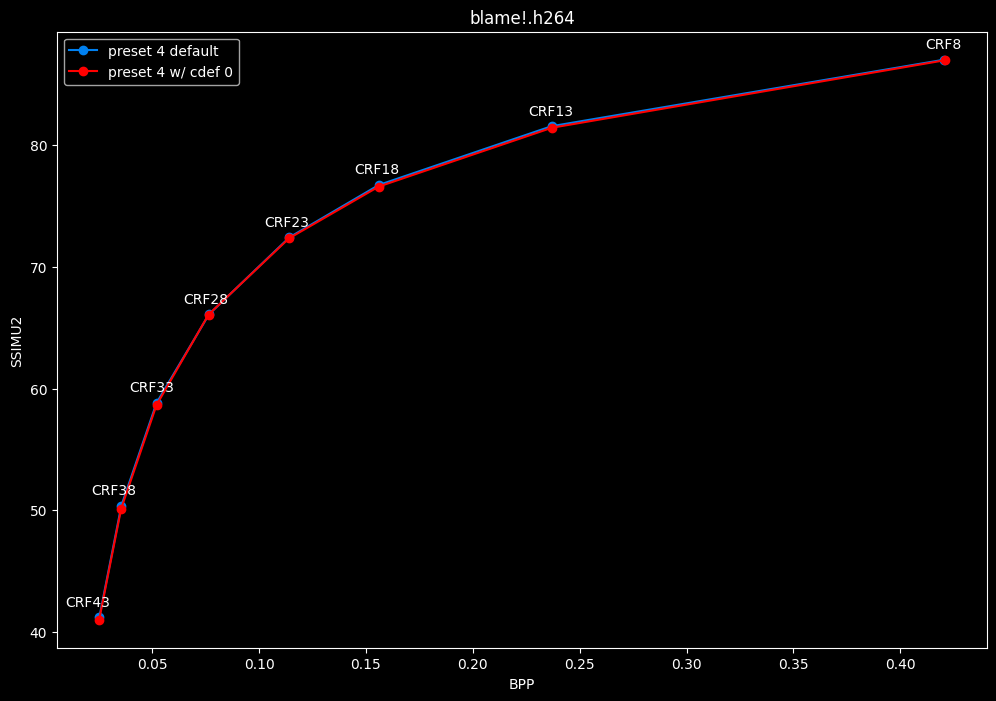
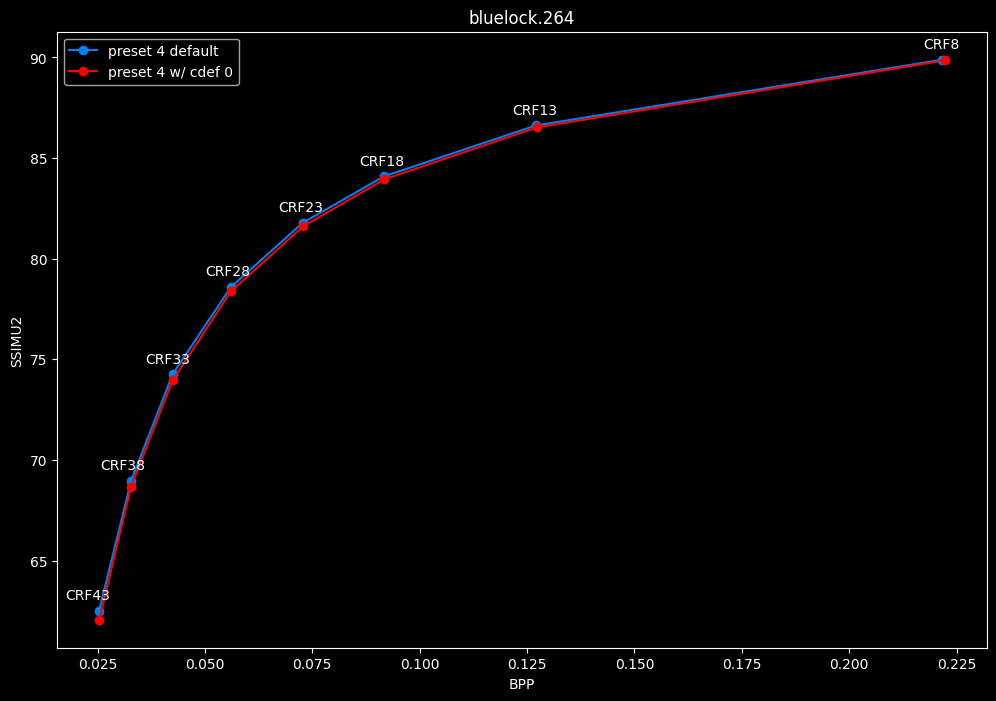
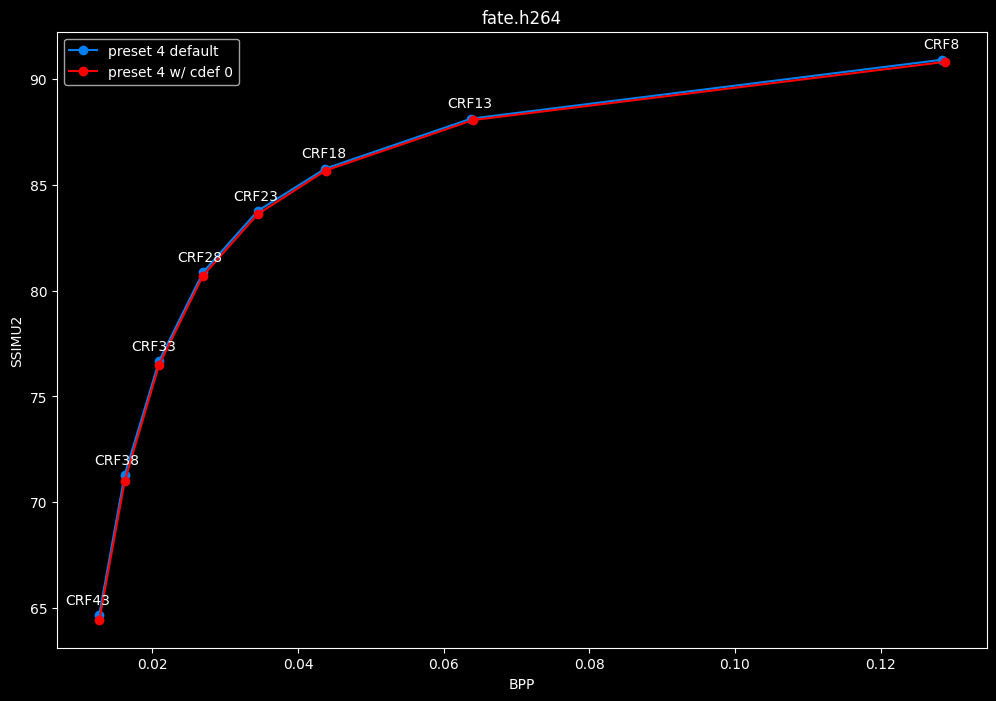
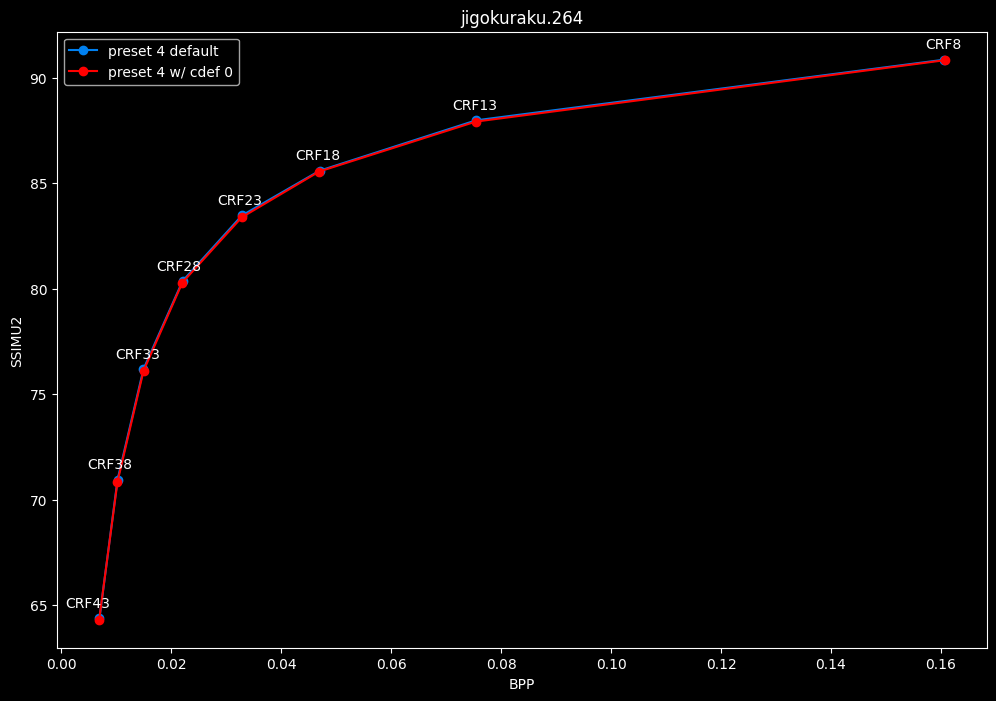
- Speed graphs:
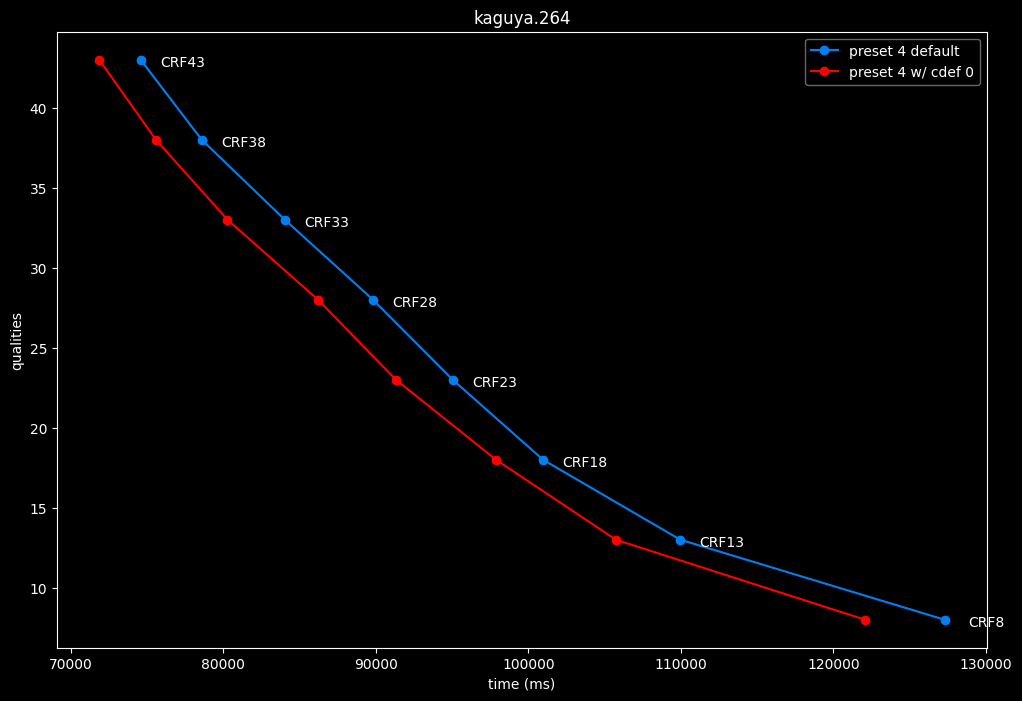
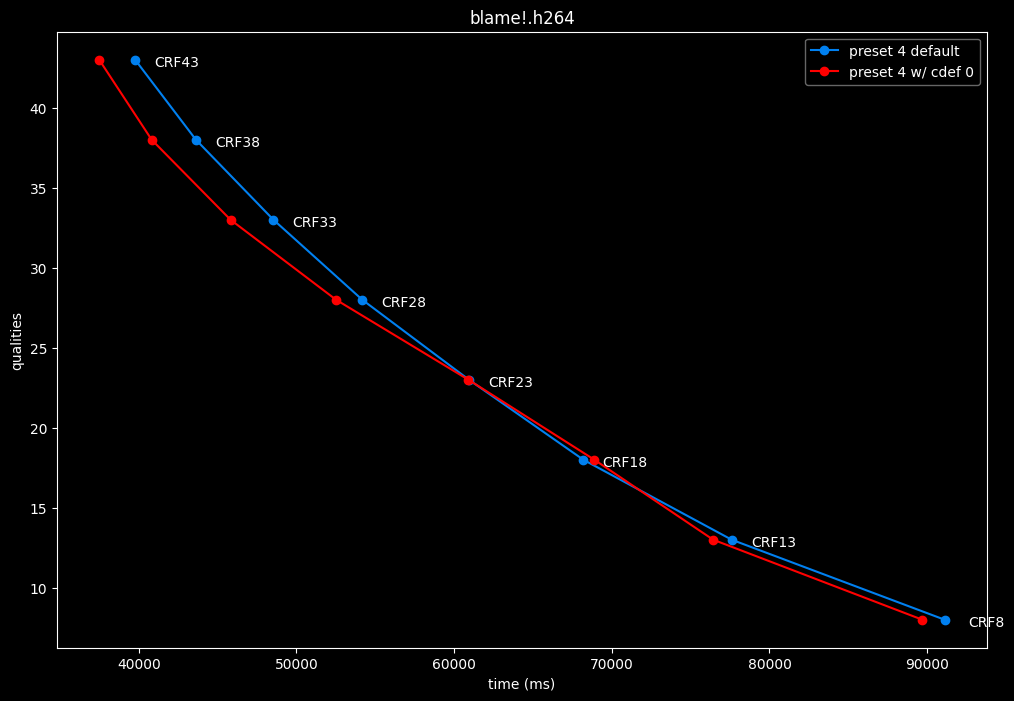

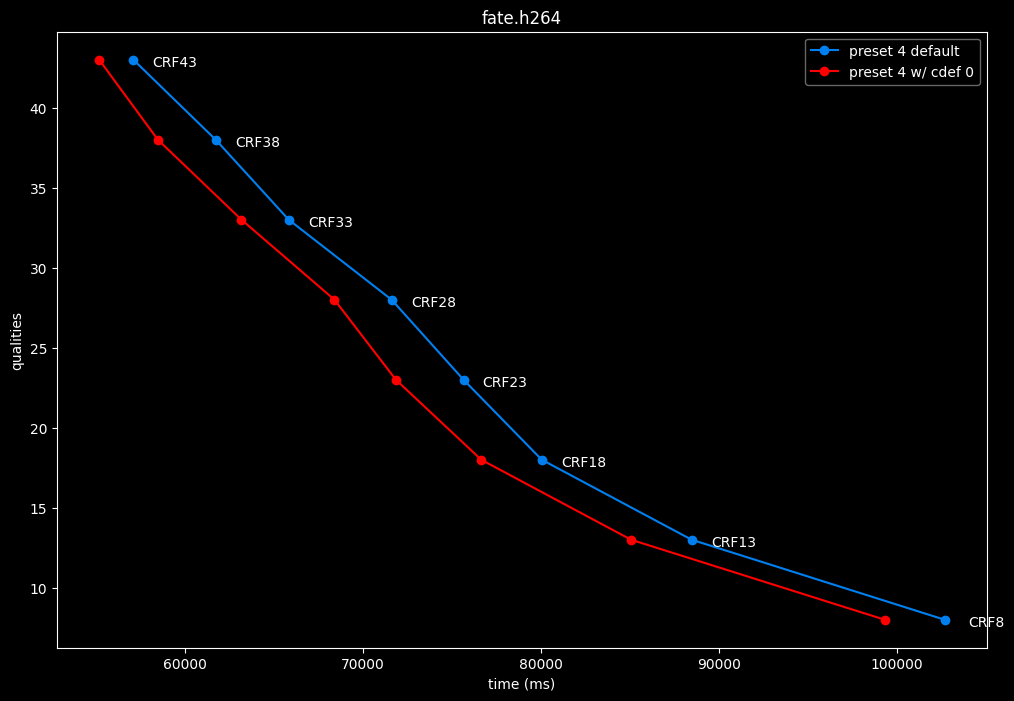
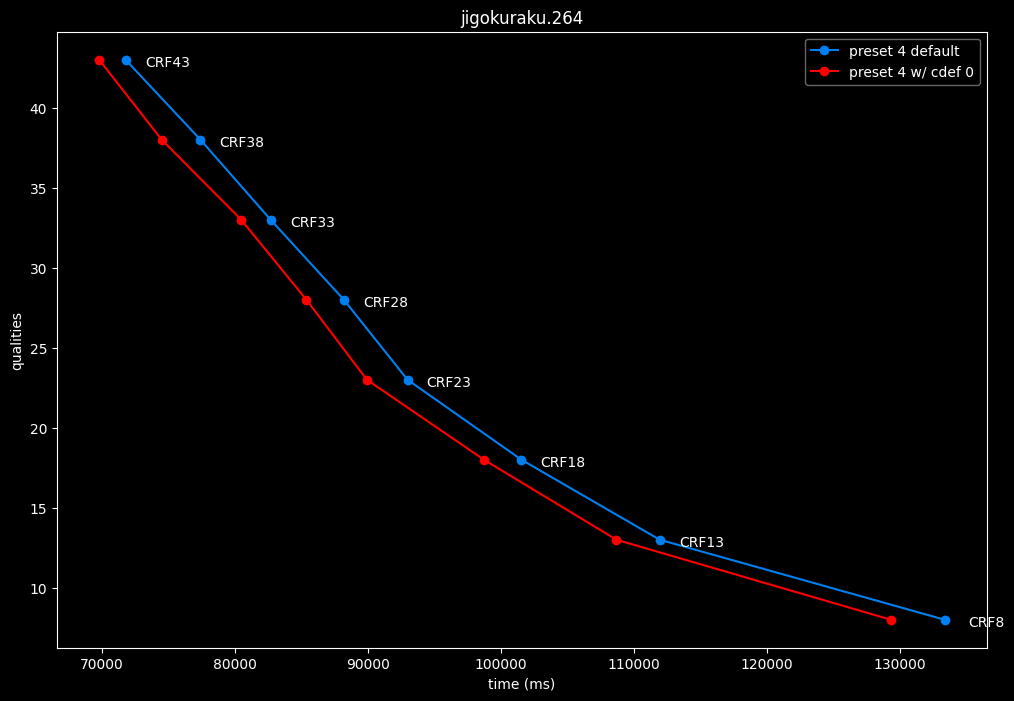
According to SSIMU2, disabling CDEF barely impact efficiency. But as its a pretty demanding tool, there's a slight speed benefit of having it disabled too. I advise you to take these results with a grain of salt until the image comparisons, because in anime particularly, CDEF can be beneficial for the line-art.
--enable-dg 0 vs default --enable-dg 1
- Efficiency graphs:
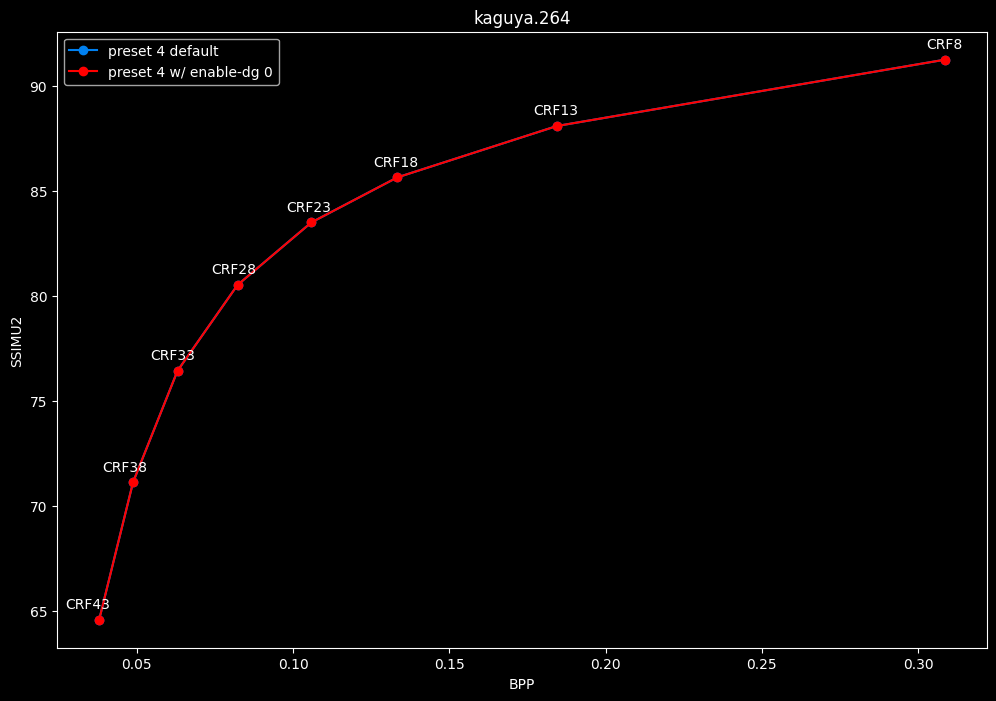
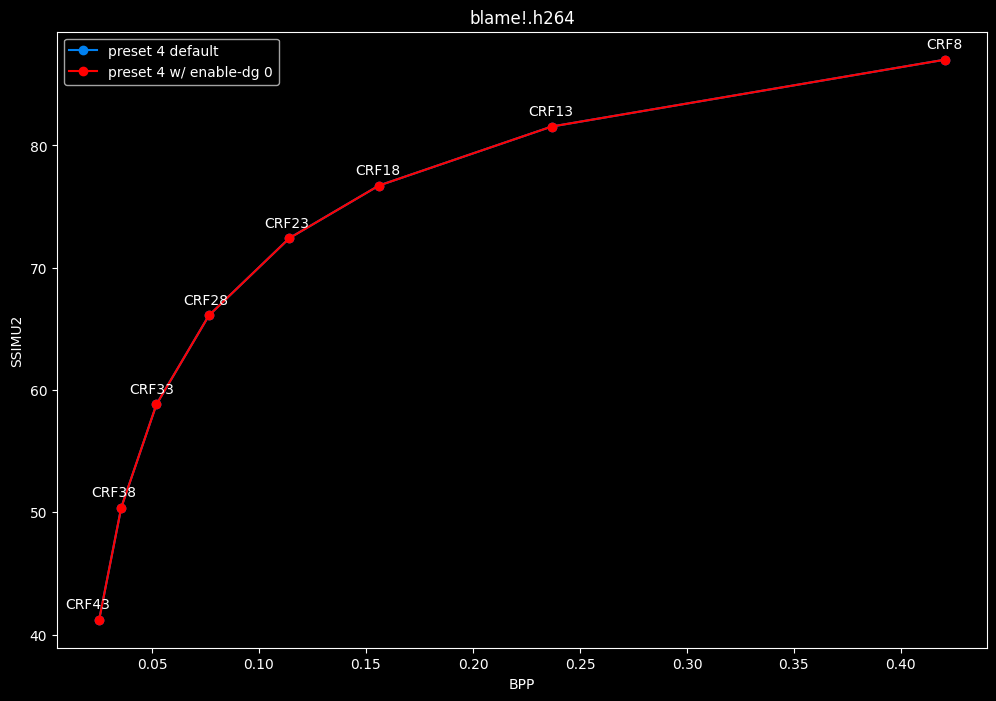
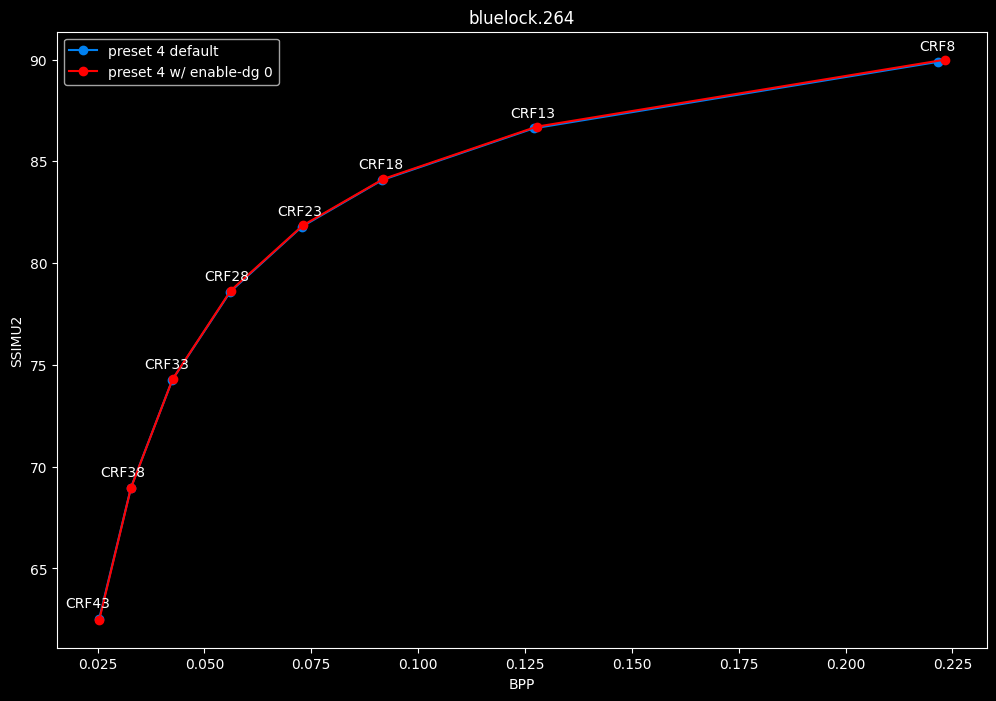
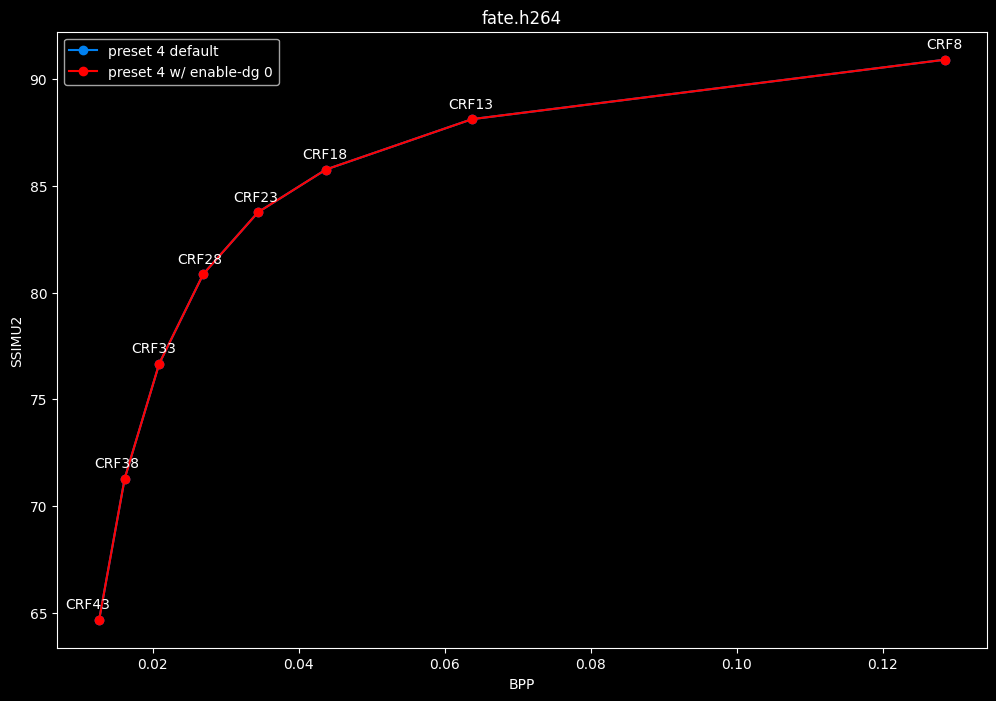
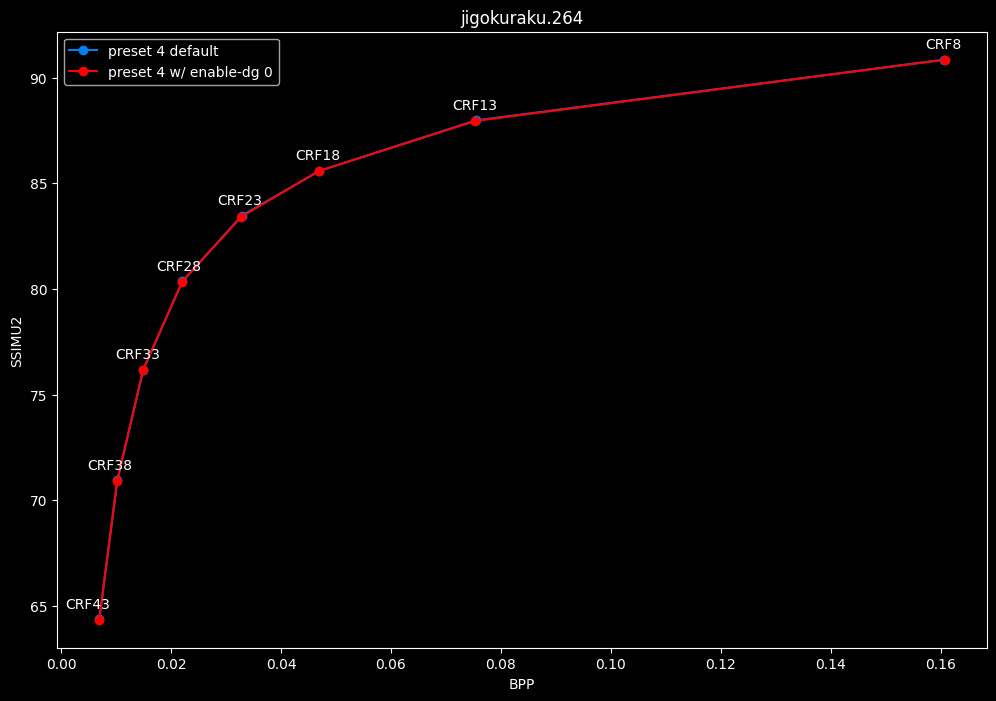
- Speed graphs:
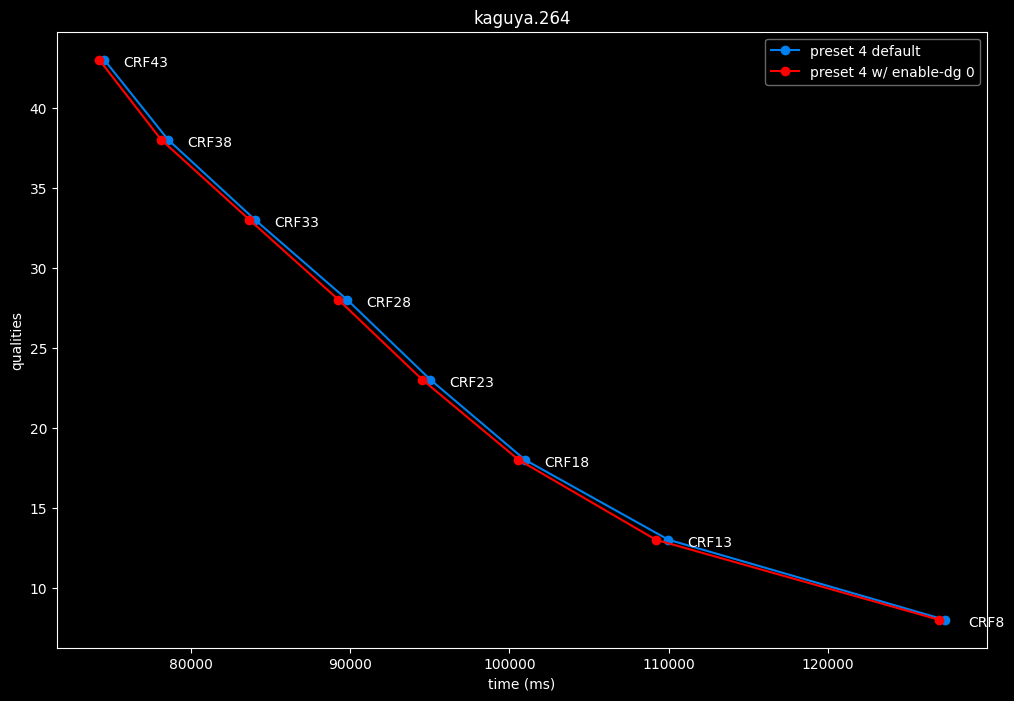
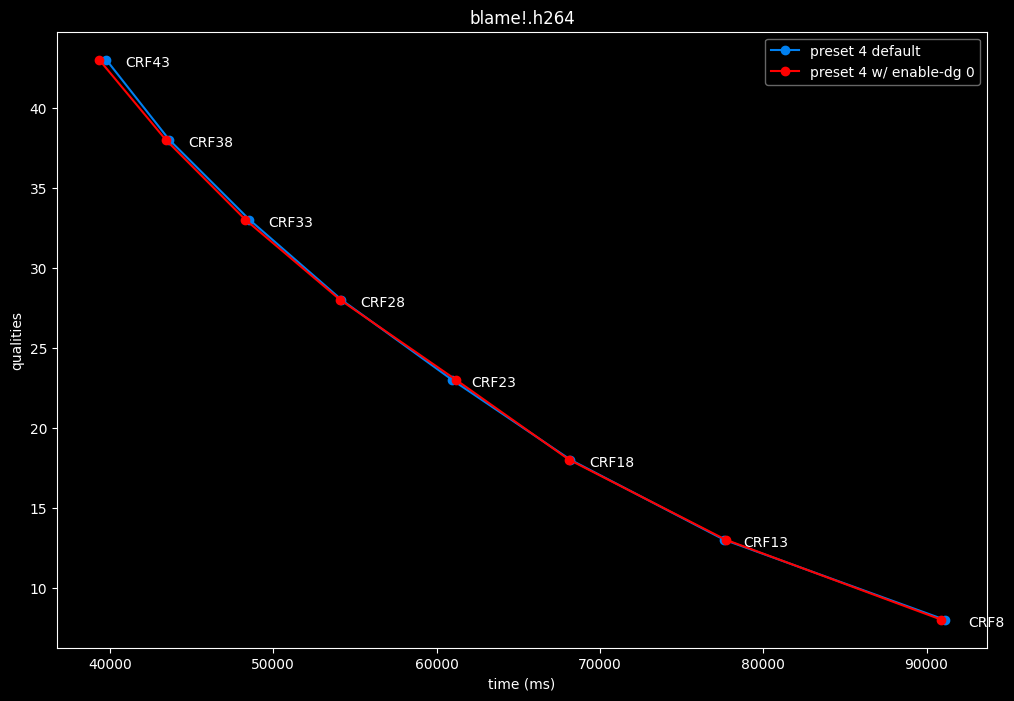
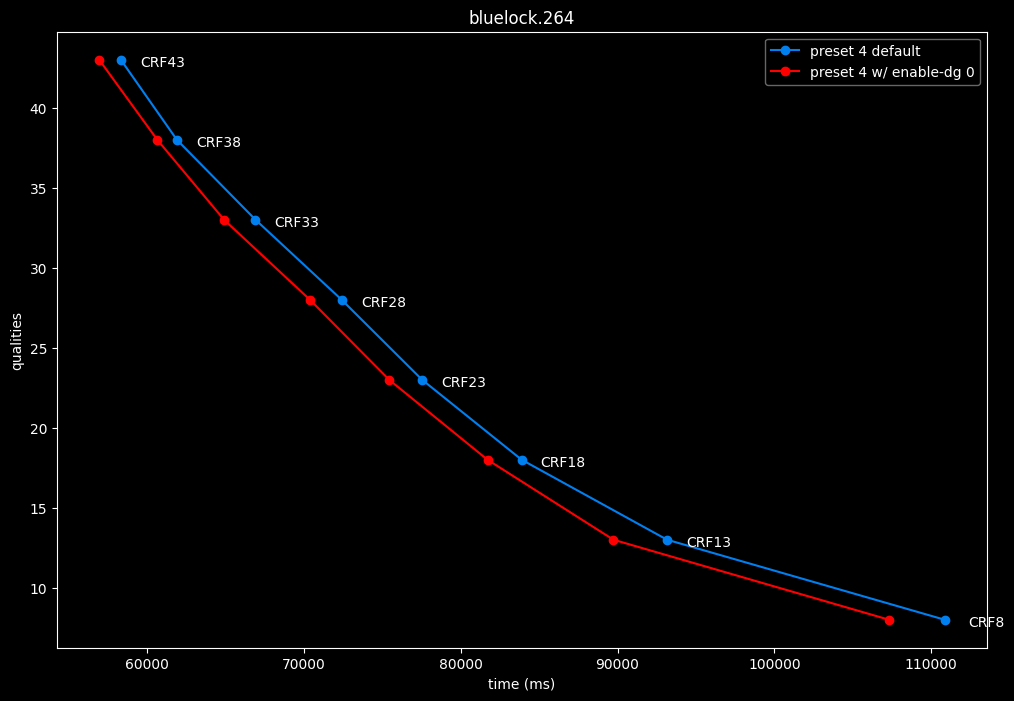

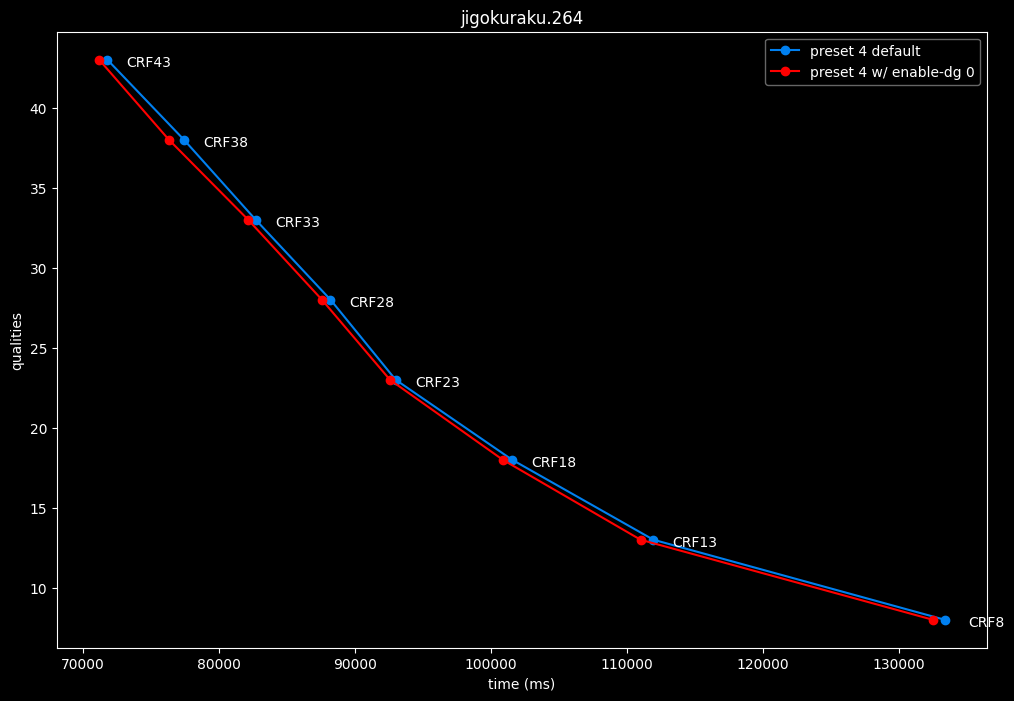
Dynamic GoP control yields bit-perfect results in all clips except for Blue Lock and Jigokuraku. There is no speed benefit to disabling it except in clips where it is in use. Let's not jump to conclusions too easily, the image comparisons will tell if it's "safe" to keep the setting disabled at all times or not.
--enable-dlf 0 vs default --enable-dlf 1
- Efficiency graphs:
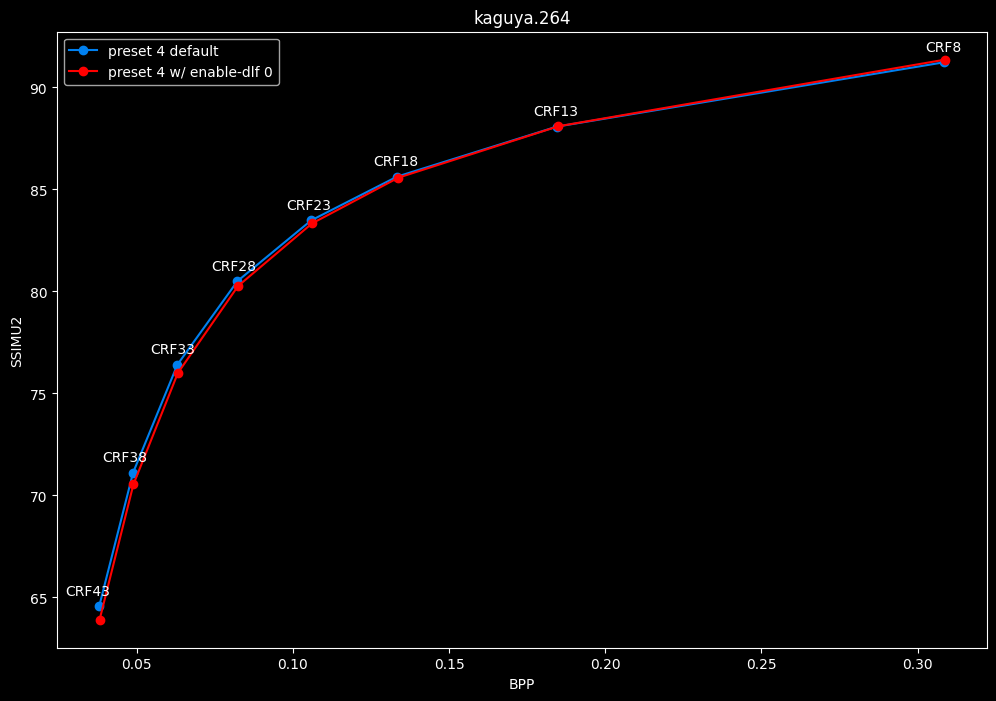
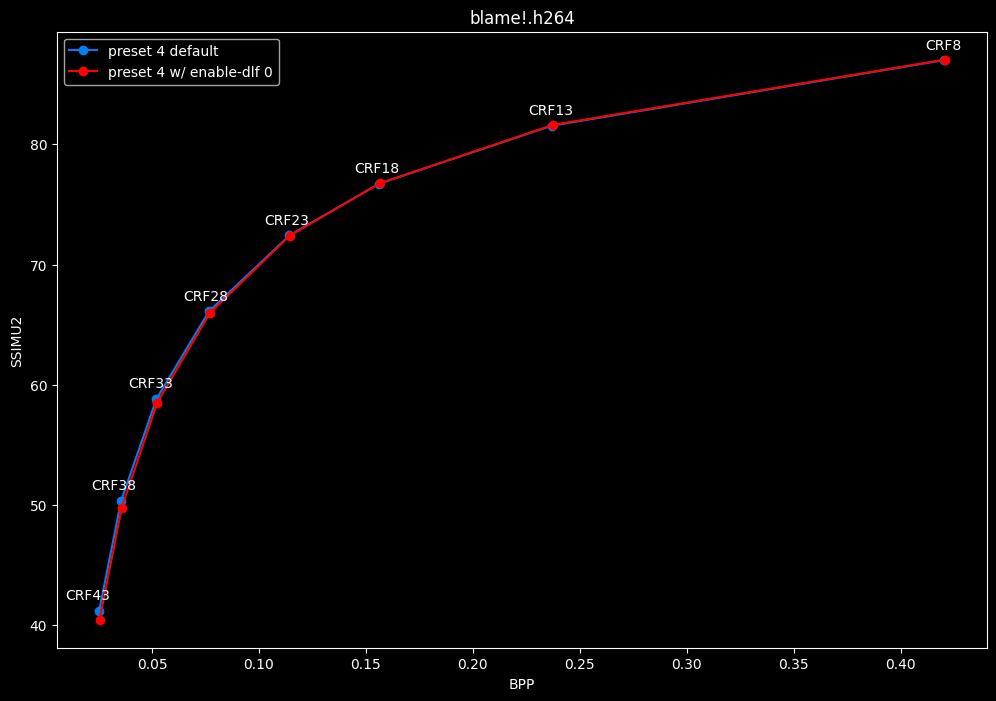
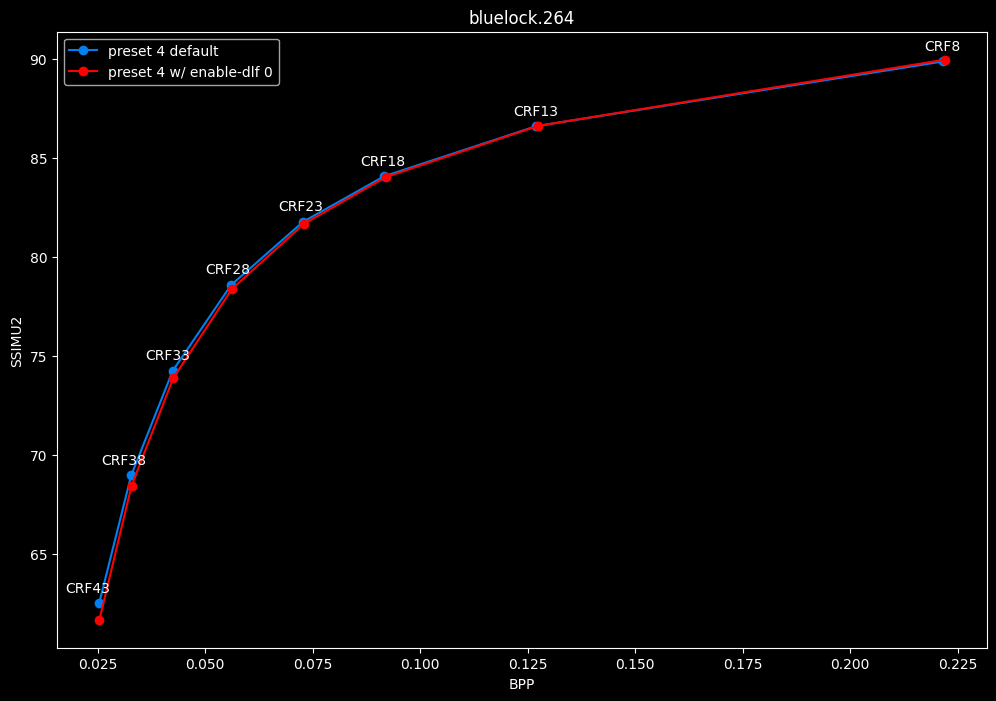
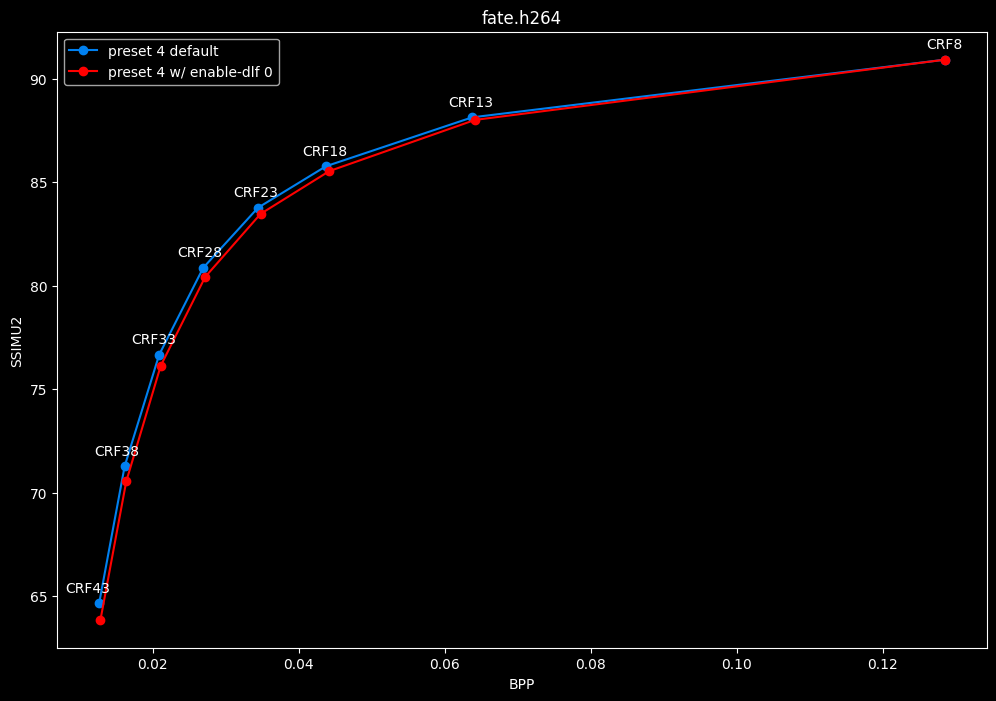
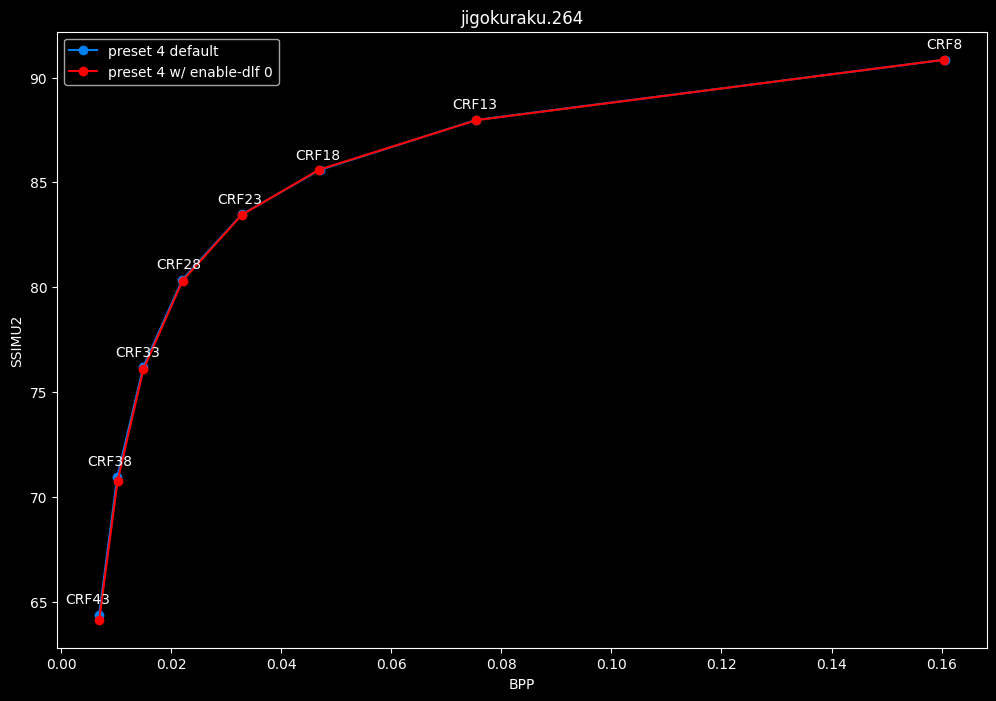
- Speed graphs:
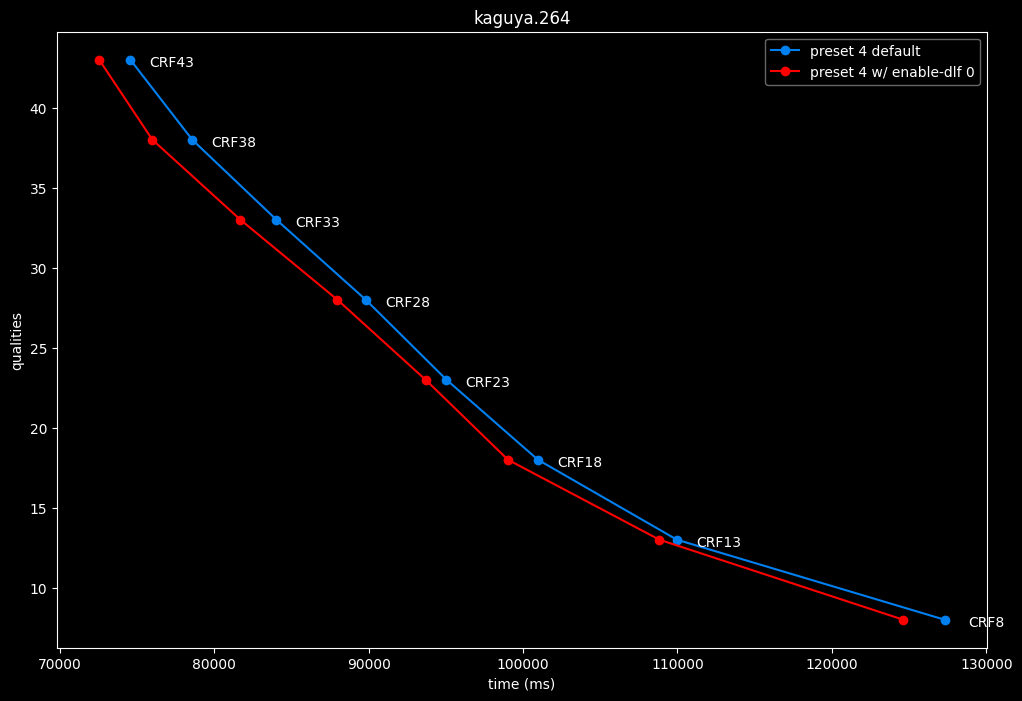
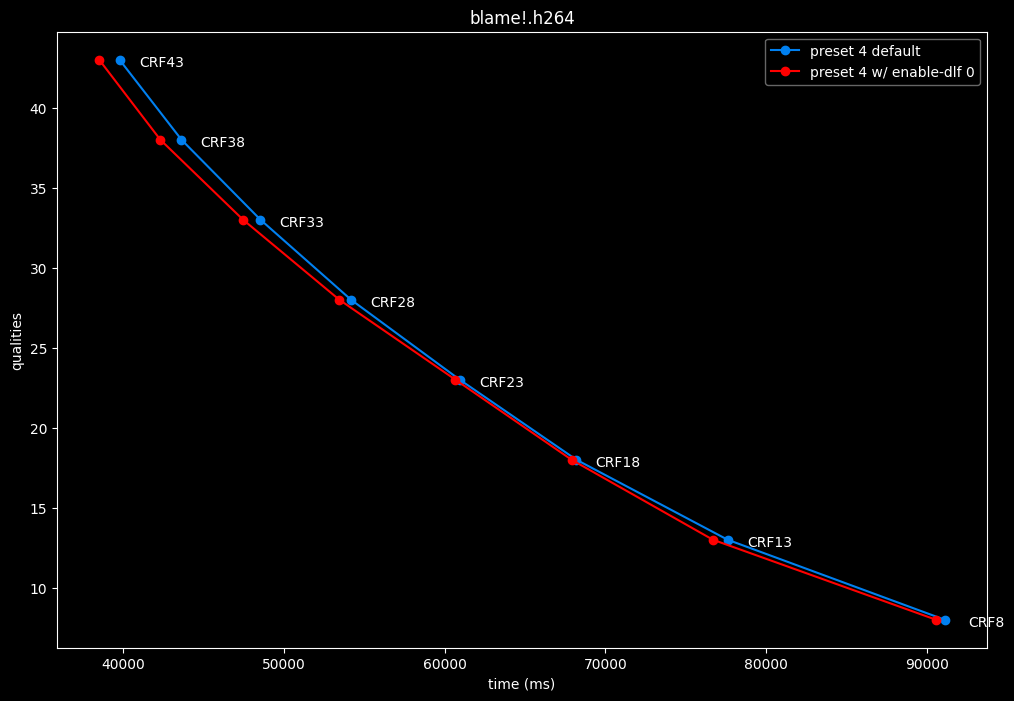
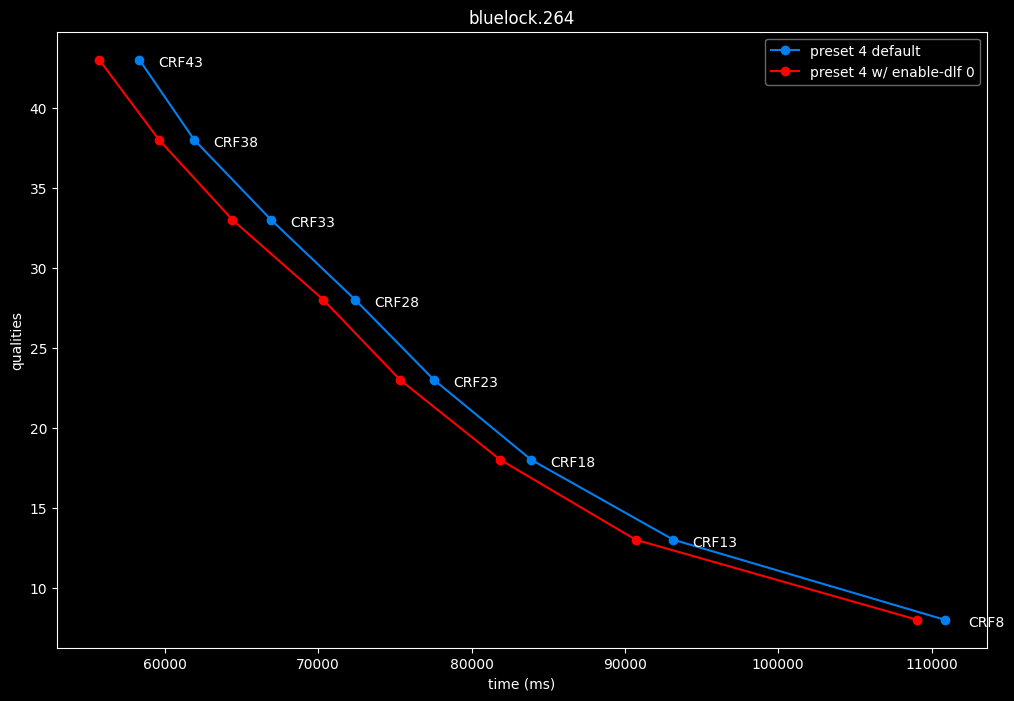
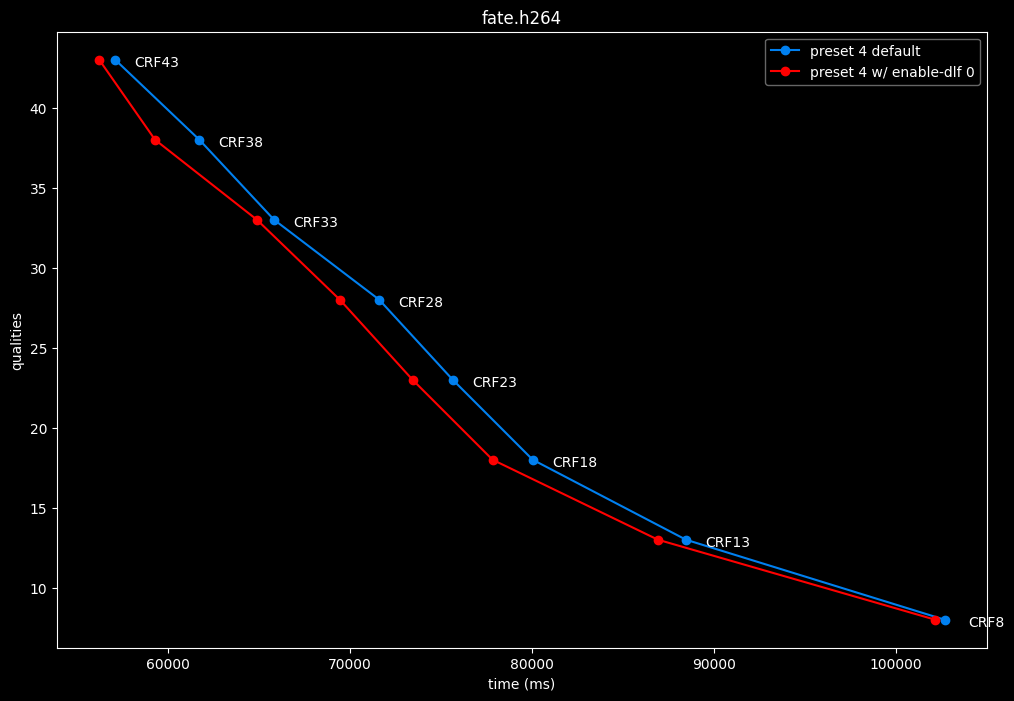
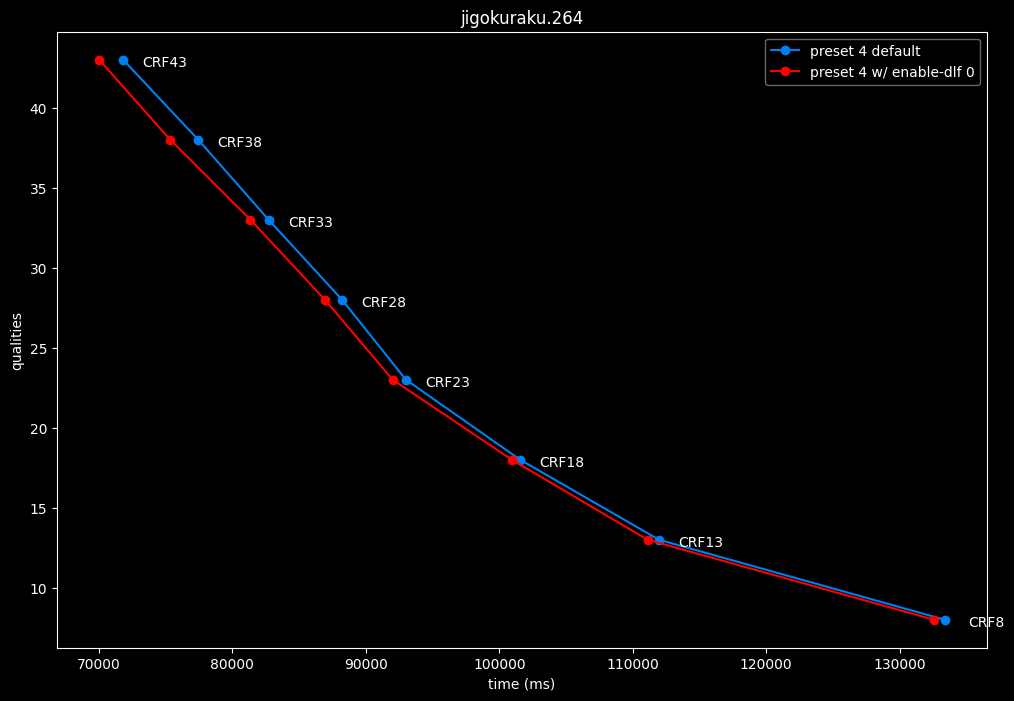
Deblocking loop filter can be slightly beneficial in some scenarios. In reverse, it is never harmful, so it is recommended to keep it default.
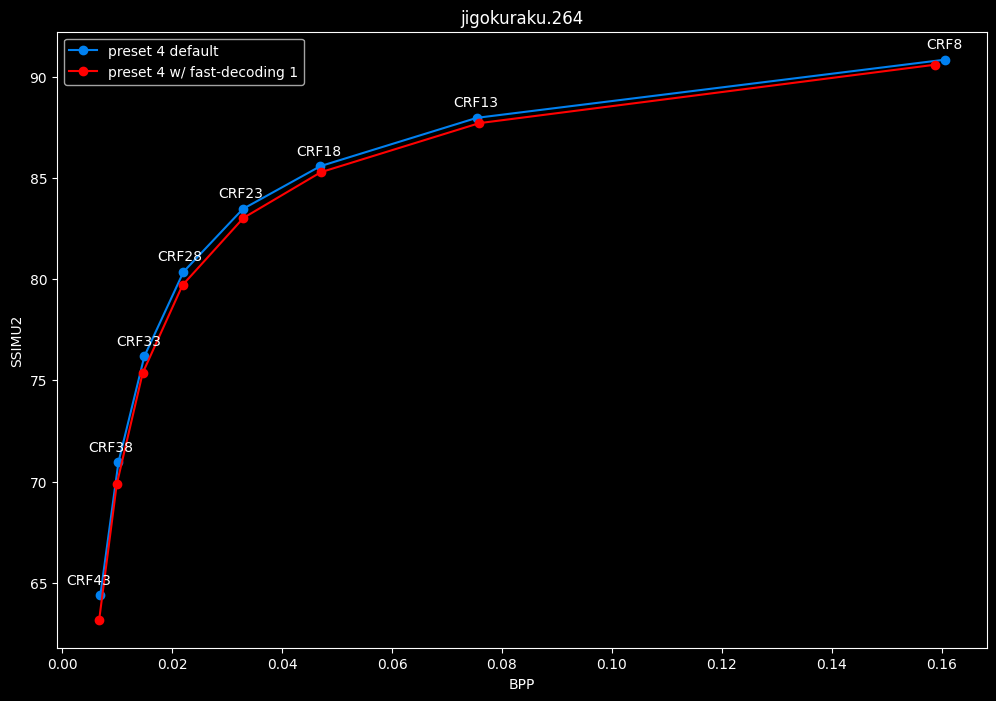
--fast-decode 1 vs default --fast-decode 0
- Efficiency graphs:
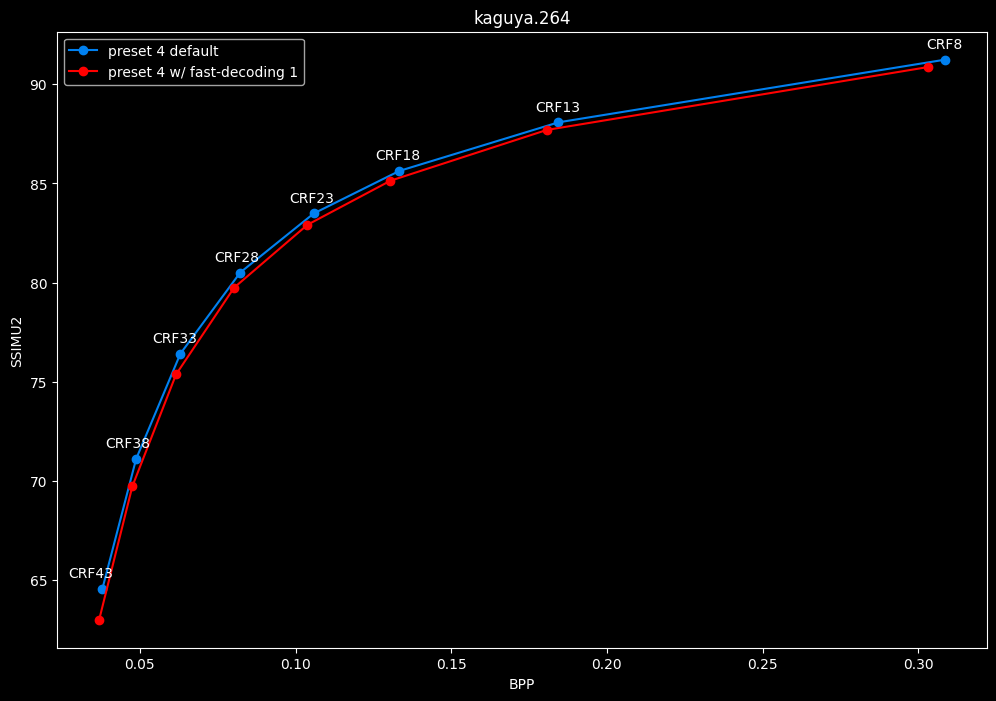
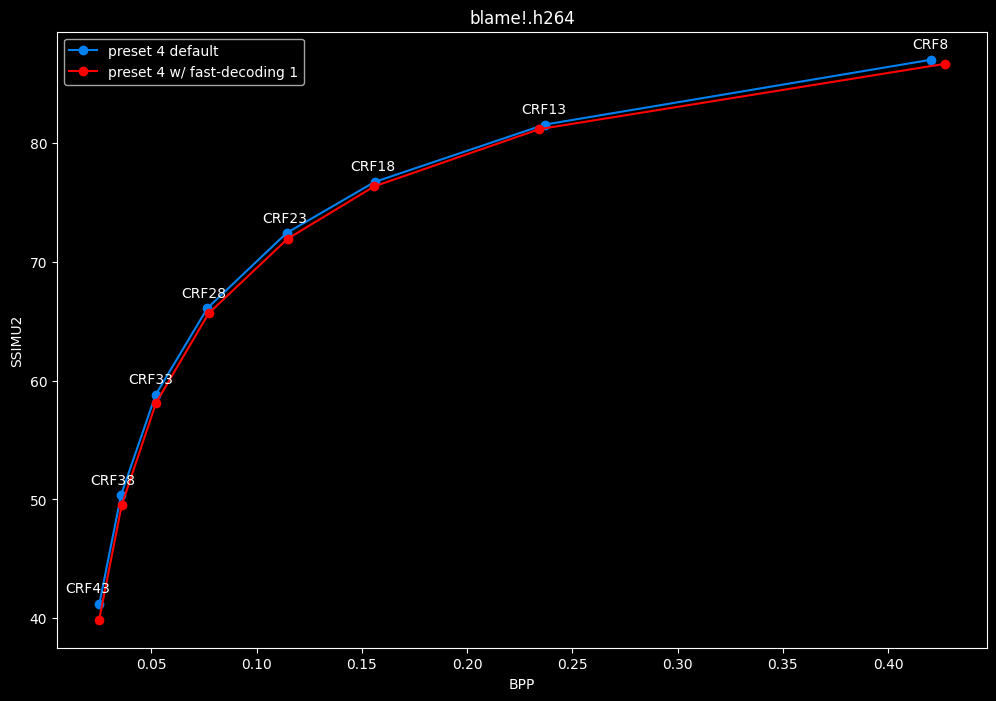
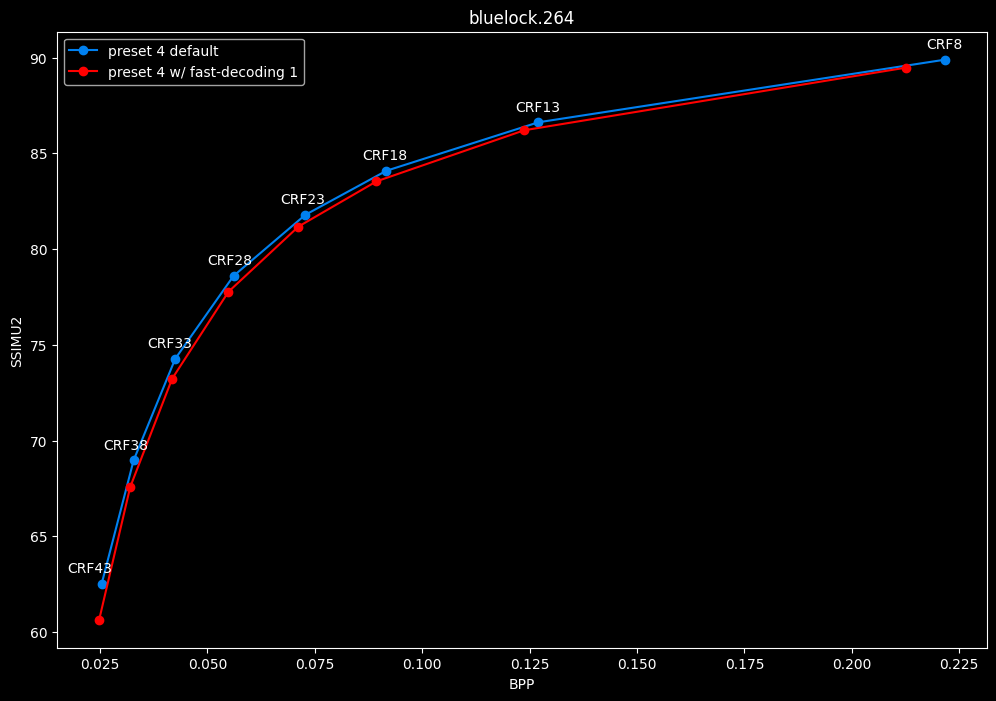
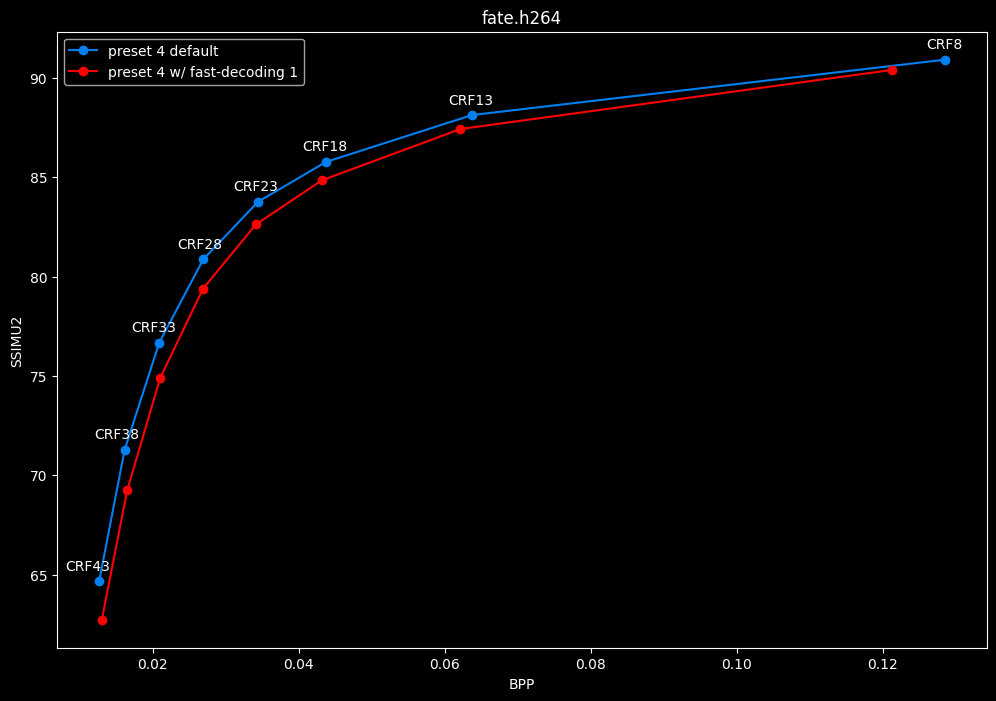
- Speed graphs:
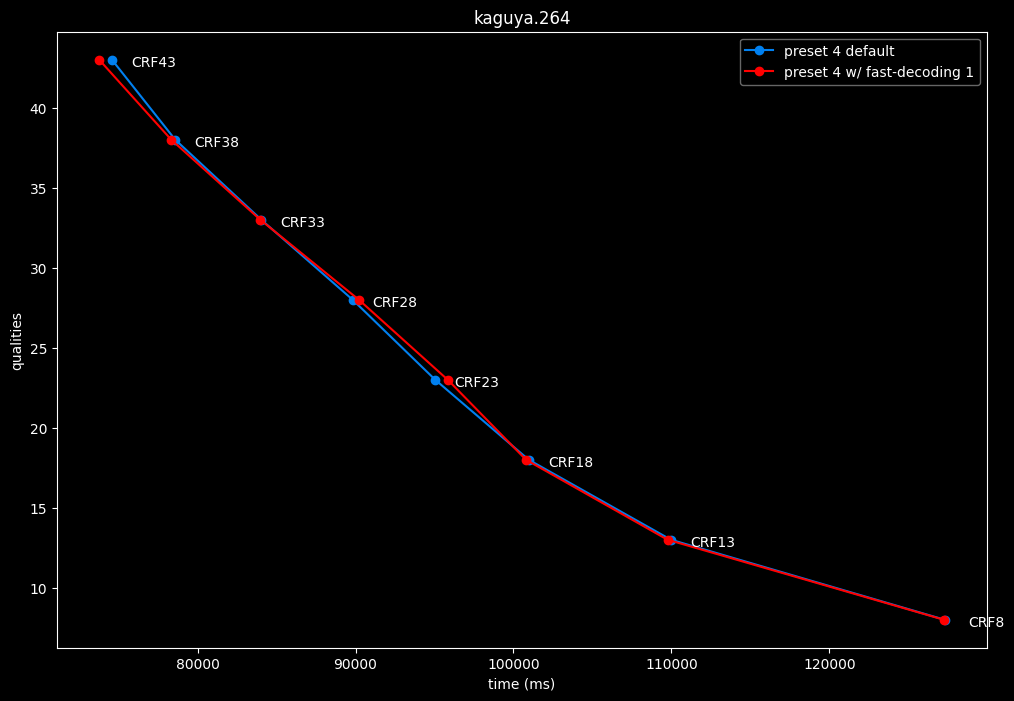
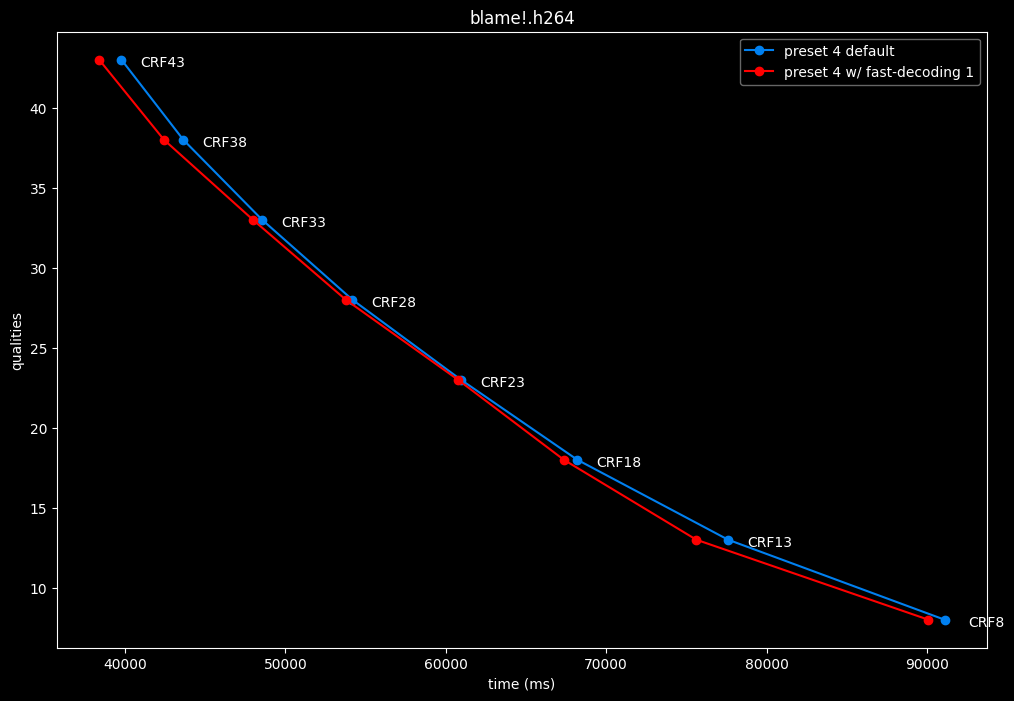
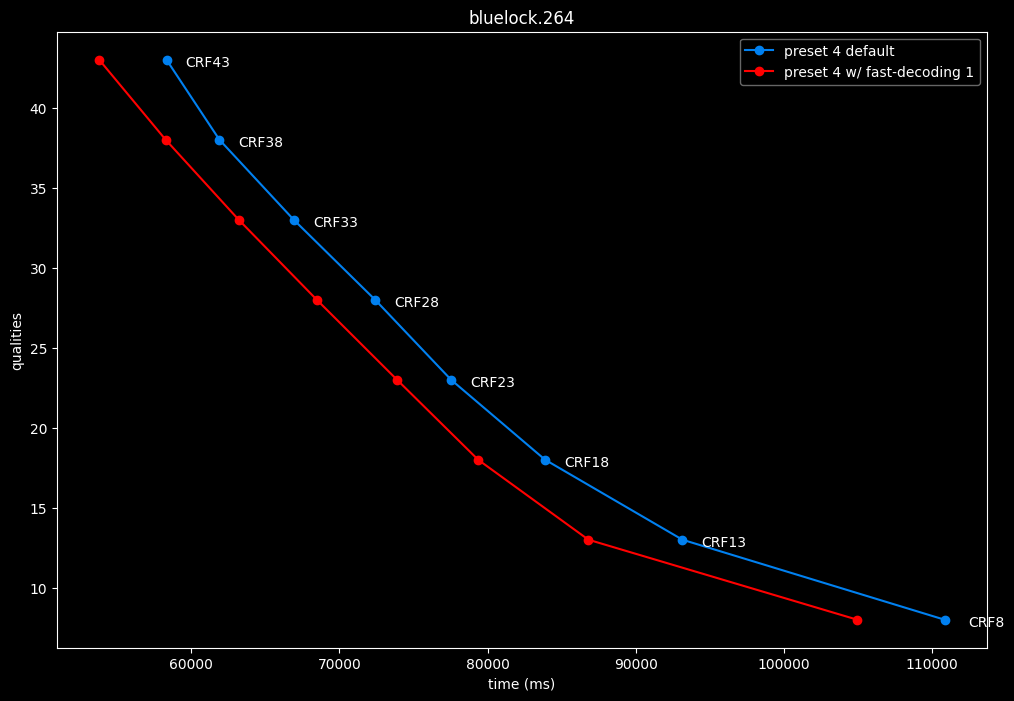
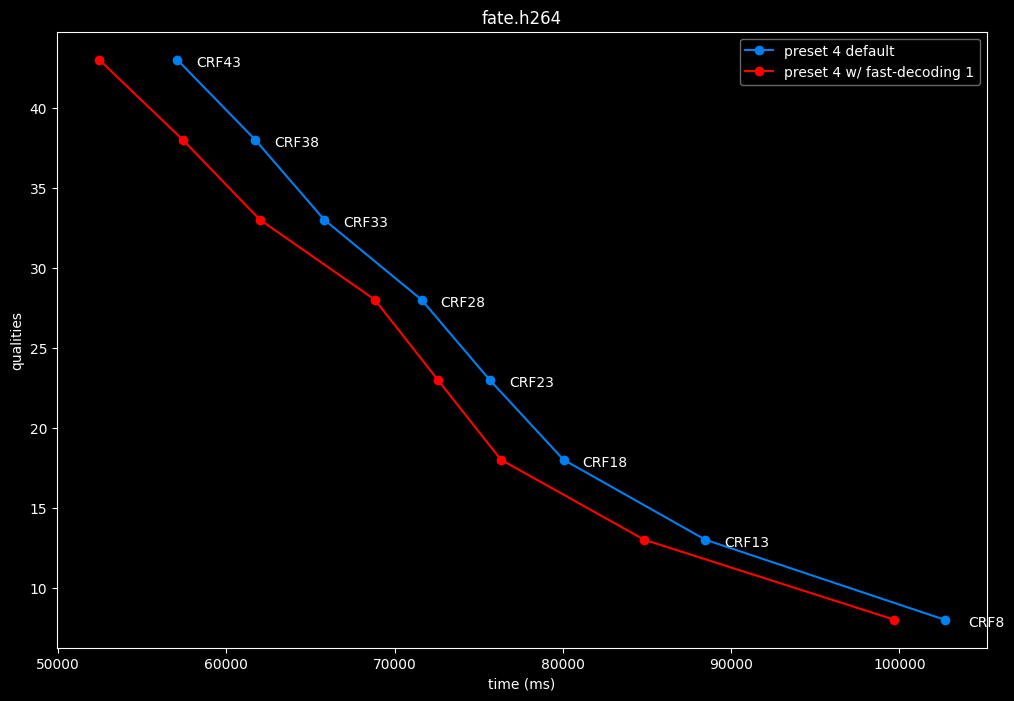
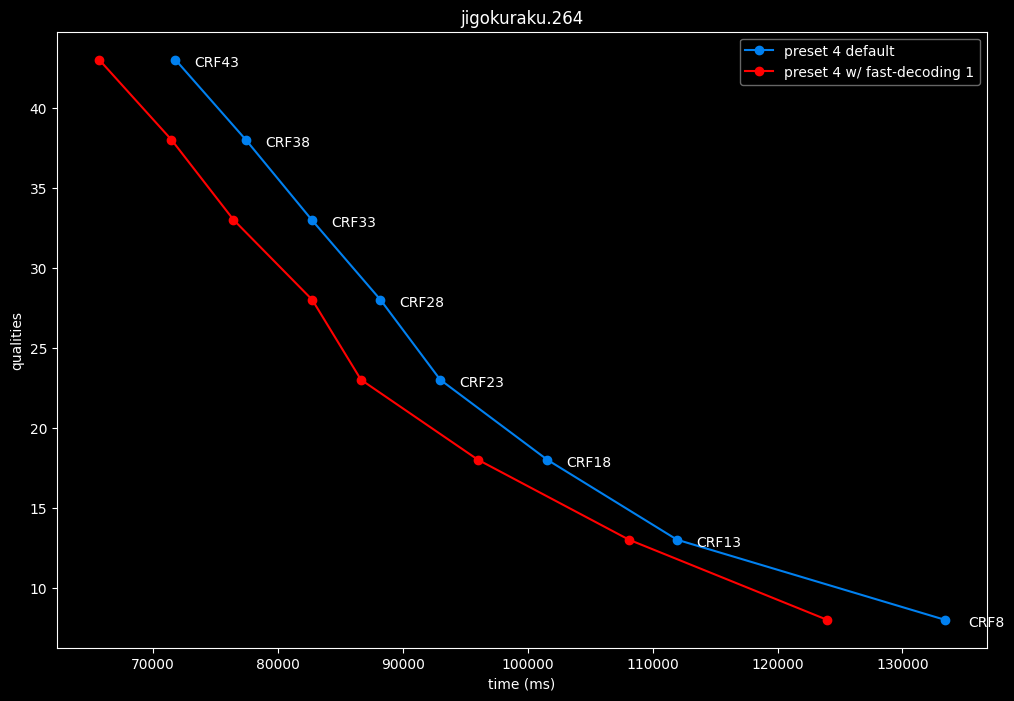
fast-decode 1 is pretty harmful in the Fate clip and slightly harmful in the rest. There is a speed benefit of enabling it though.
--irefresh-type 1 vs default --irefresh-type 2
- Efficiency graphs:
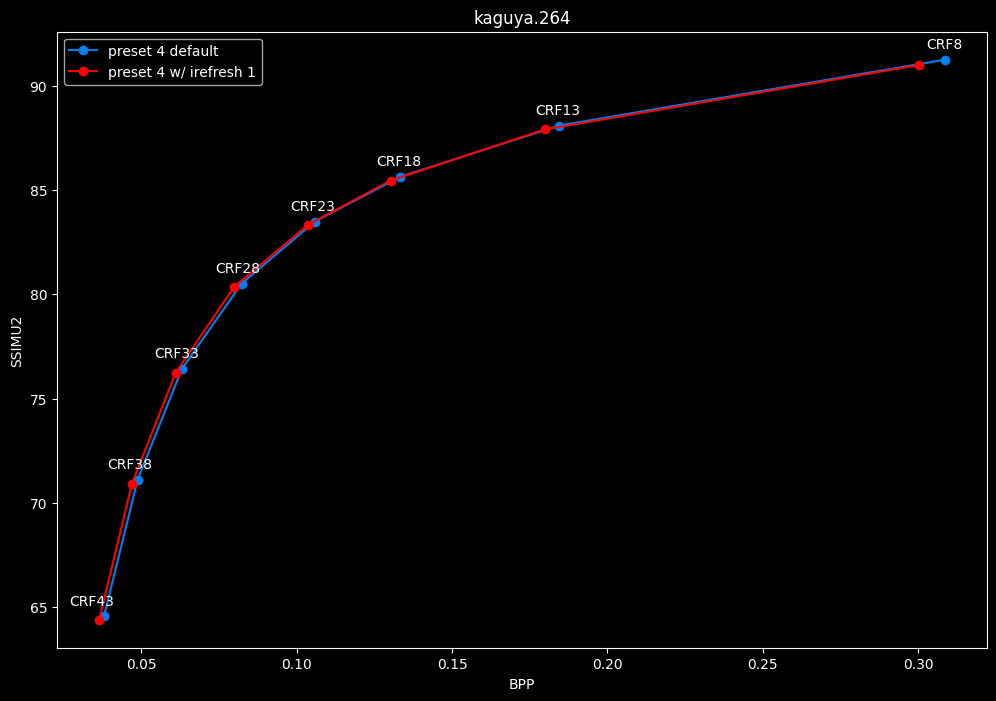
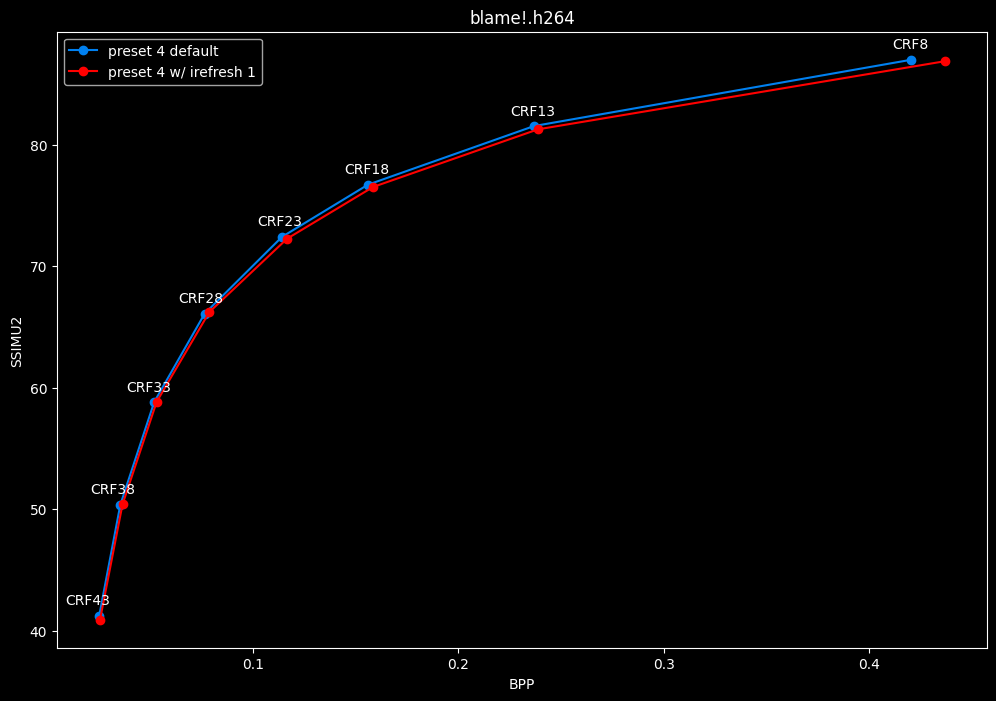

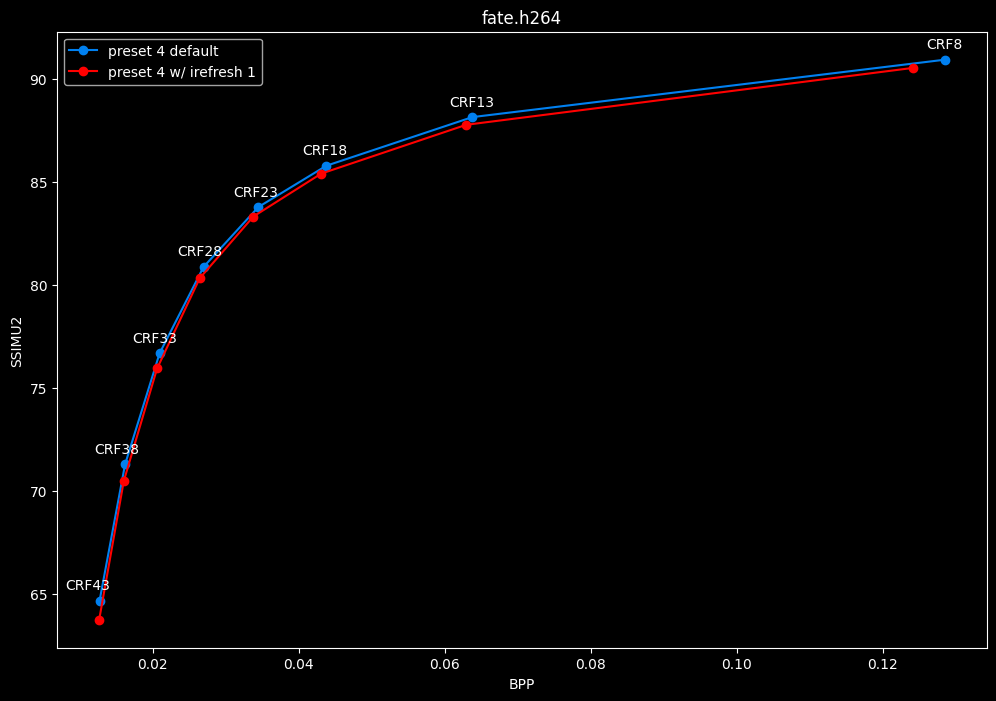
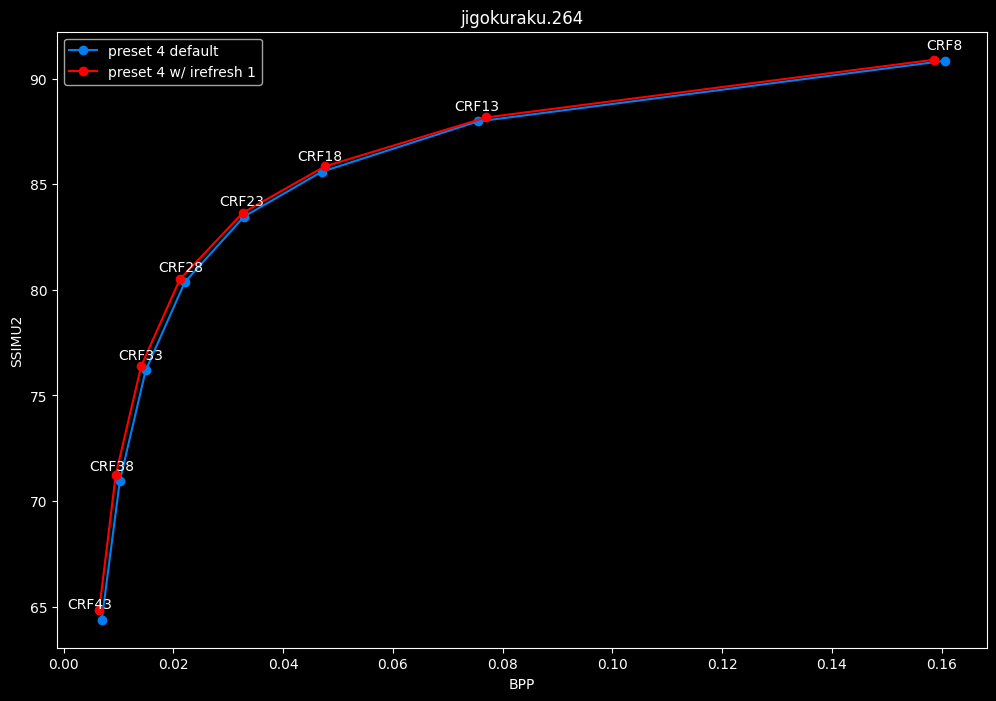
- Speed graphs:
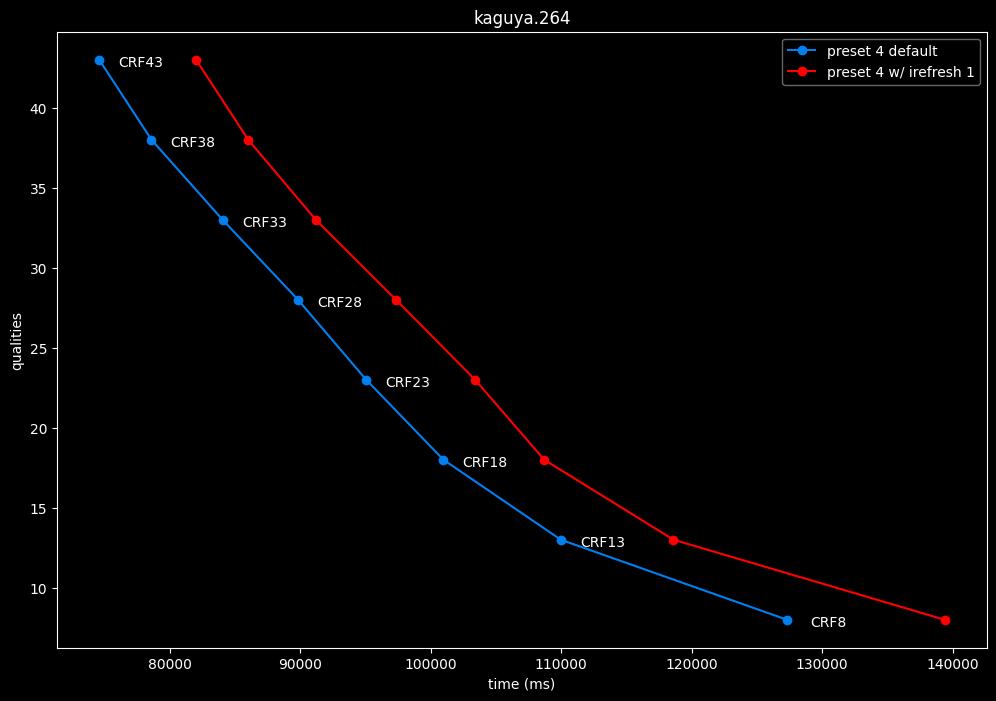
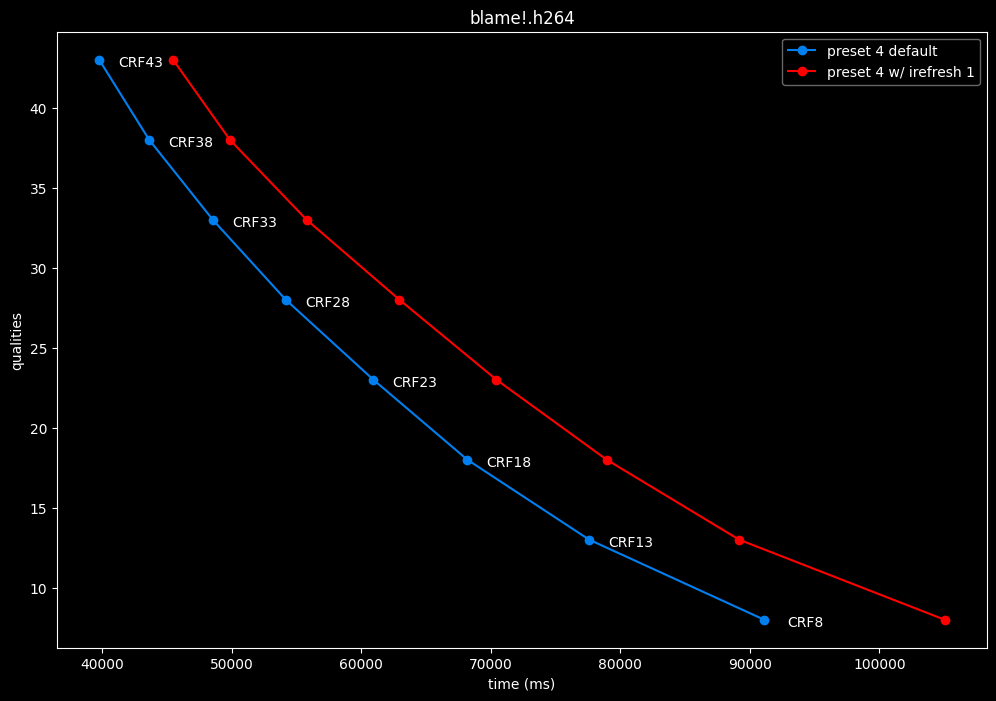
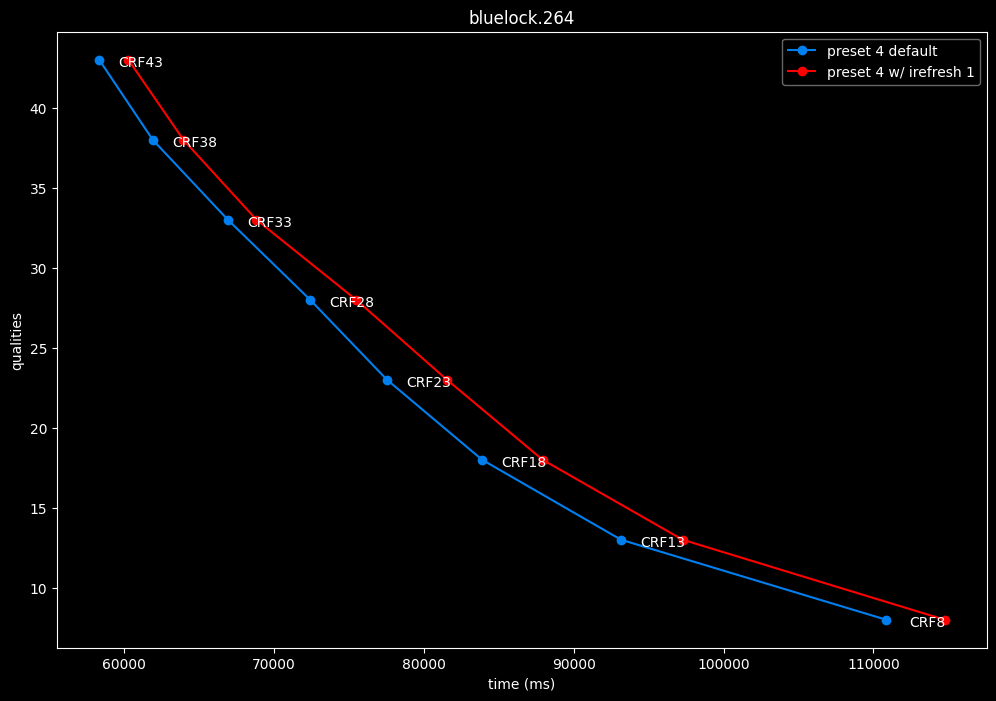
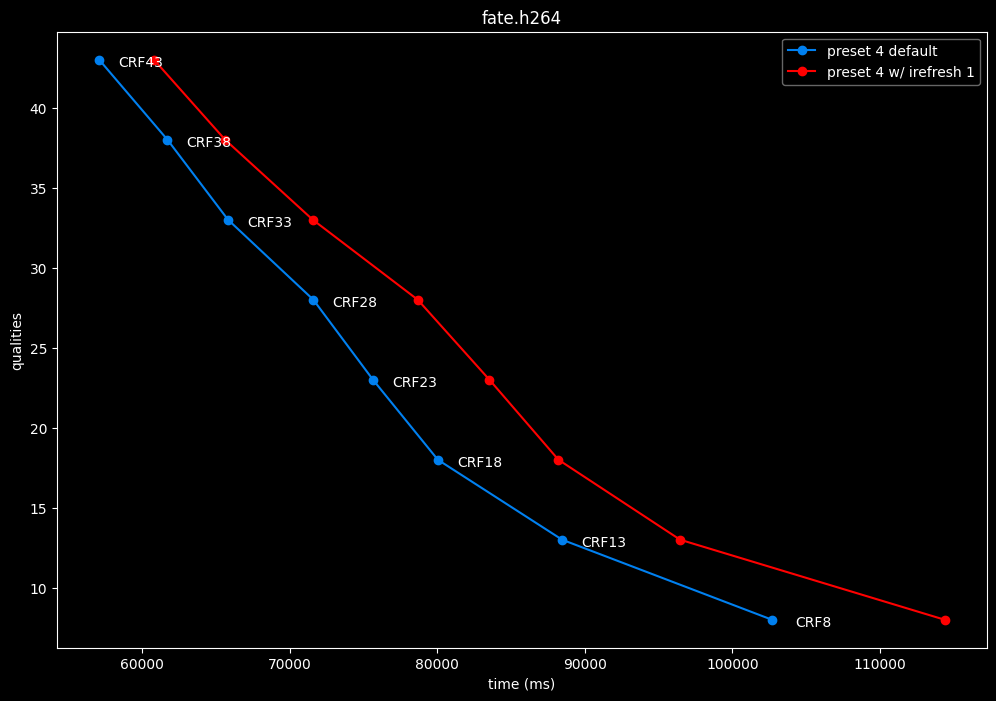
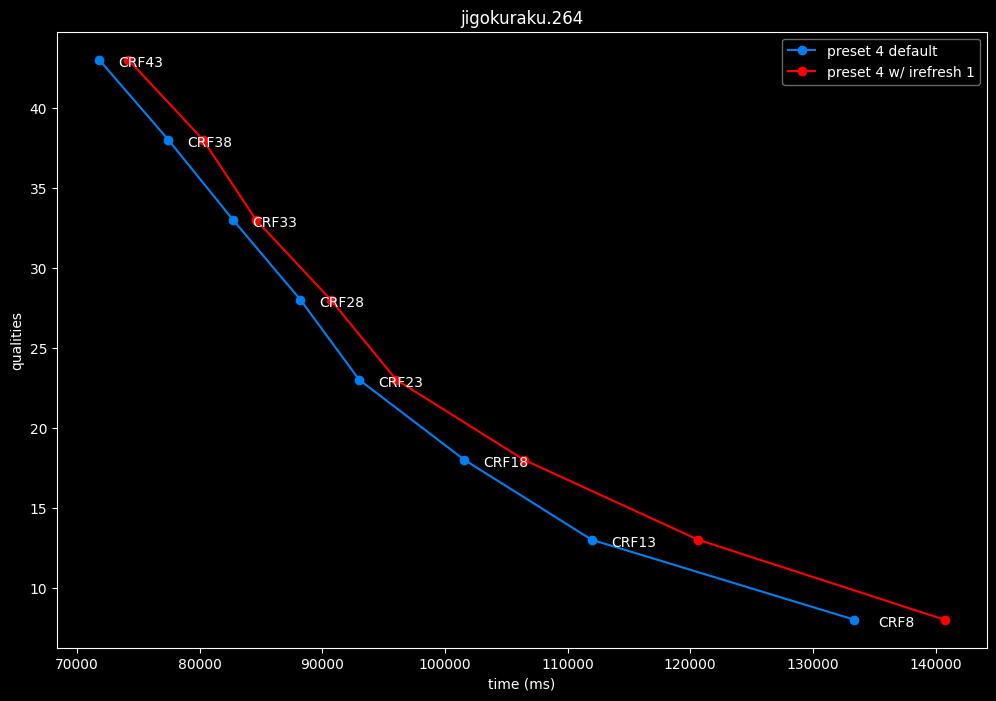
Finally something interesting to analyse!
- irefresh-type 1 is either a match or beneficial compared to irefresh-type 2 at high CRF levels.
- irefresh-type 1 either wins or lose to irefresh-type 2 at low CRF levels depending on the clip. As such, it is NOT recommended to blindly set irefresh-type to 1 at "high quality" as it might be harmful depending on the content.
- irefresh-type 1 is always slower compared to irefresh-type 2, so I might argue it is more safe to leave irefresh-type default at "high quality" than not.
- According to the content type of those clips, it appears that irefresh-type 1 may benefit extremely grainy content while default irefresh-type 2 is better suited for cleanish content. This needs to be confirmed with moar testing though.
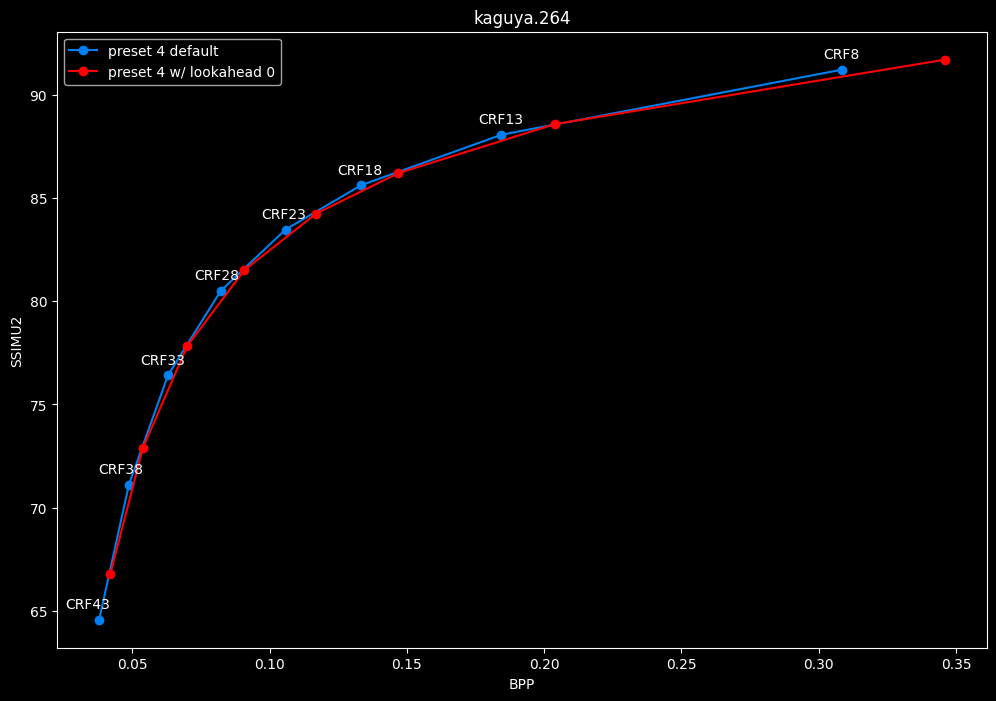
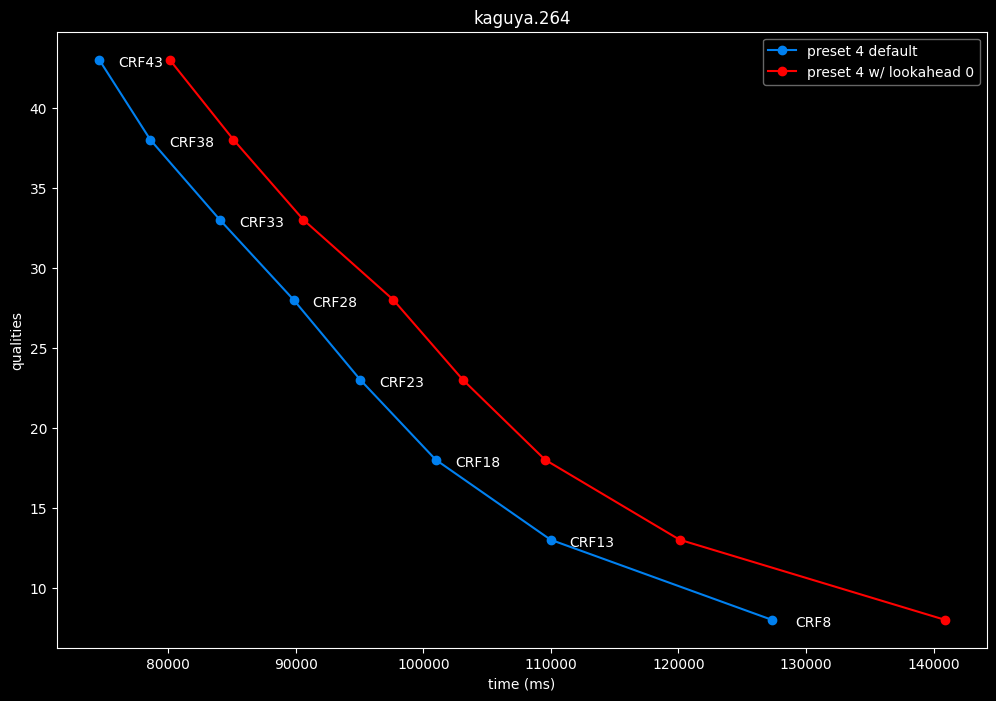
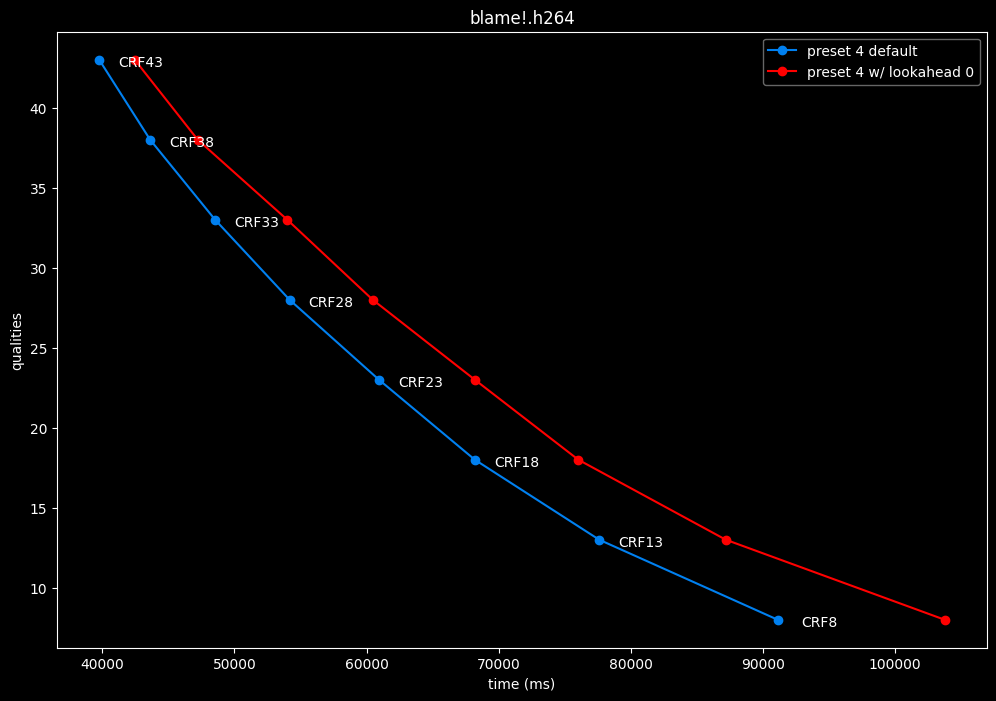
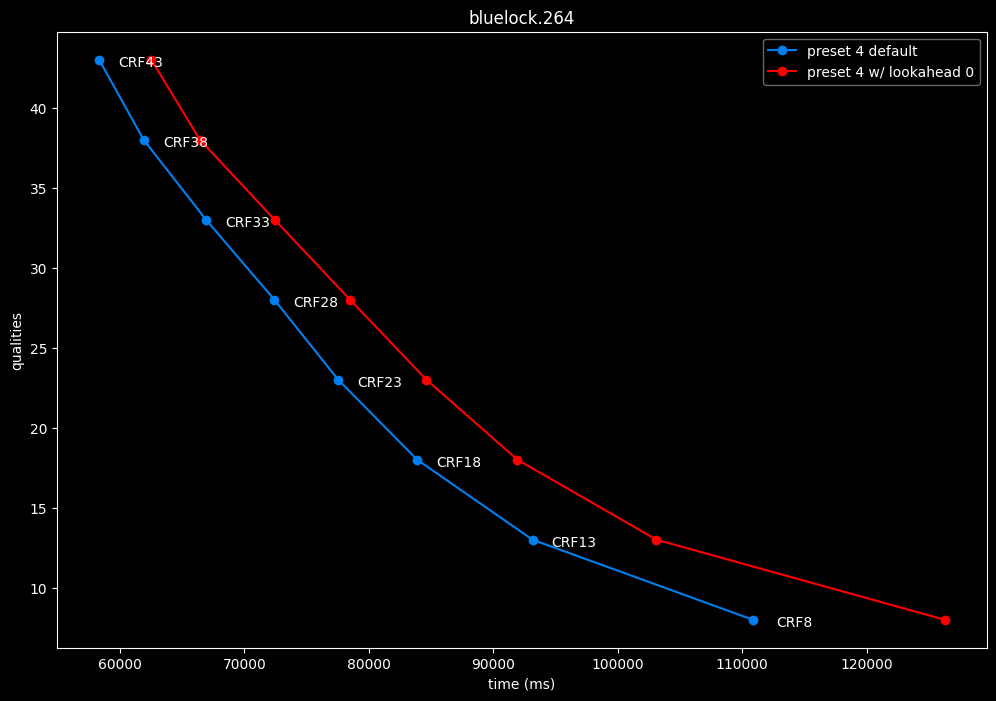
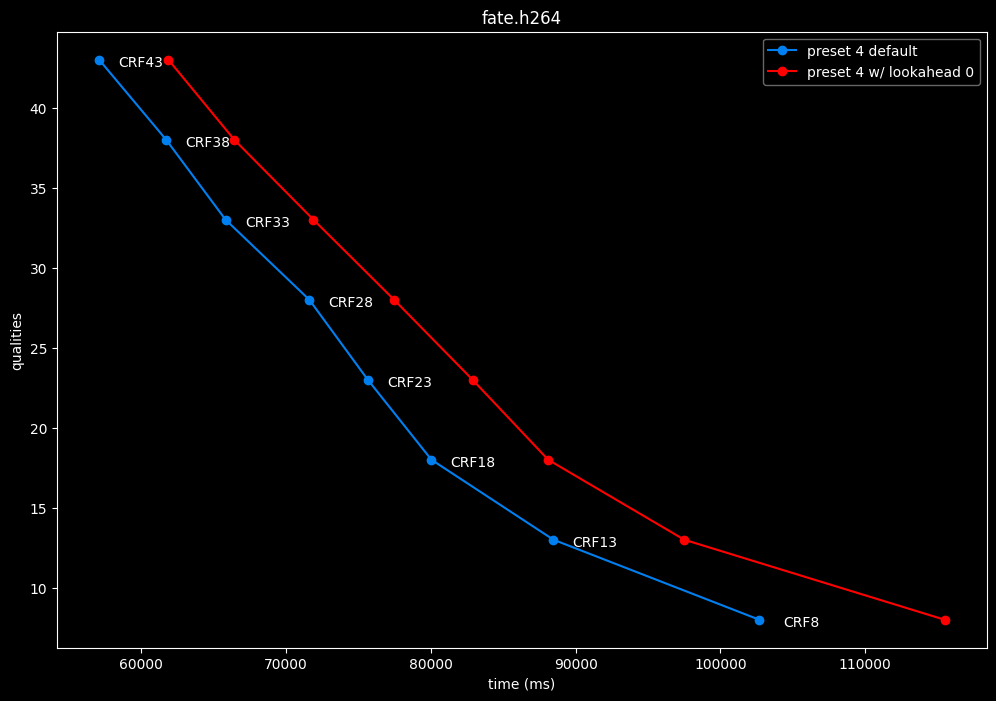
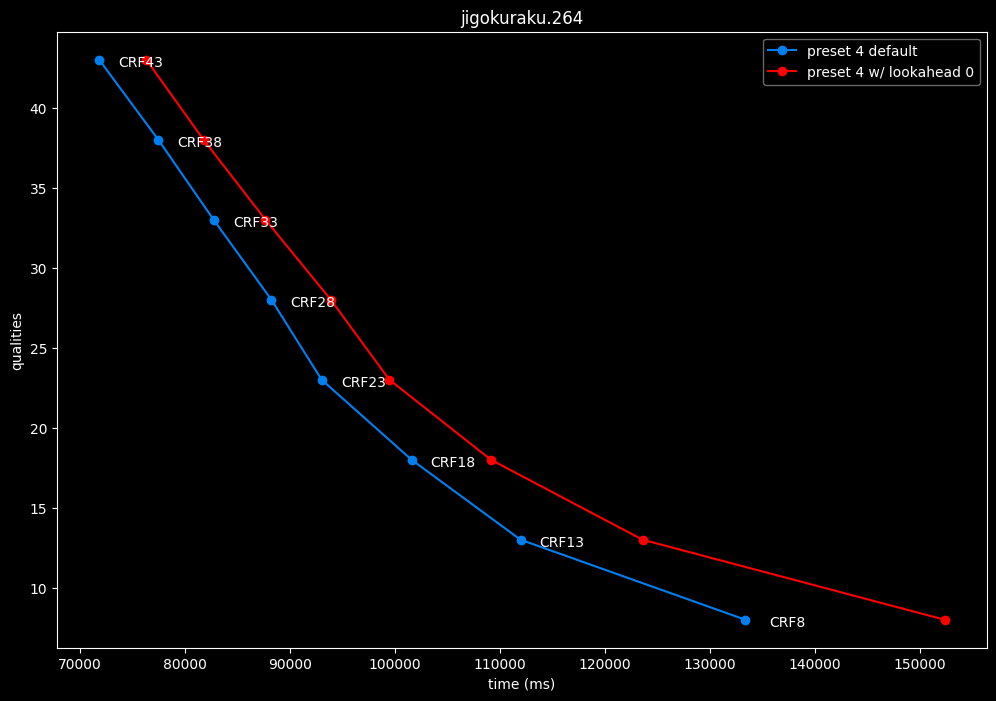
--lookahead 0 vs default --lookahead -1 (auto)
- Efficiency graphs:
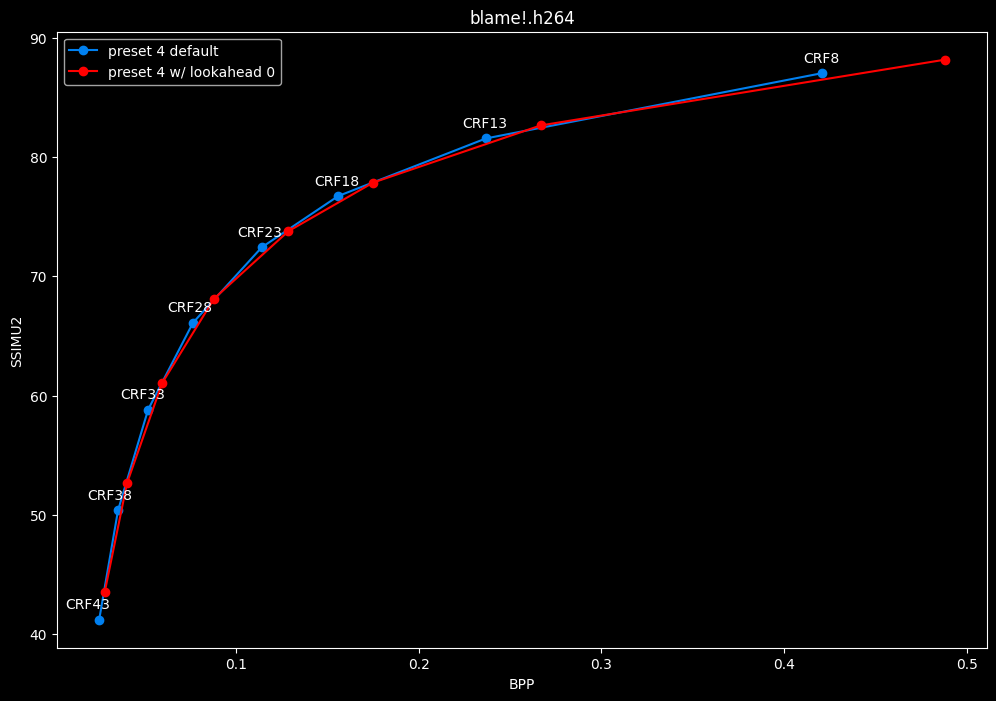
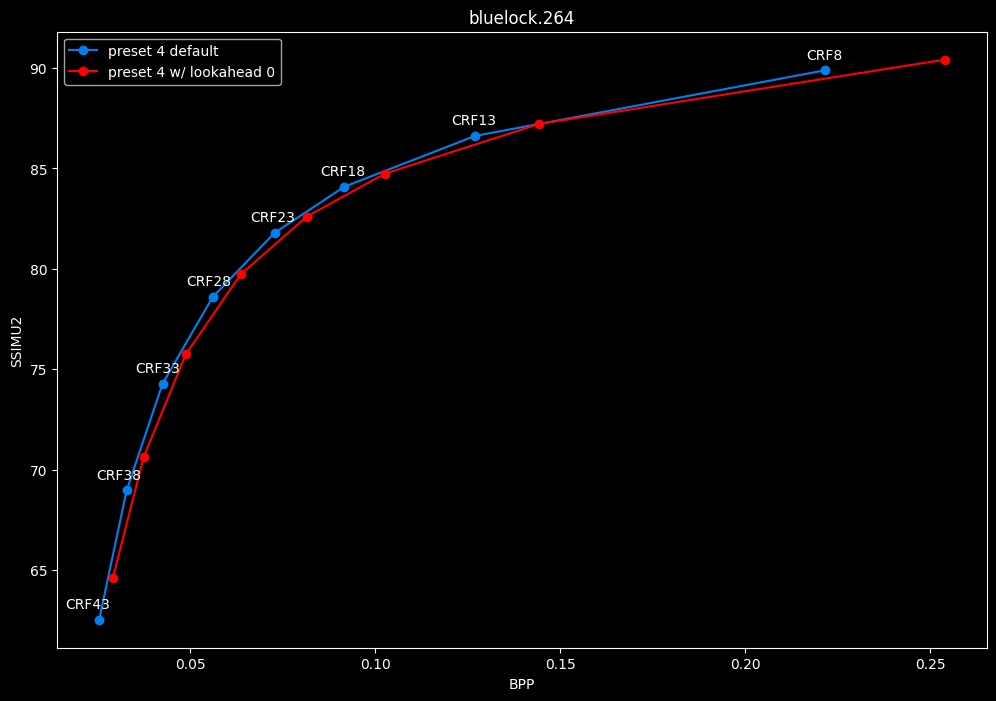
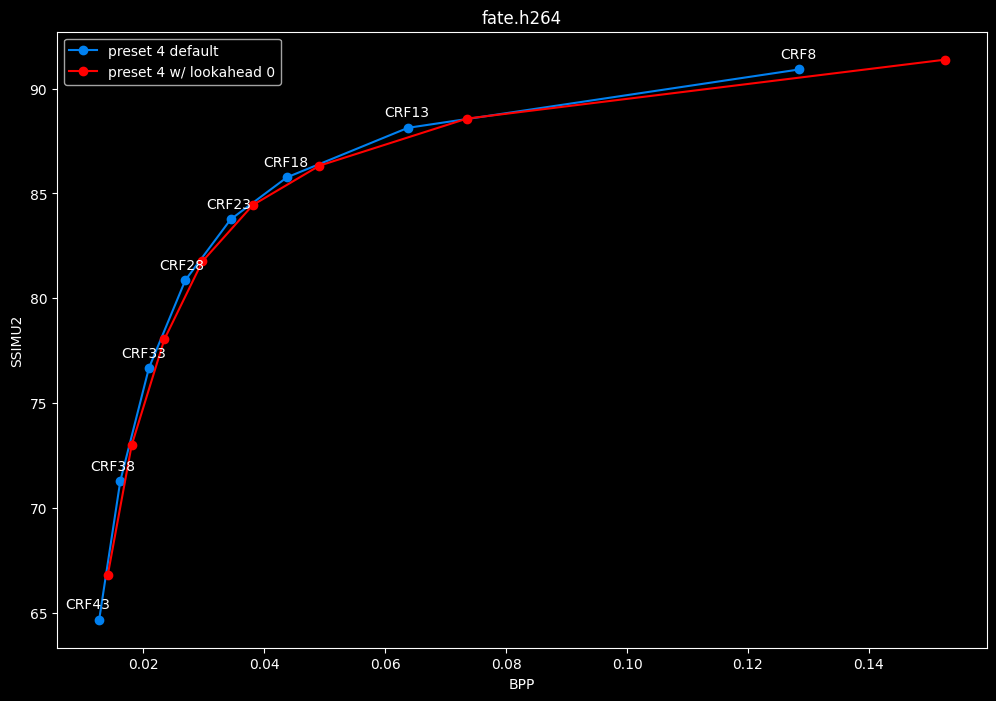

- Speed graphs:
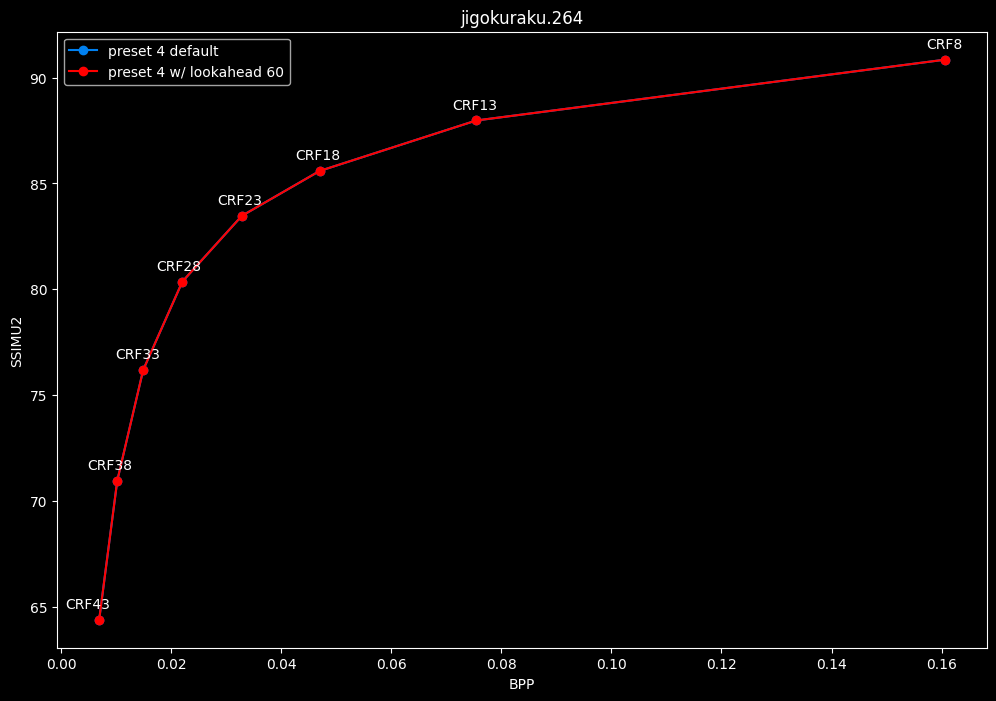
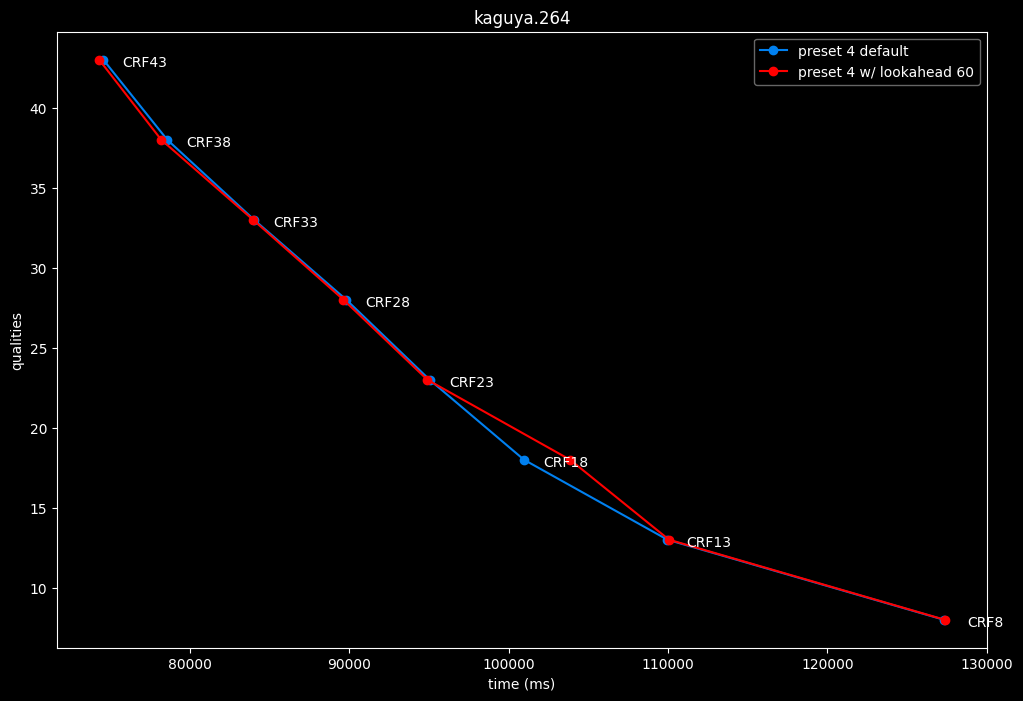
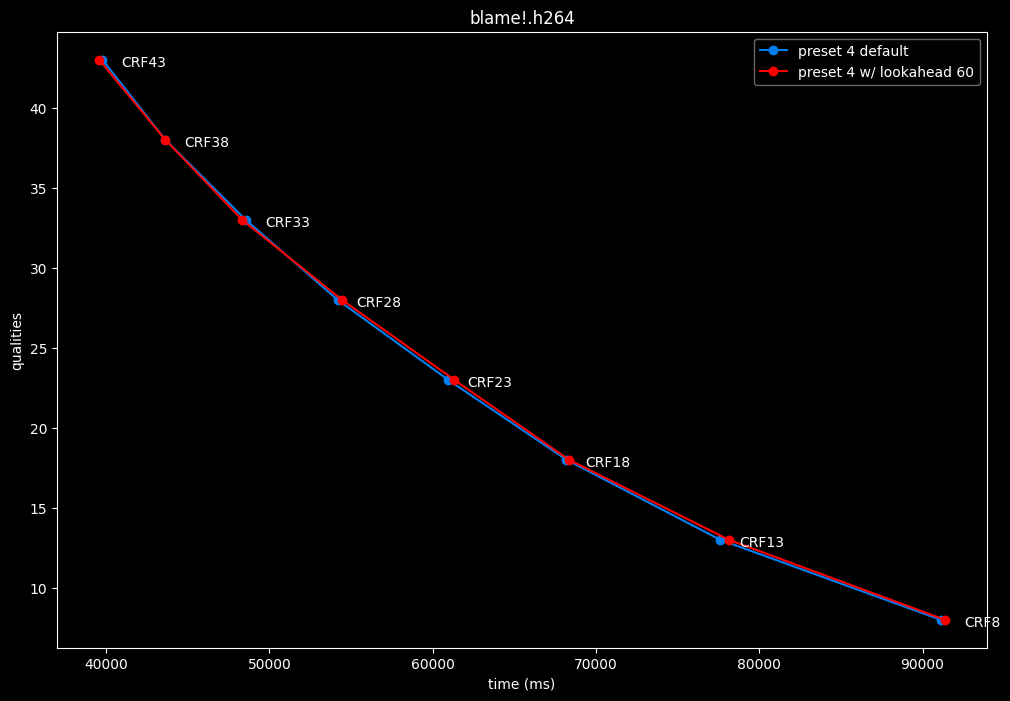
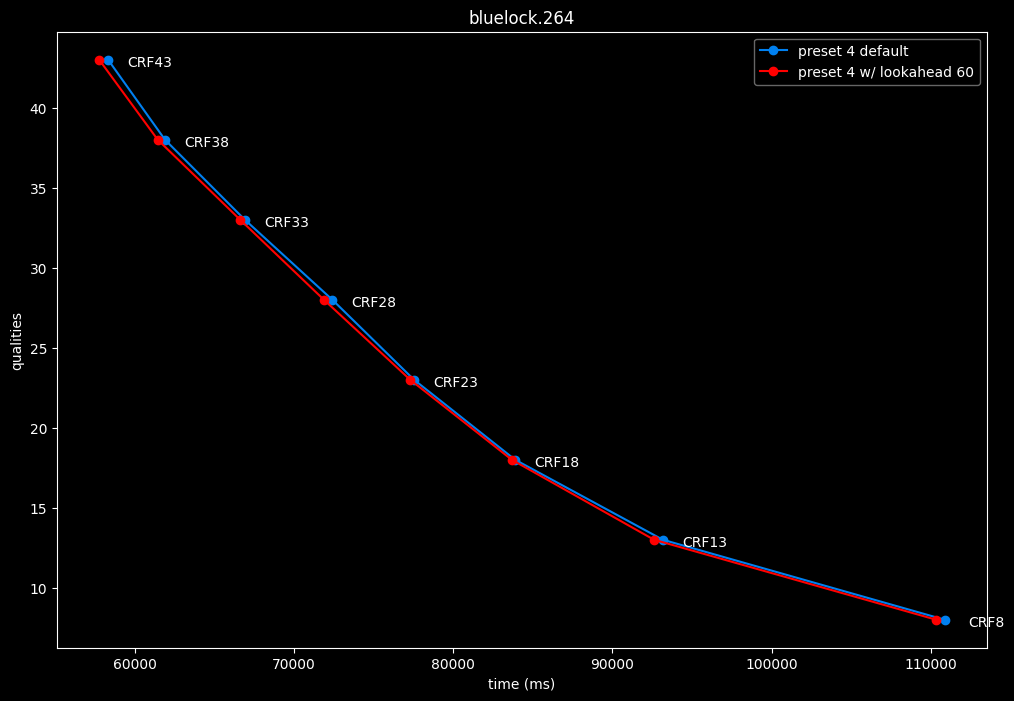
--lookahead 60 vs default --lookahead -1 (auto)
- Efficiency graphs:
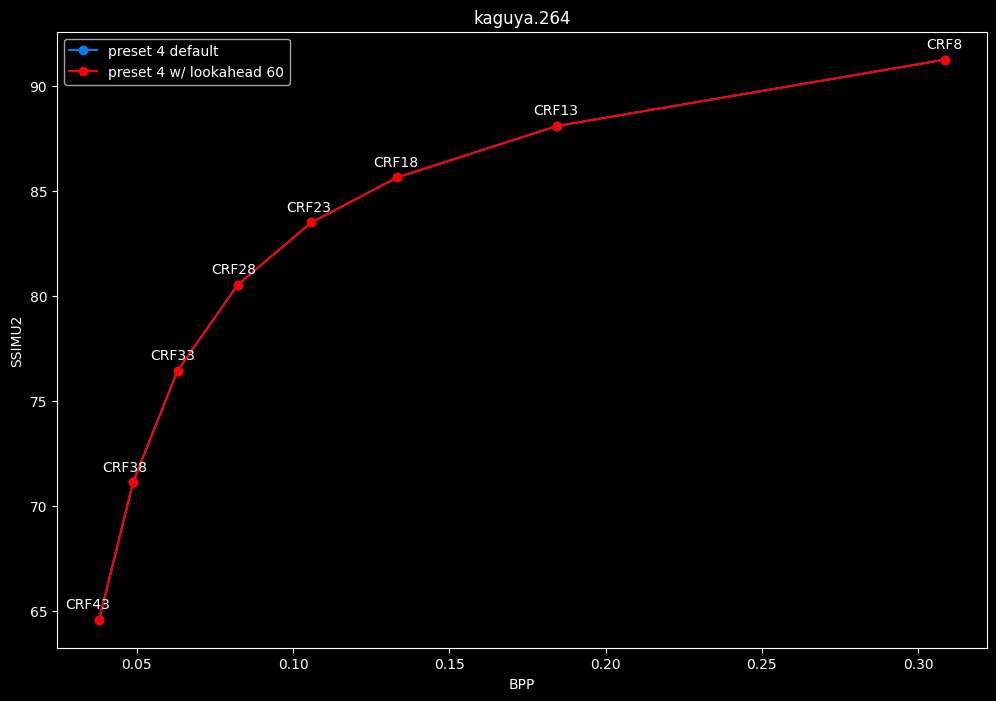
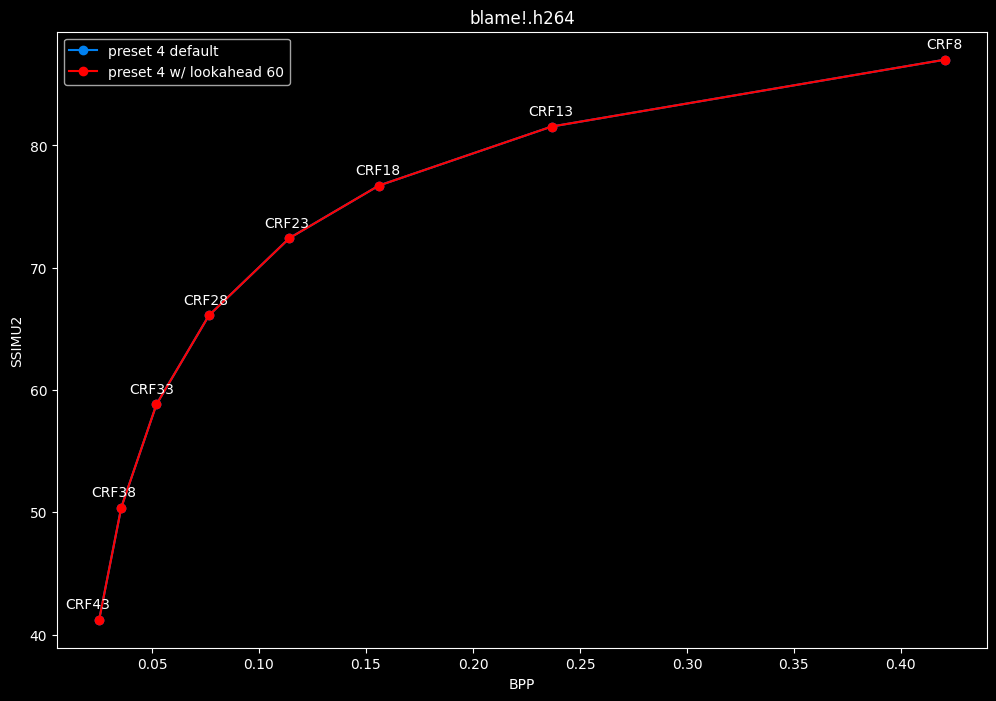
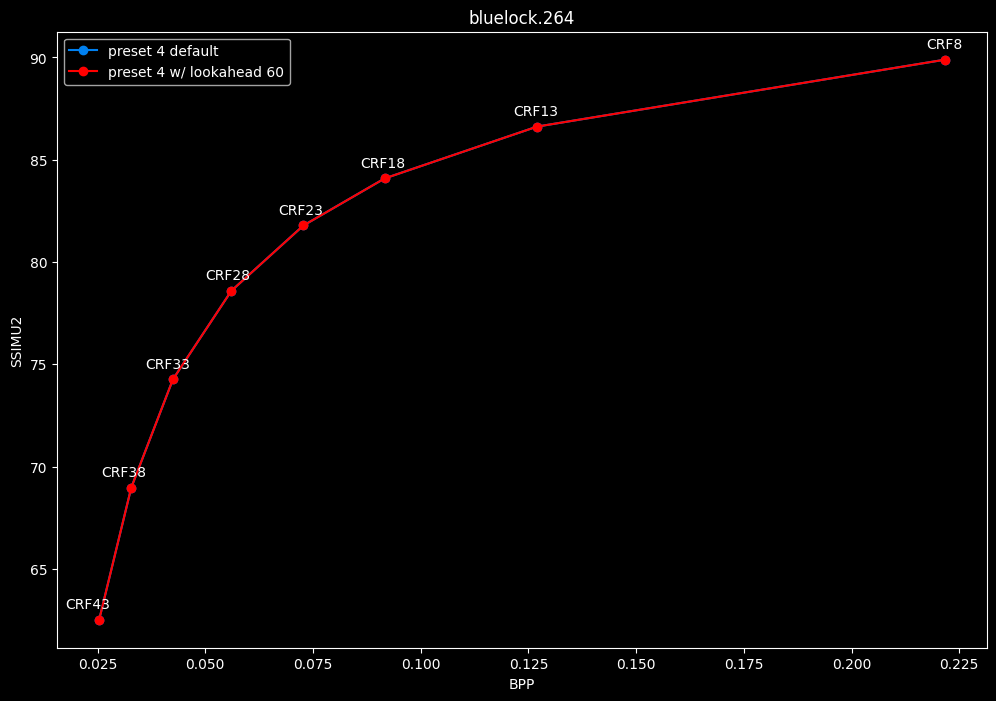
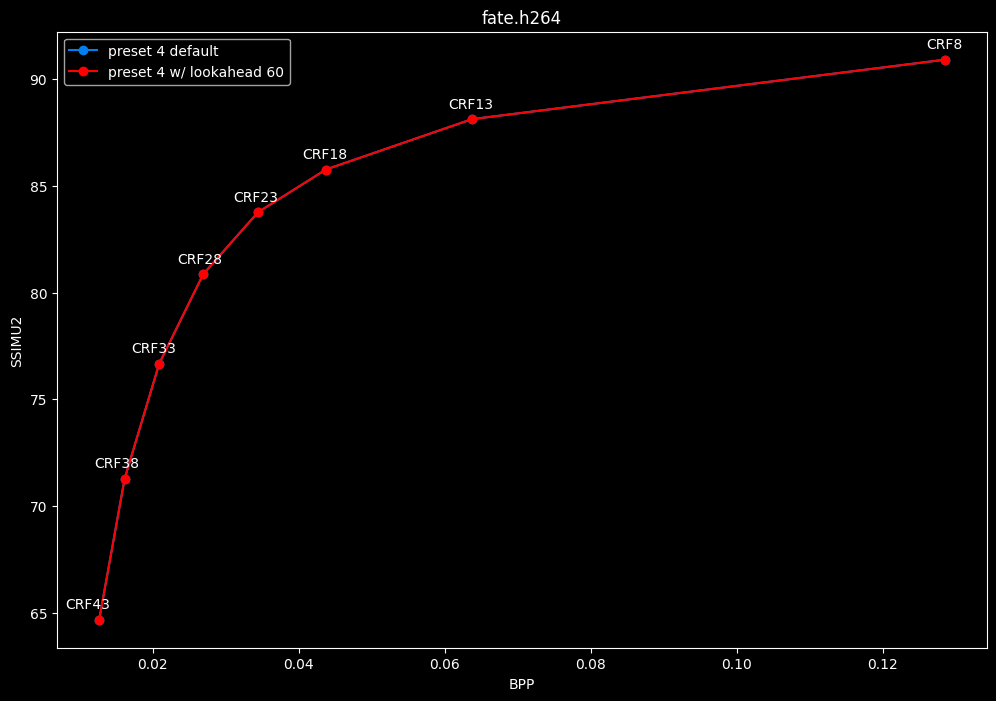
- Speed graphs:
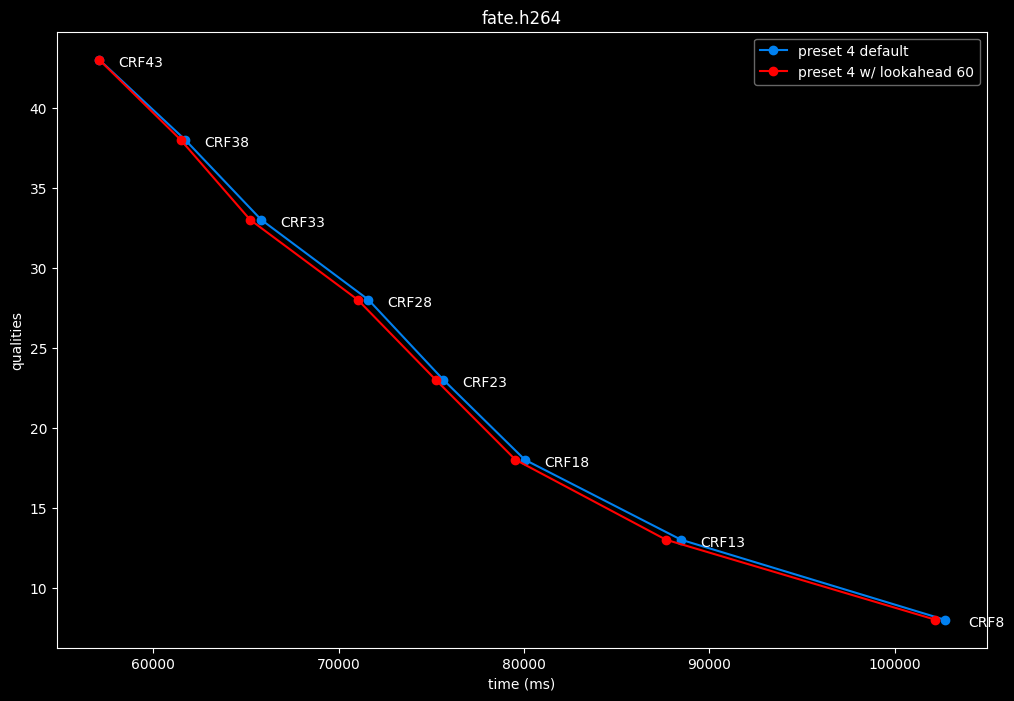
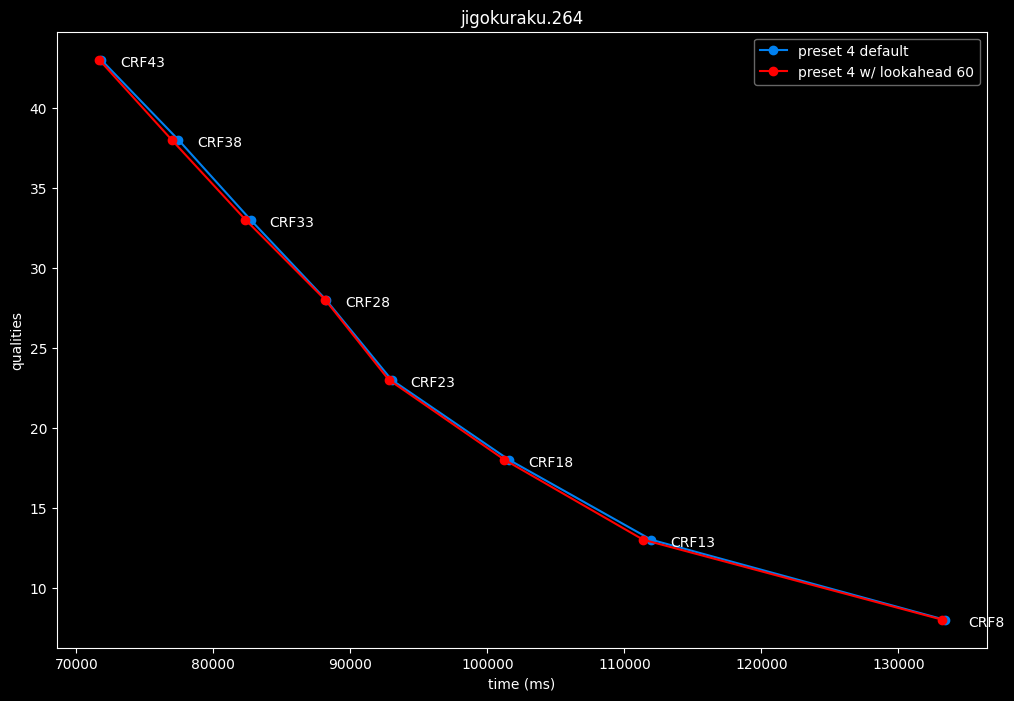
--lookahead 120 (max) vs default --lookahead -1 (auto)
- Efficiency graphs:
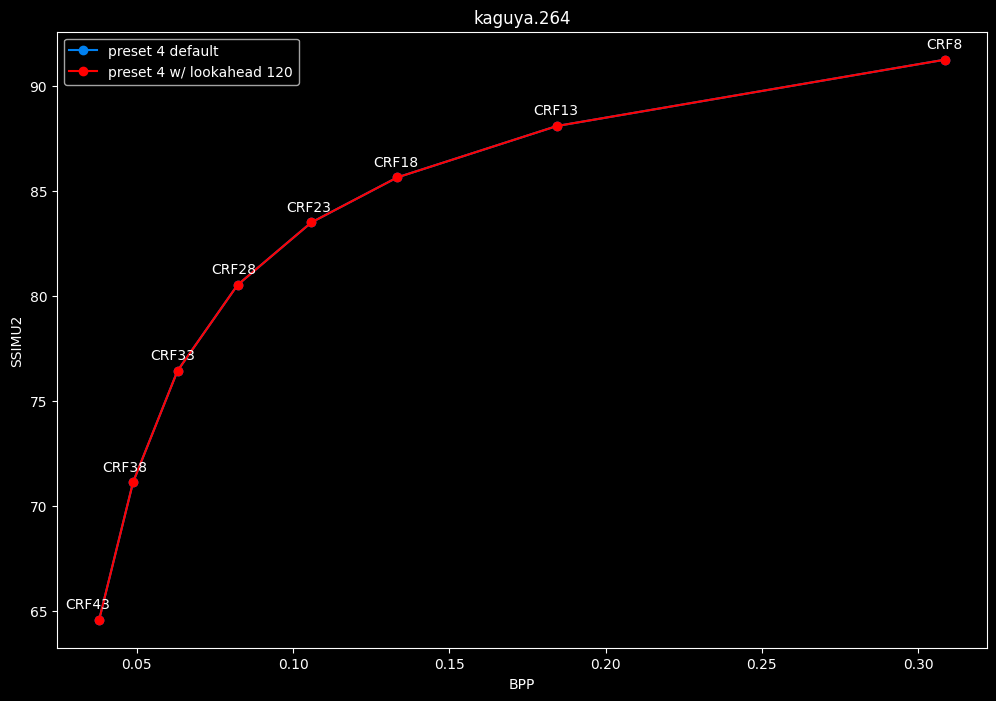
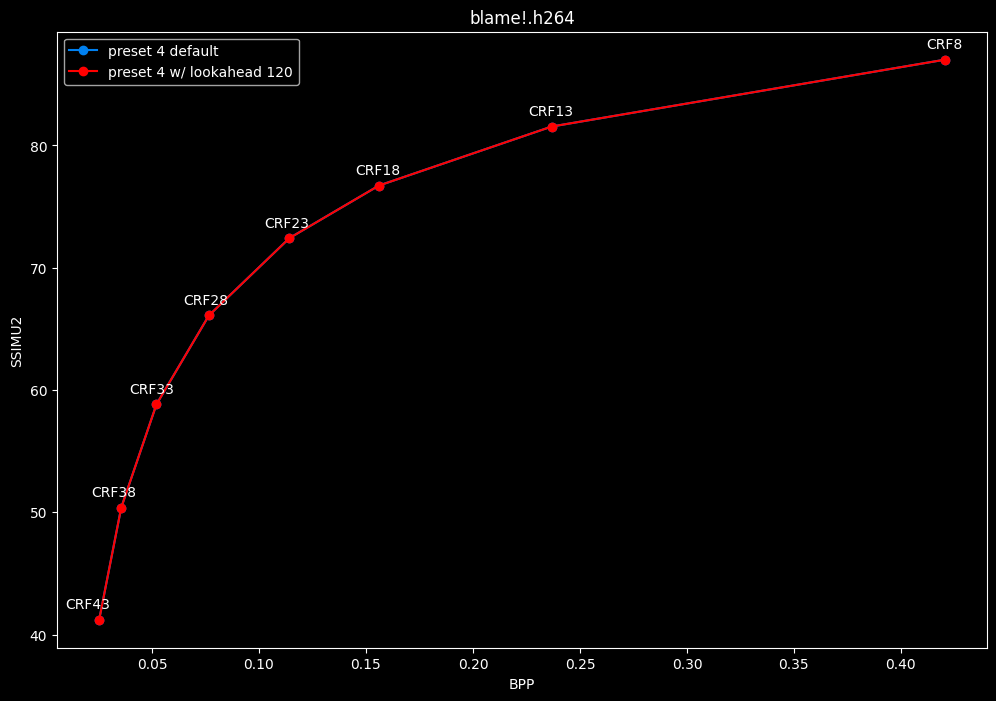
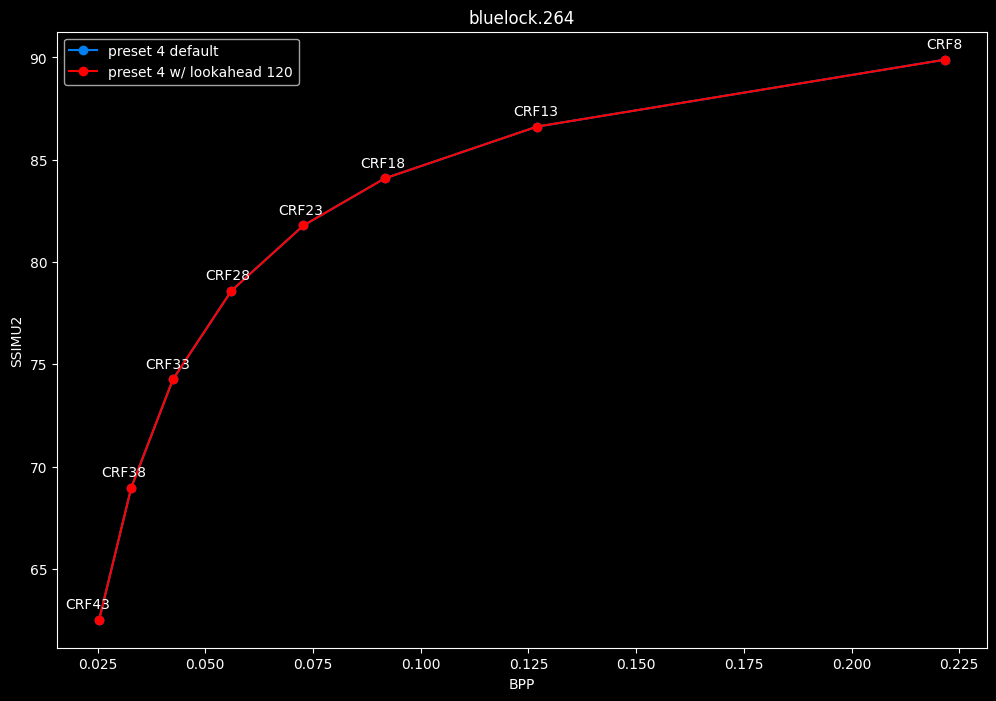
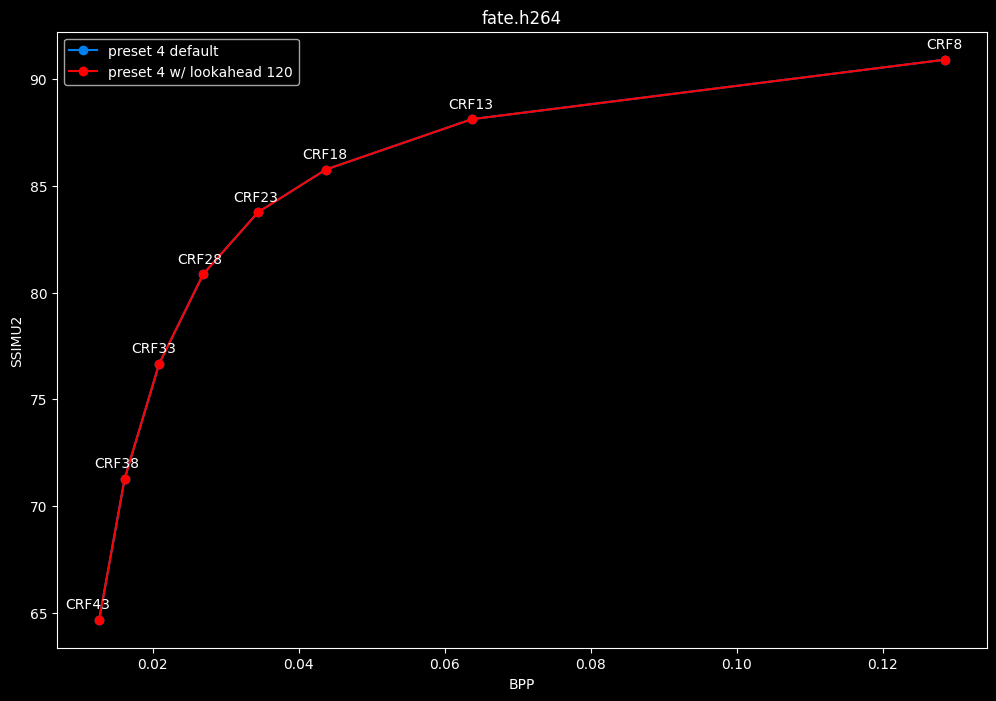
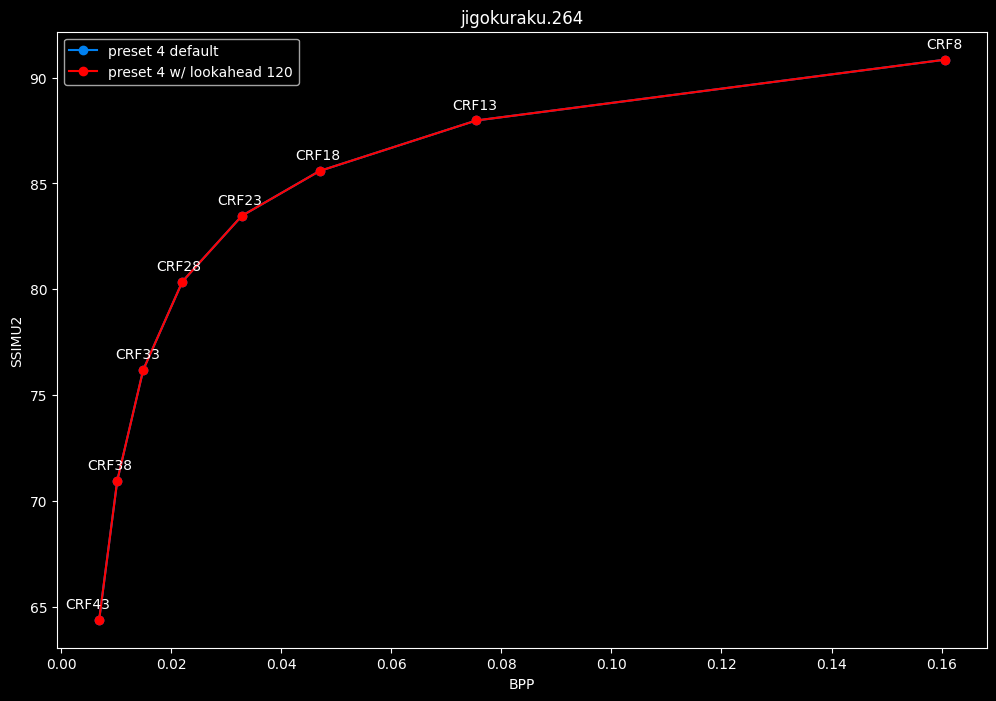
- Speed graphs:
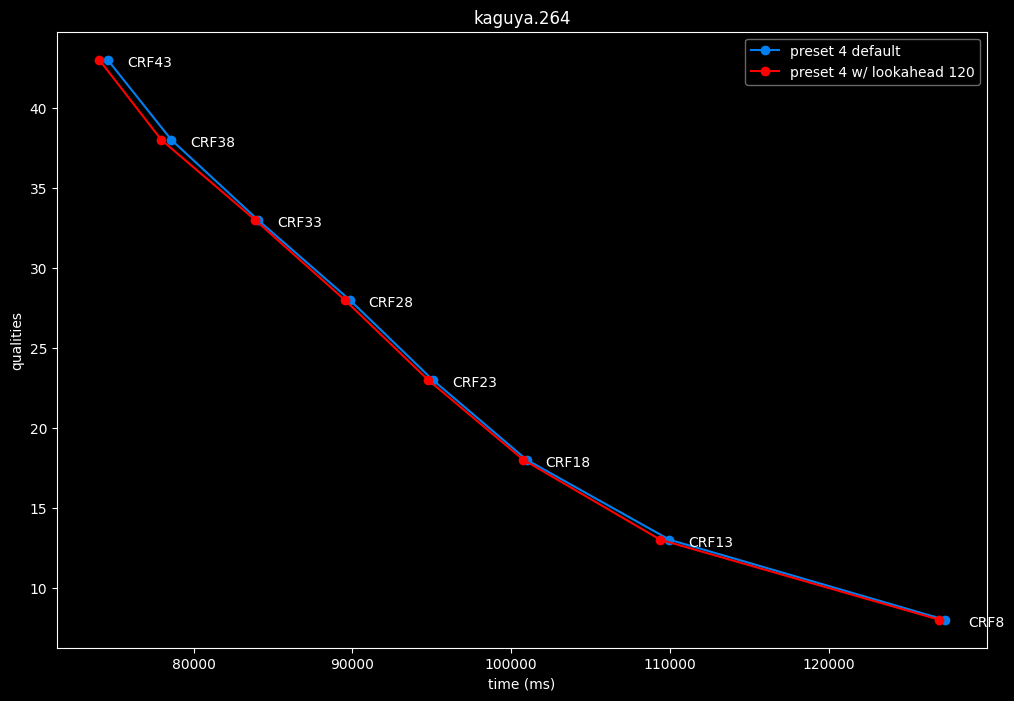
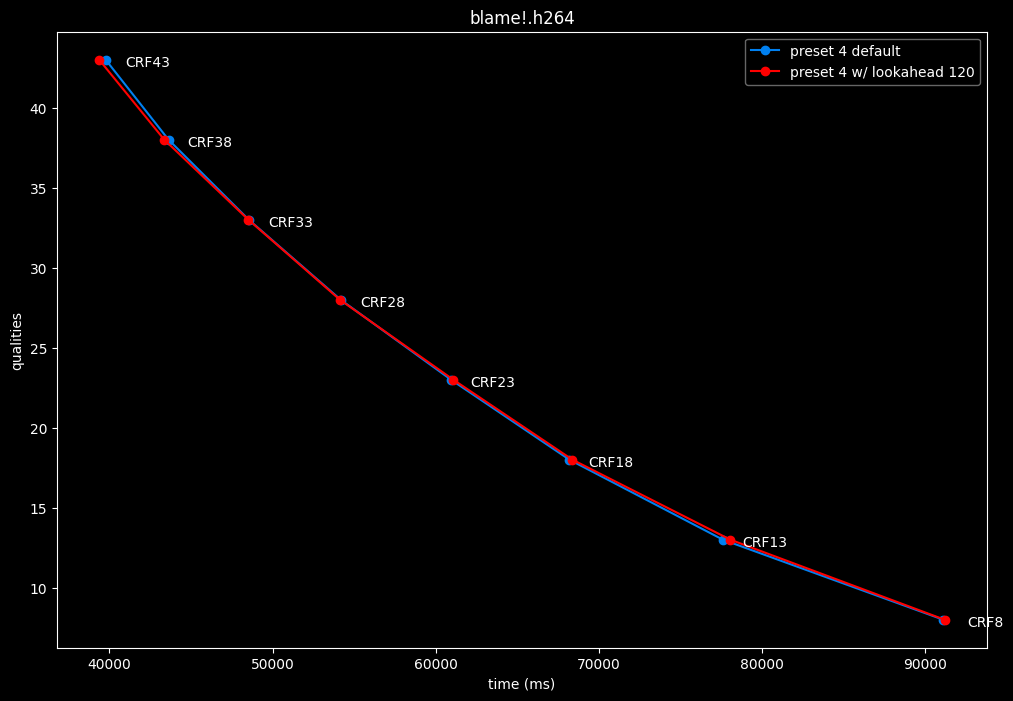
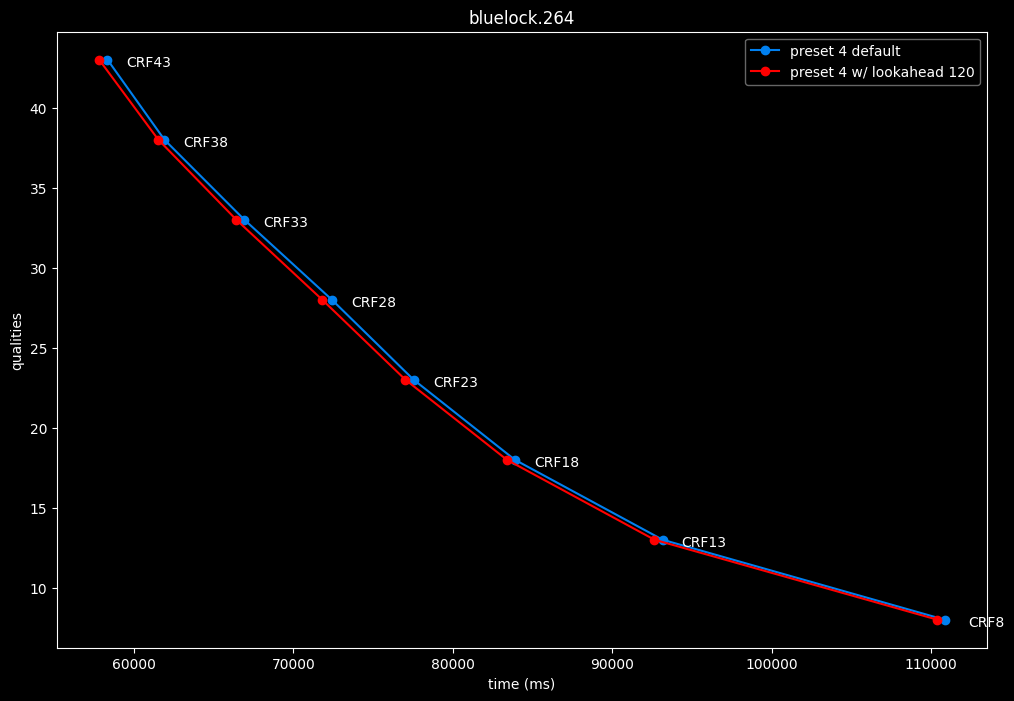
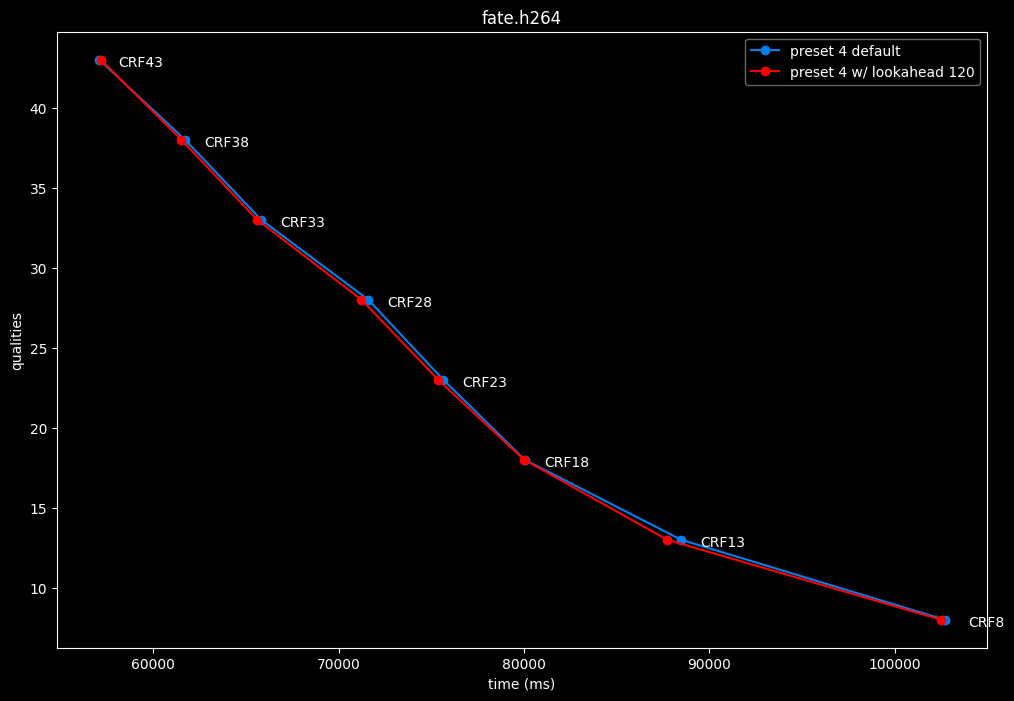
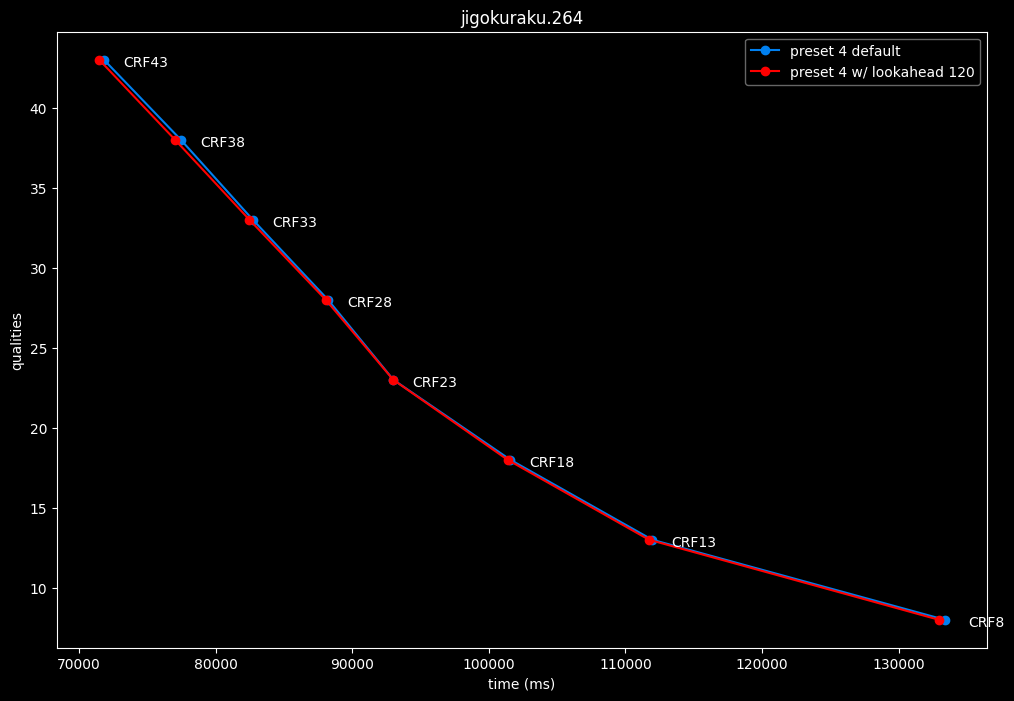
lookahead seems to behave strangely when set...
- lookahead 0 shifts quality around a lot and it is difficult to draw conclusions but there's a clear speed drawback of disabling lookahead.
- lookahead 60 is perfectly bit-perfect to every clips EXCEPT for some damn reason in Jigokuraku at CRF23
- lookahead 120 is somehow also bit-perfect, but this time in every clips and every CRF levels. Both 60 and 120 don't see much speed differences.
Soooo.... this behavior is so odd I don't advise to set any lookahead value. Let the encoder decide.
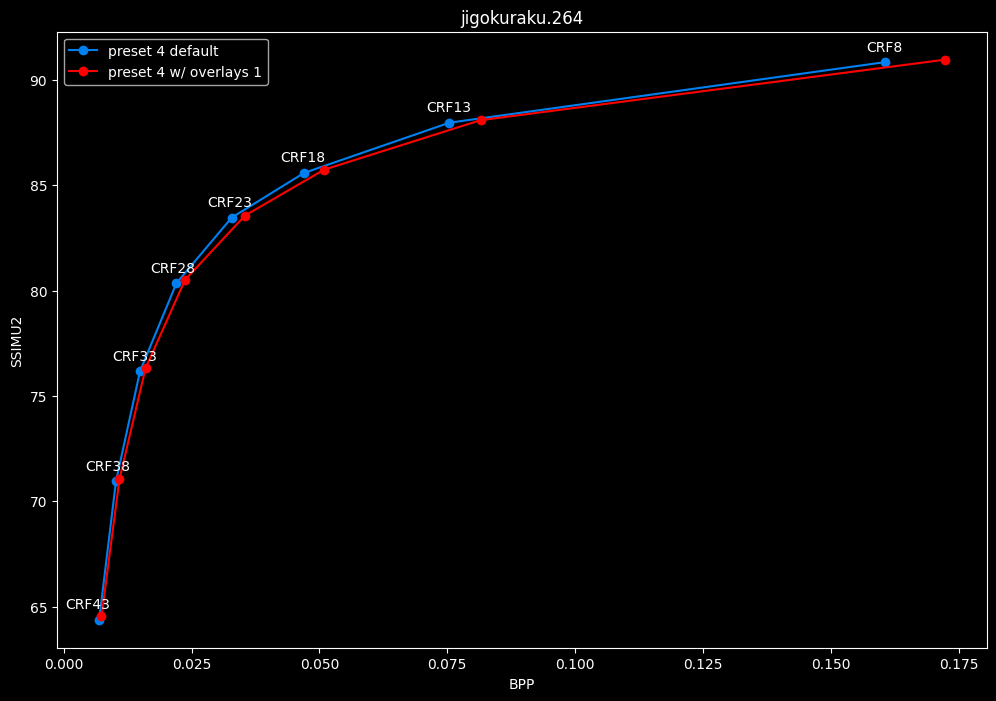
--enable-overlays 1 vs default --enable-overlays 0
- Efficiency graphs:
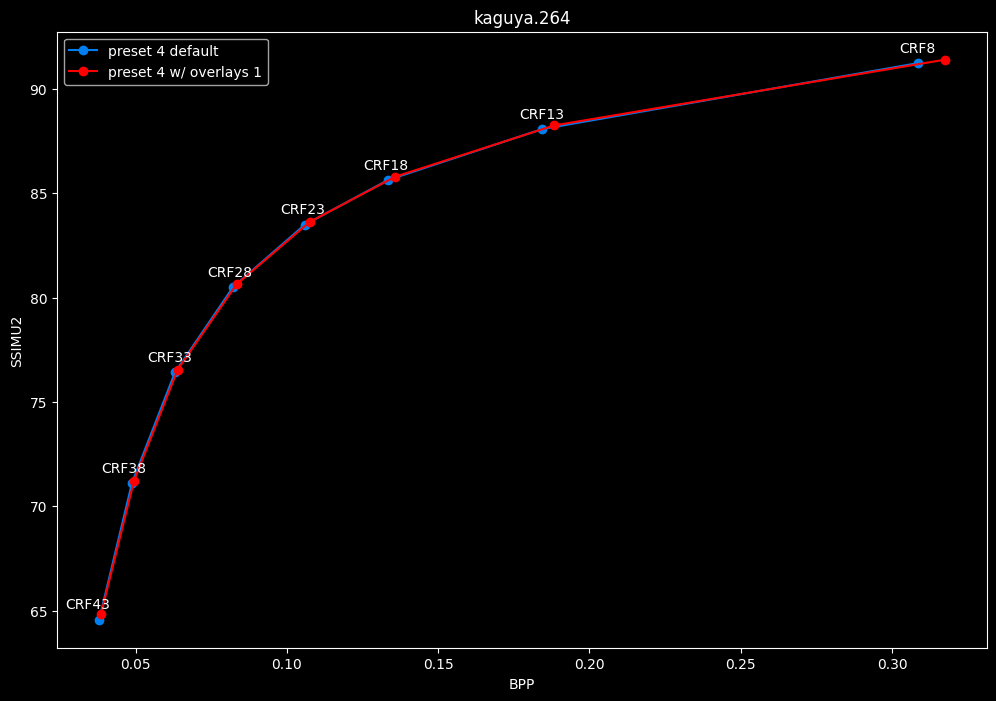
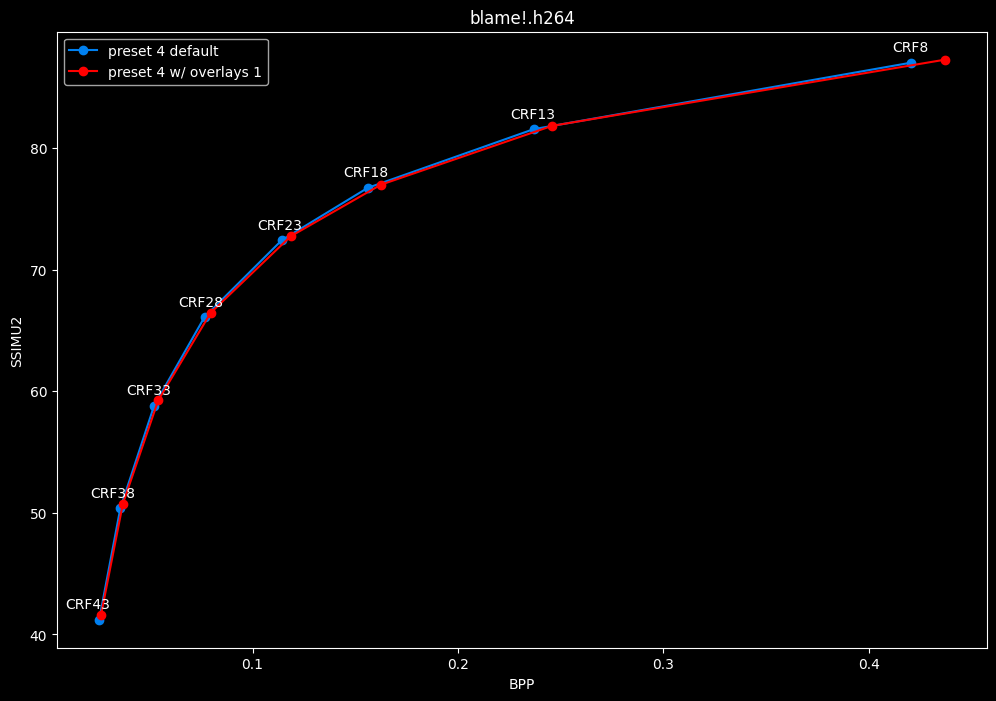
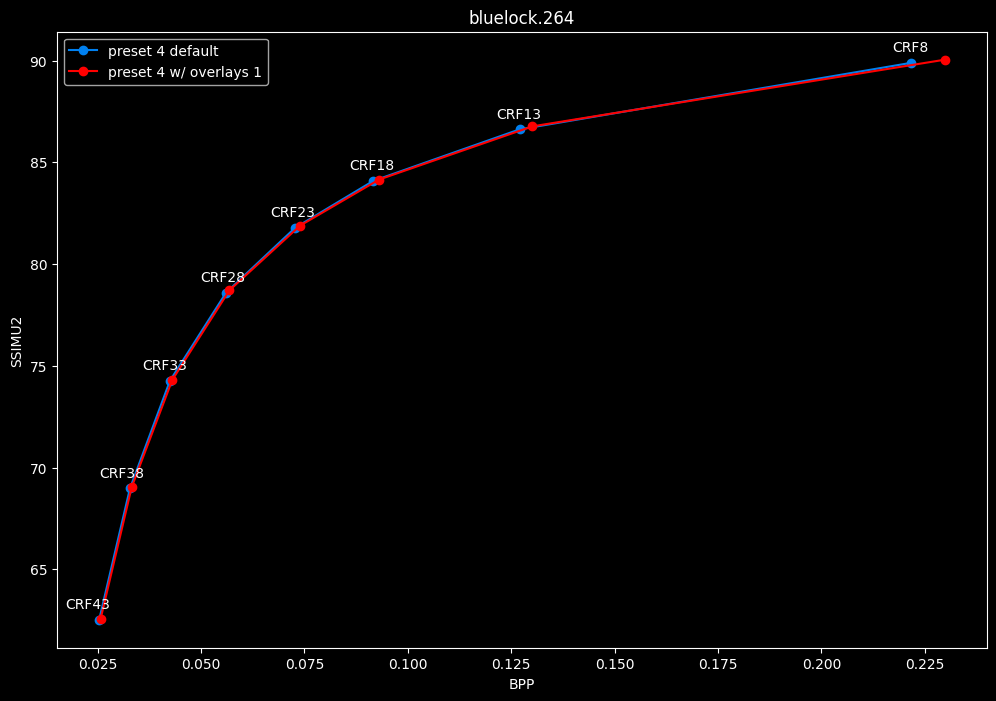
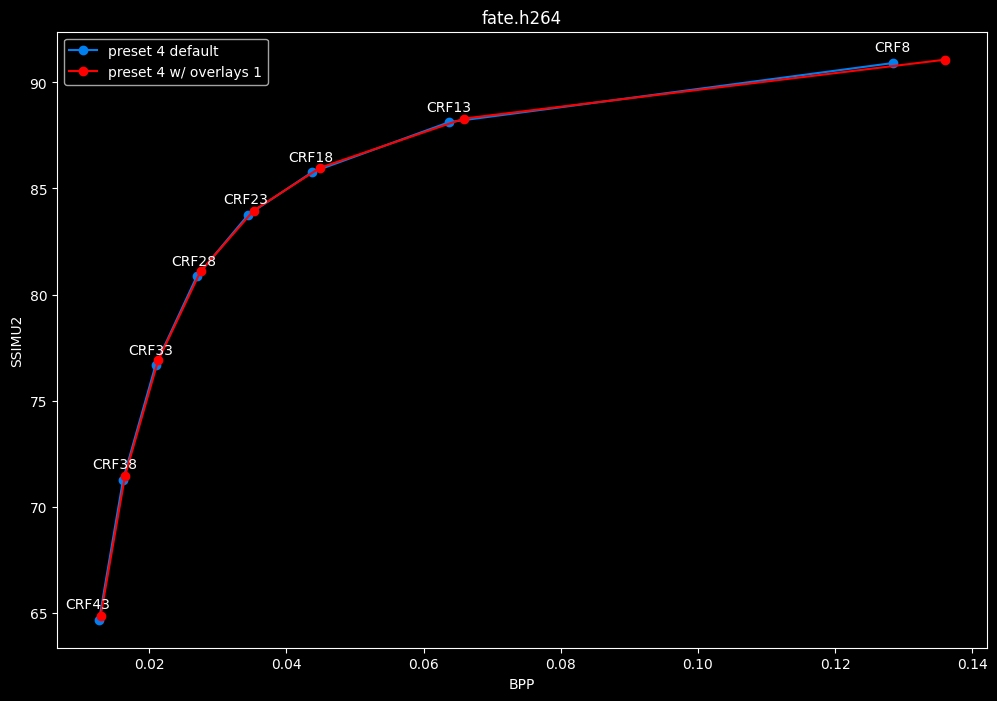
- Speed graphs:
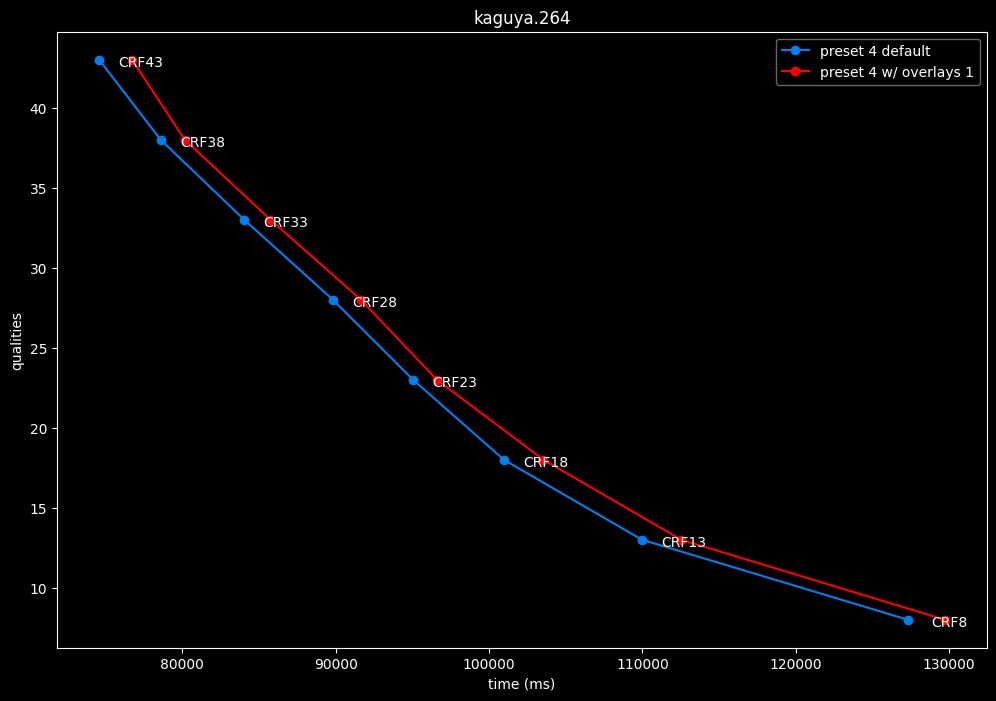
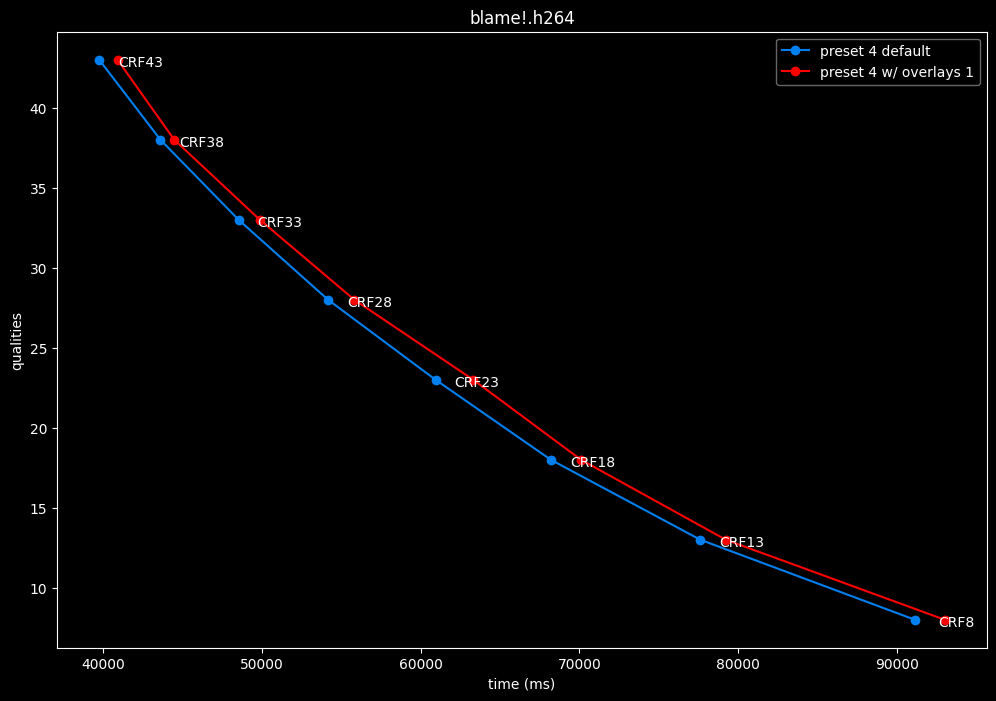
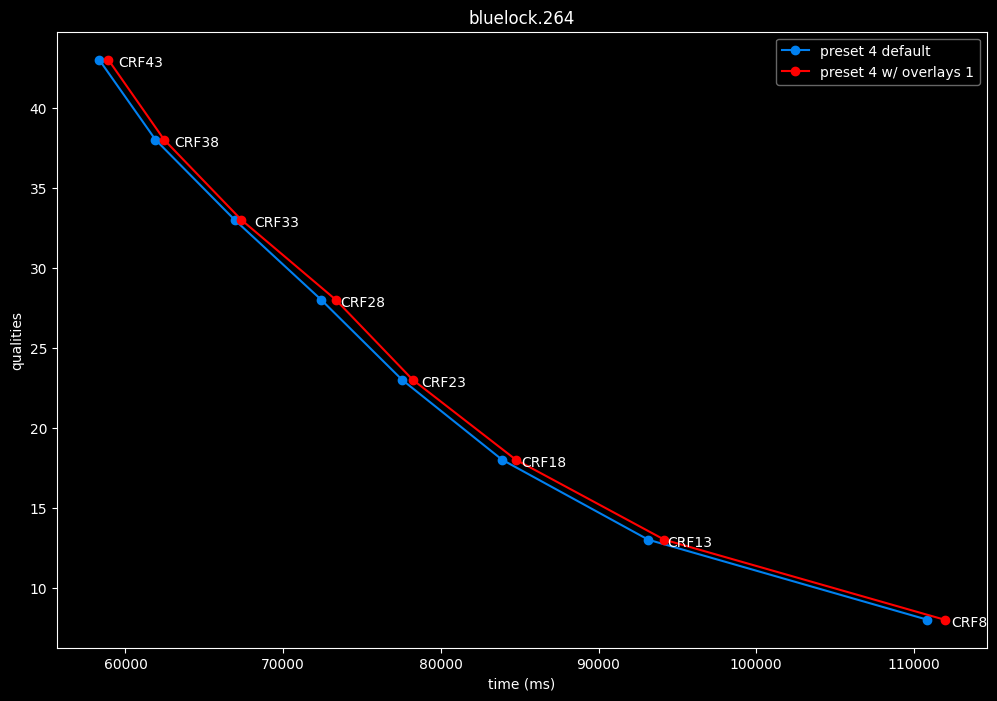
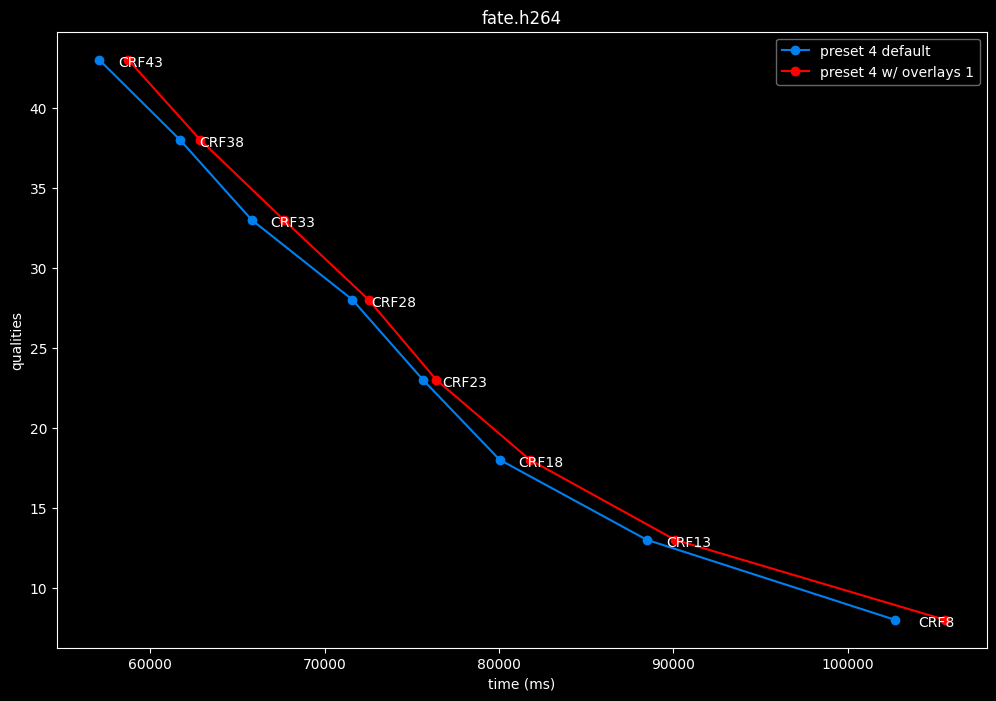
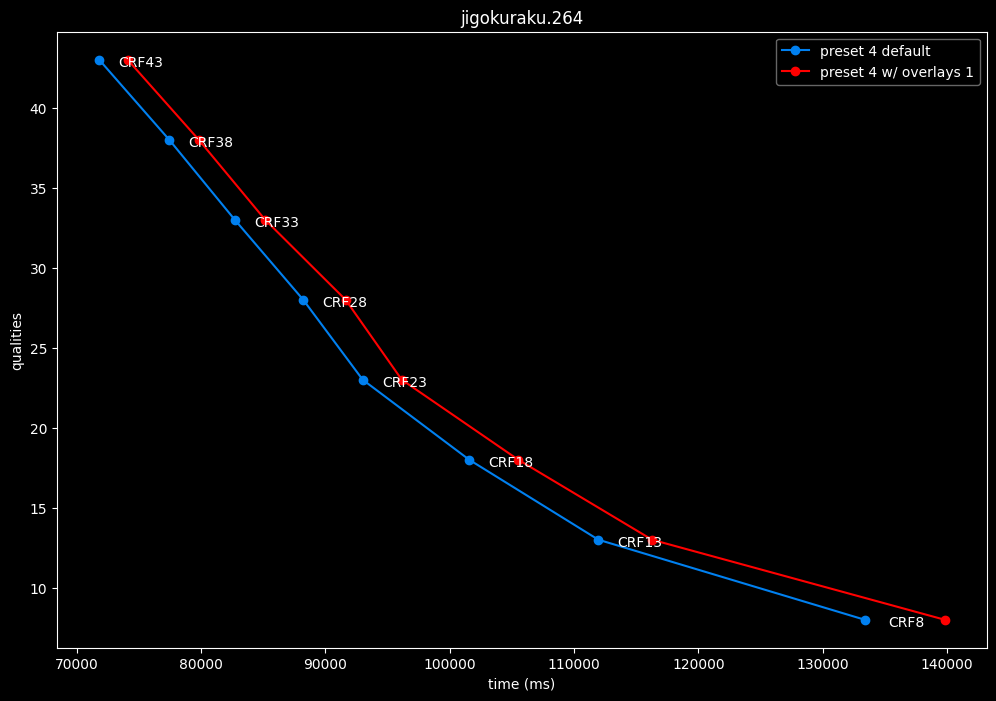
overlays do not seem to either improve efficiency or performance.
--enable-qm 1 vs default --enable-qm 0
- Efficiency graphs:
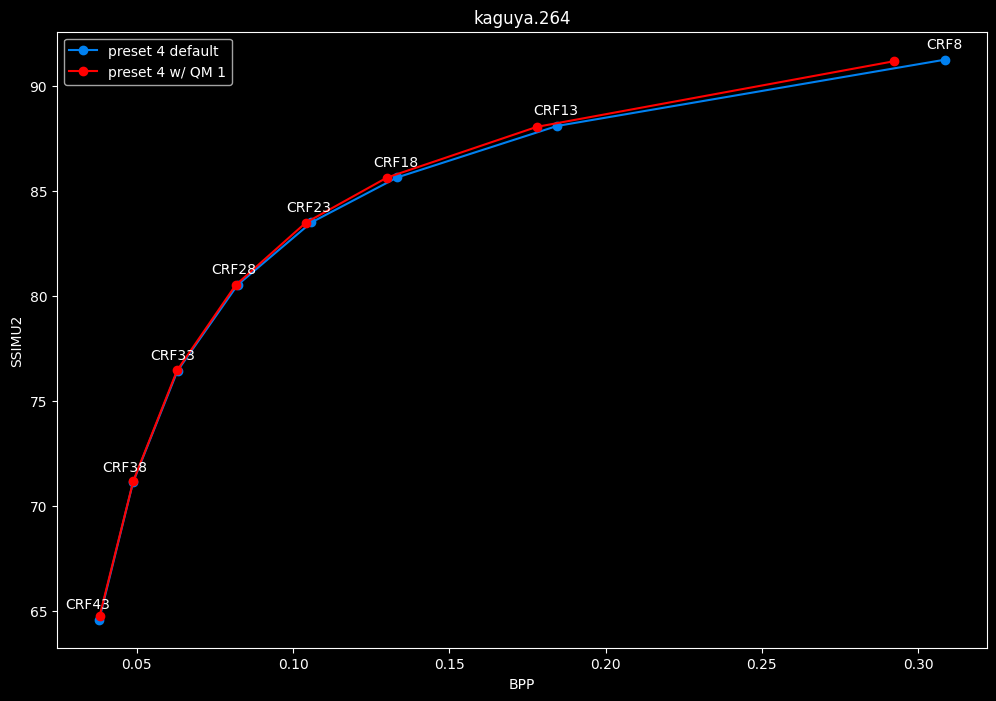
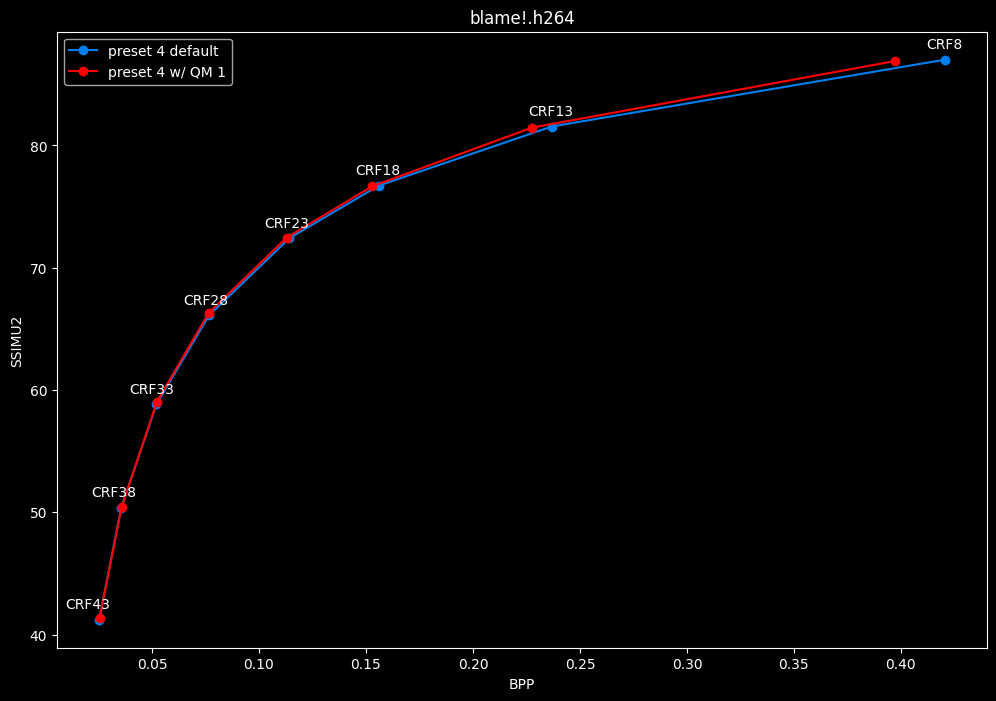
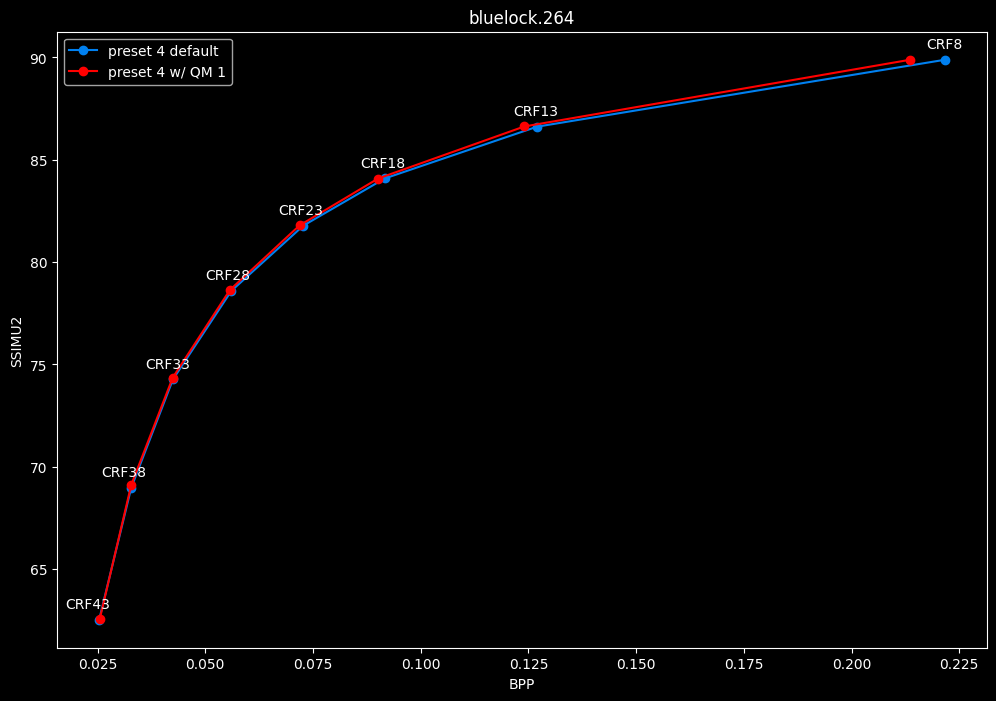
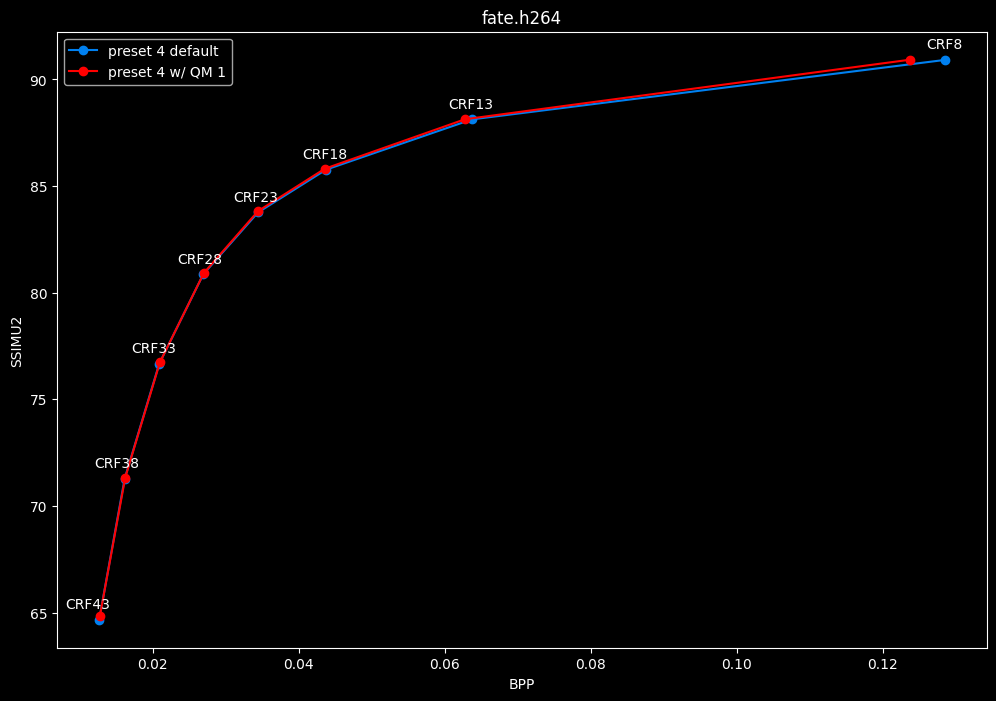
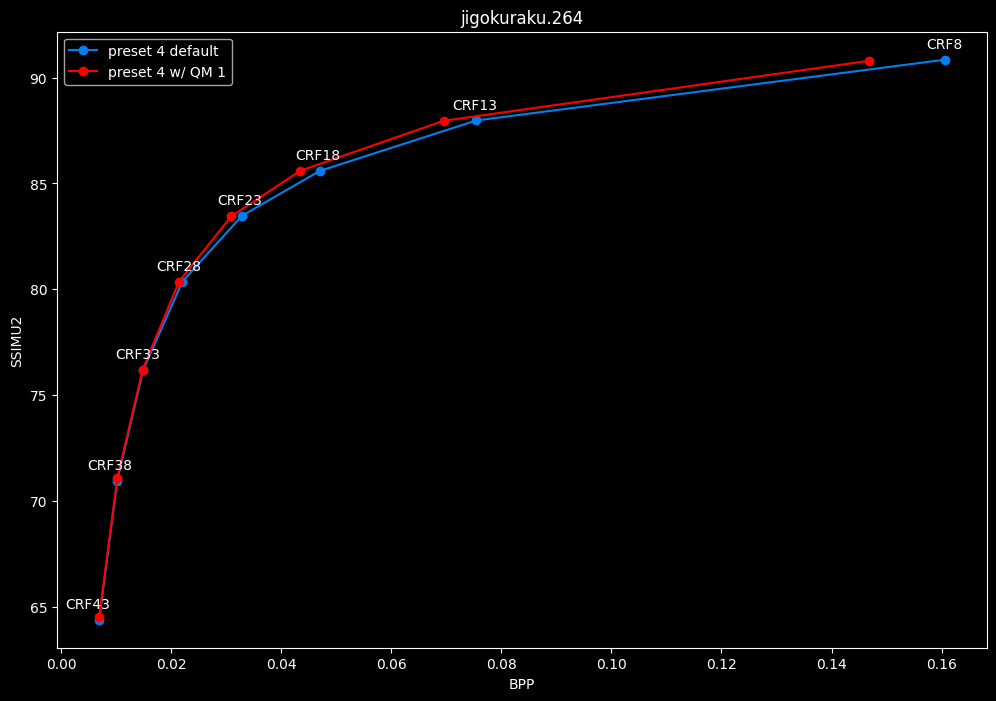
- Speed graphs:
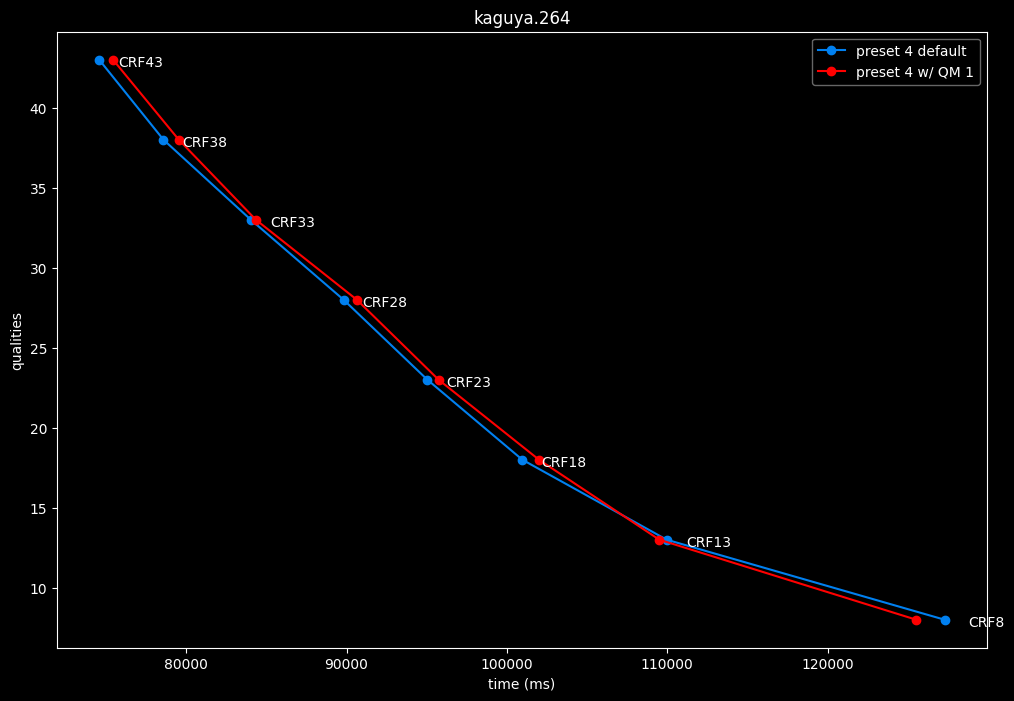
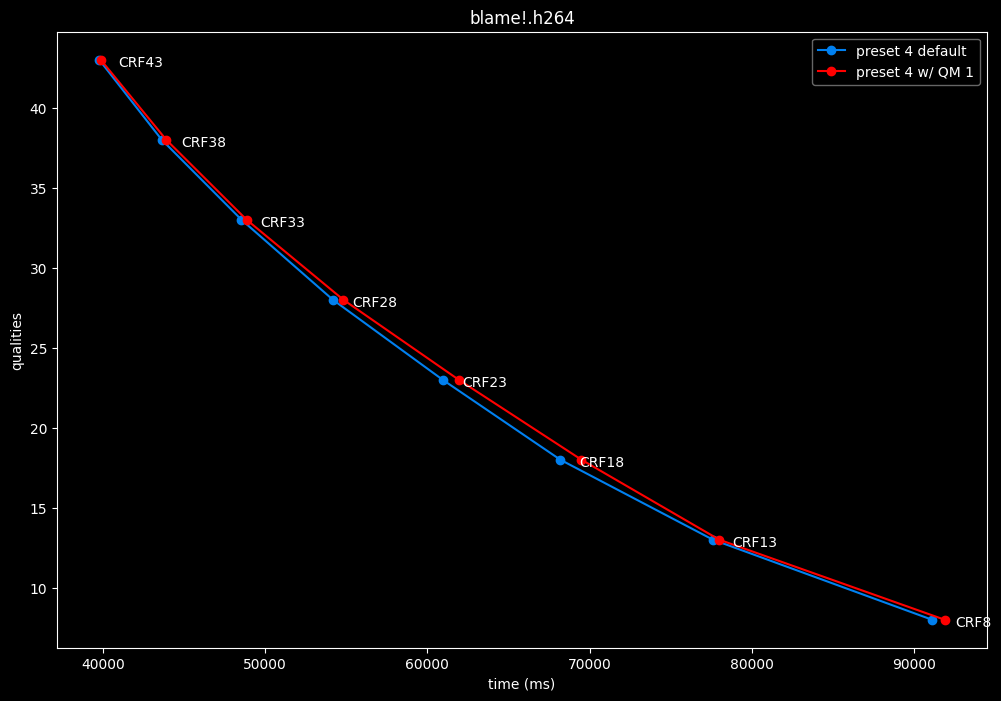
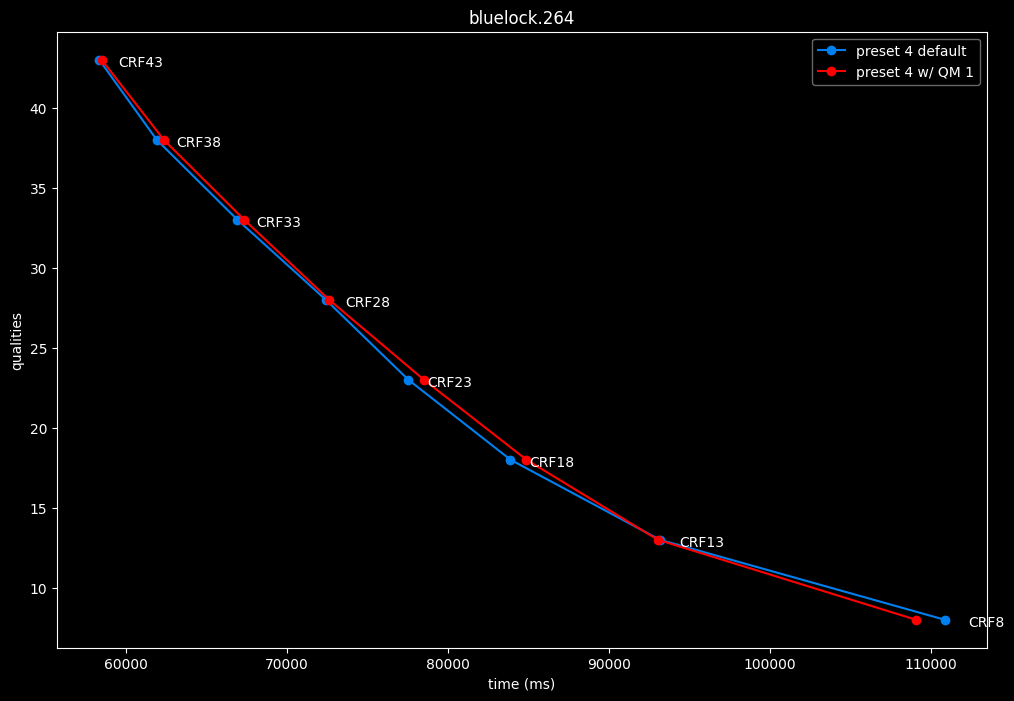
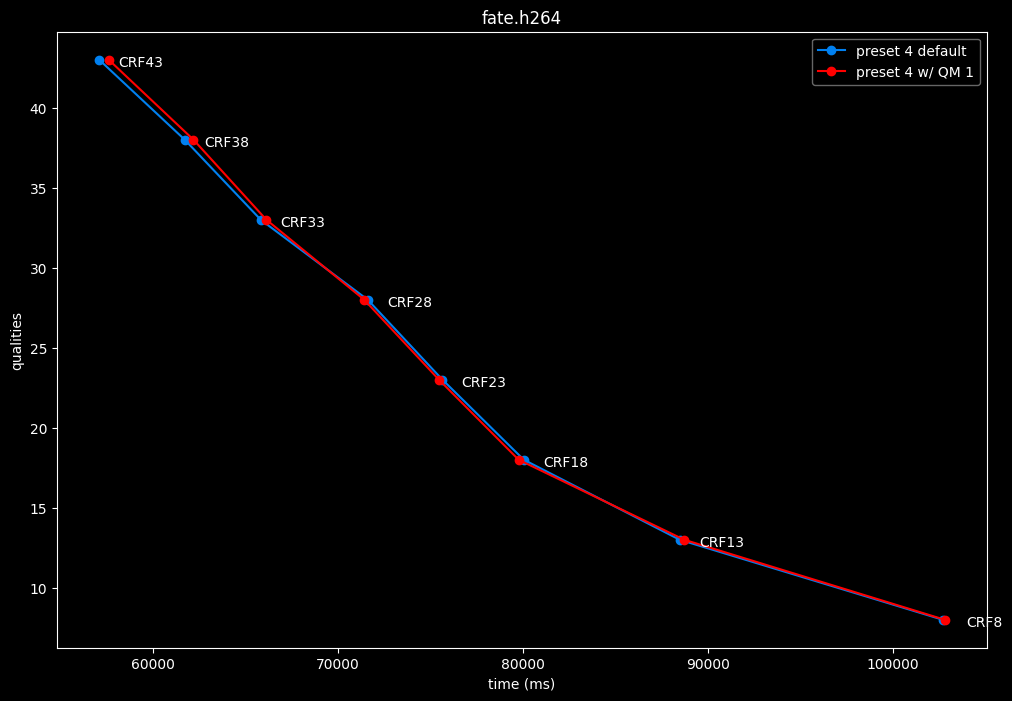
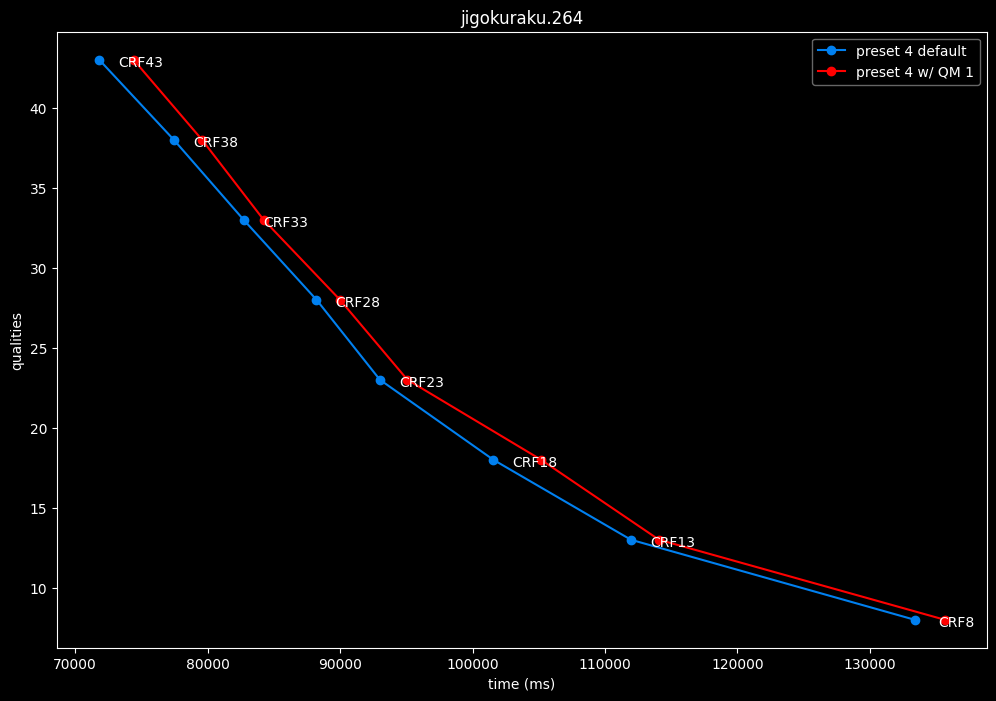
Enabling quantization matrices alone increase efficiency at "high quality" with no real speed impact.
--enable-qm 1 --qm-min 0 vs --enable-qm 1
- Efficiency graphs:
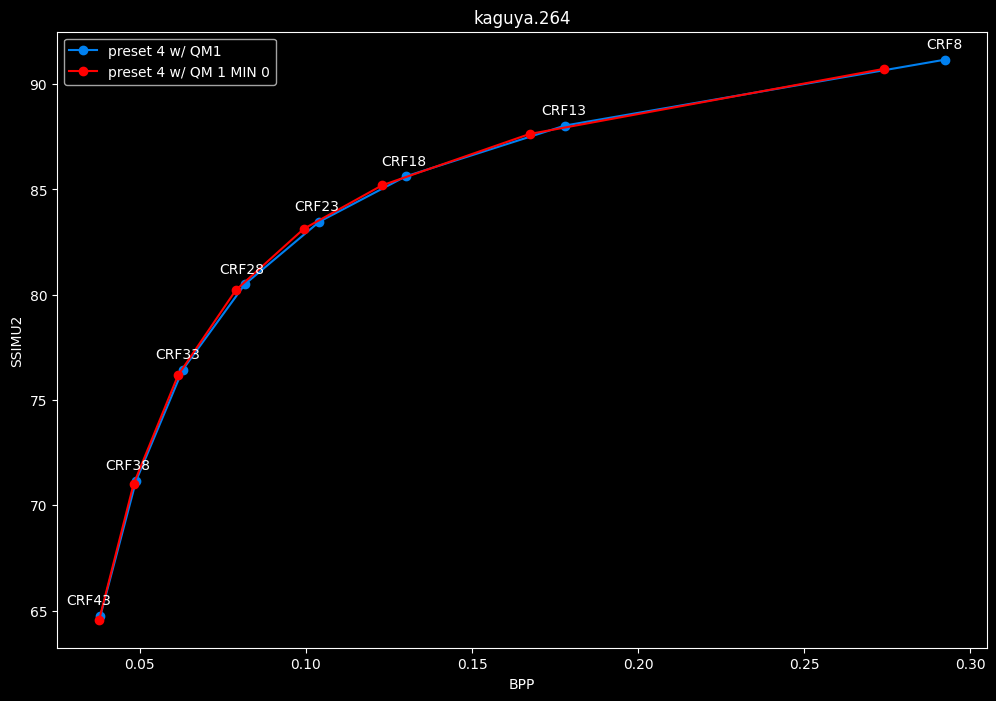
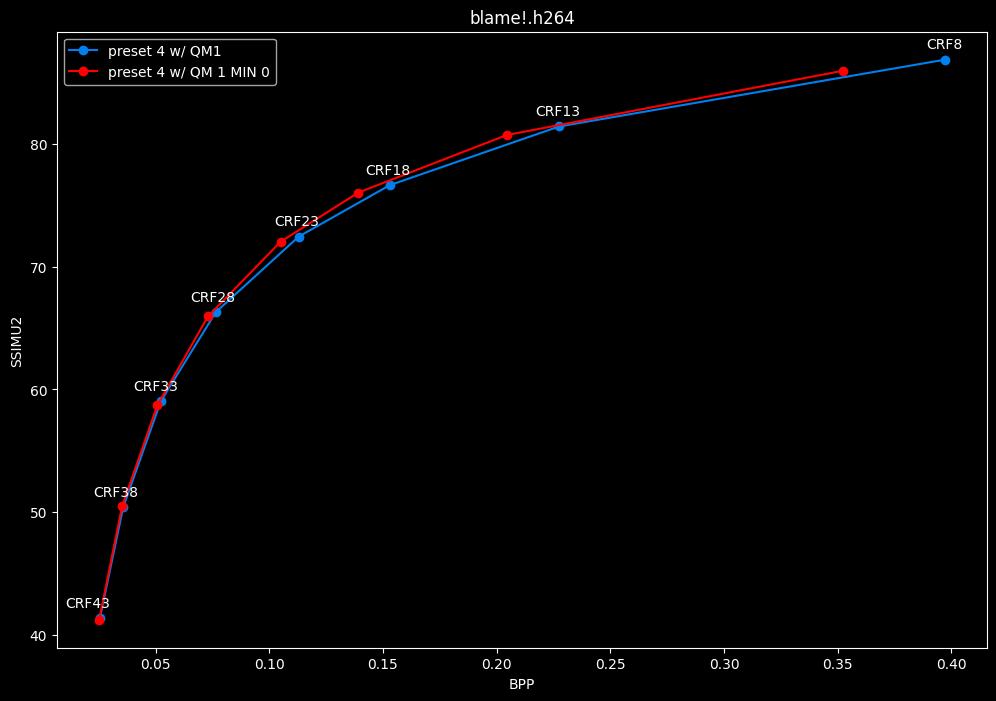
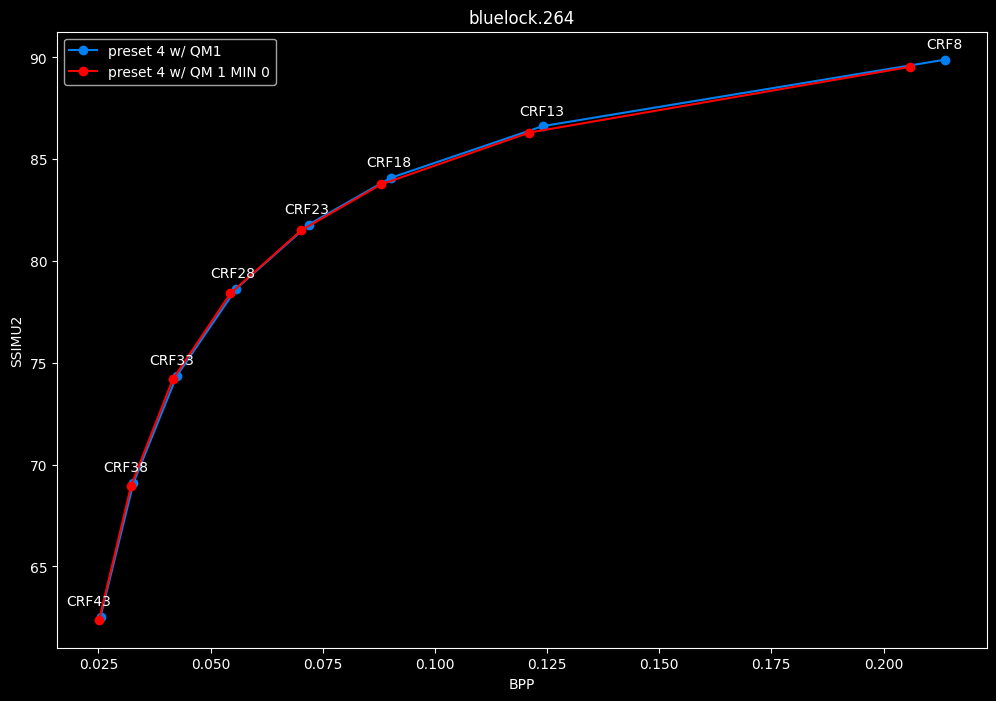
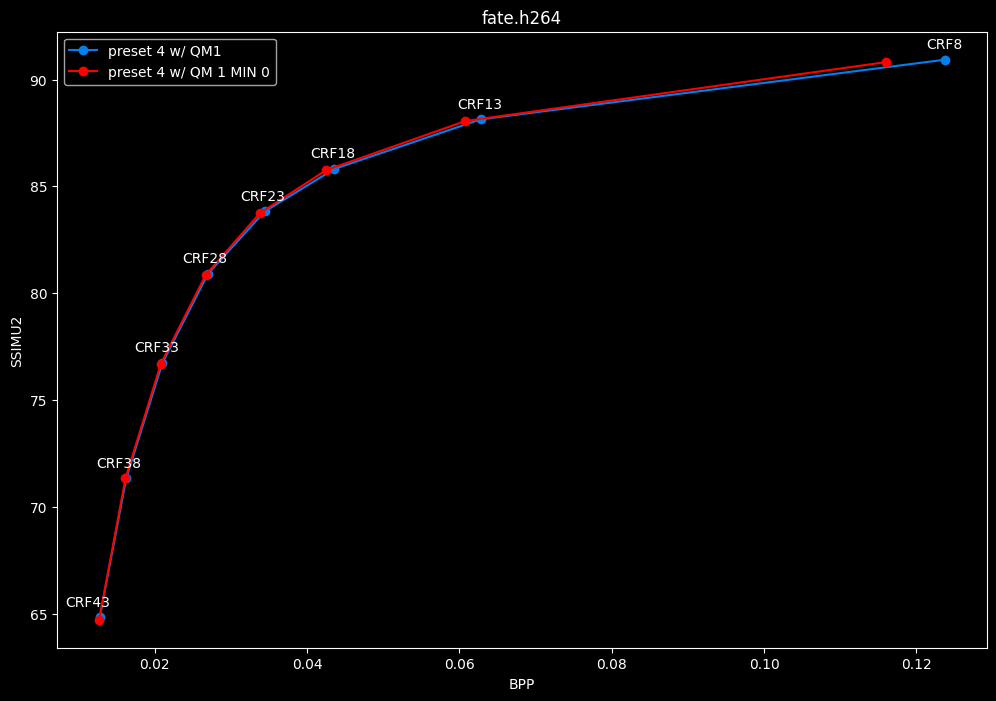
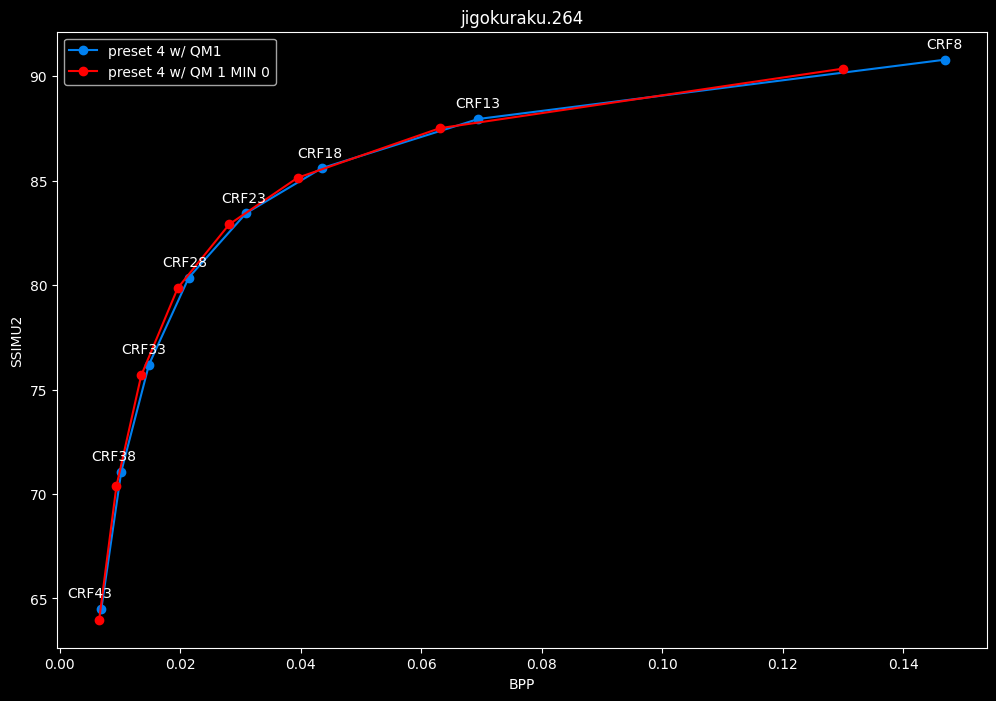
- Speed graphs:
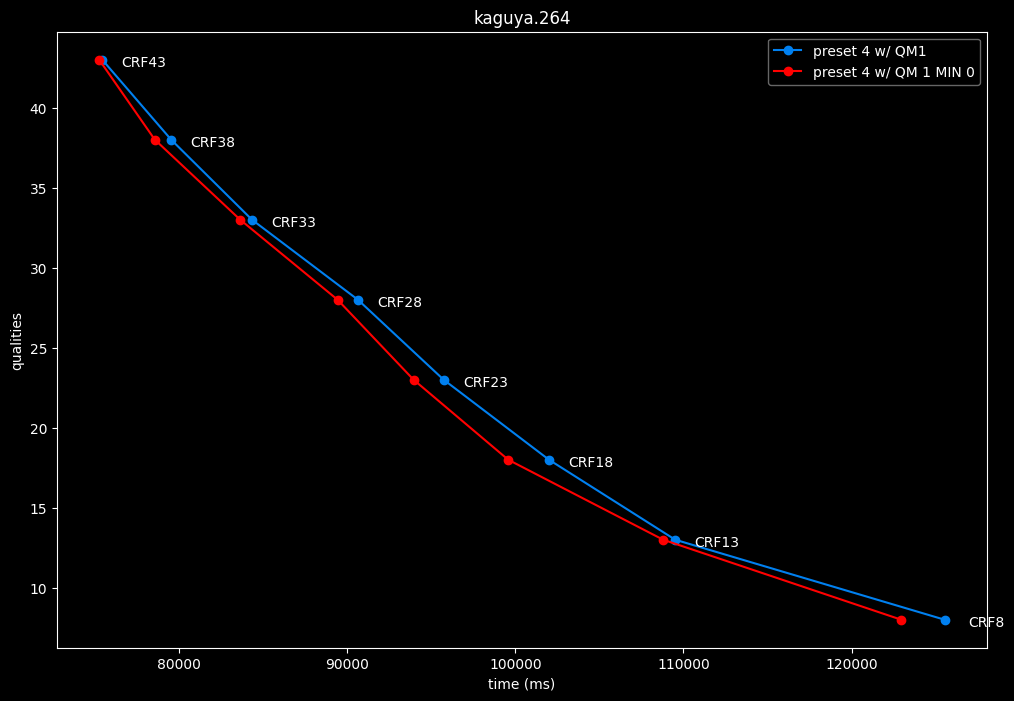
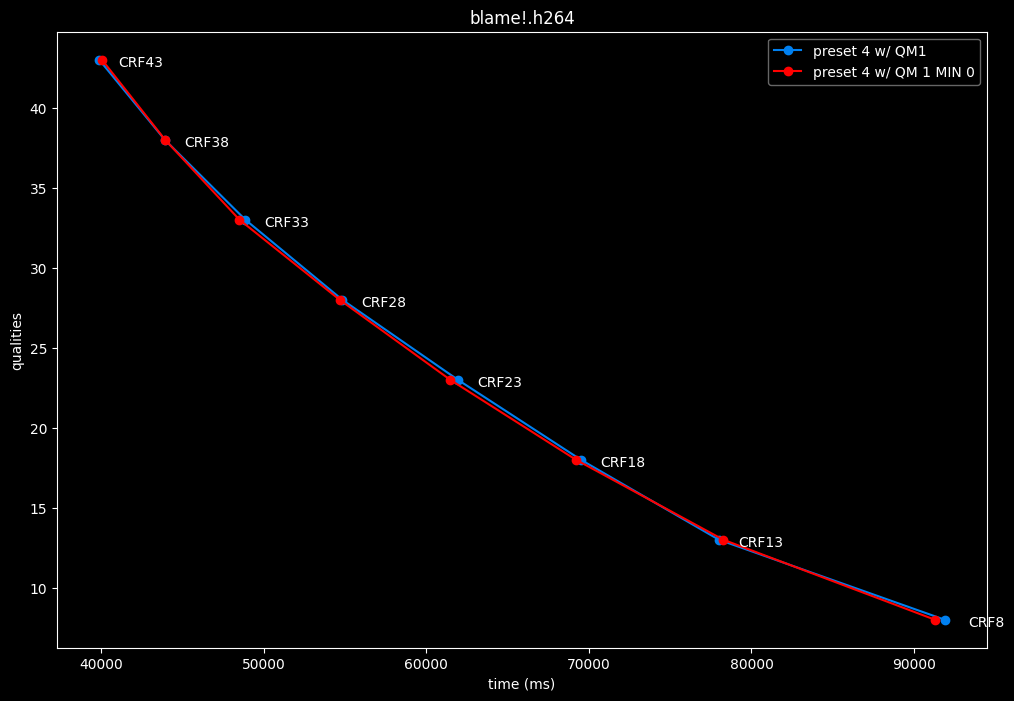
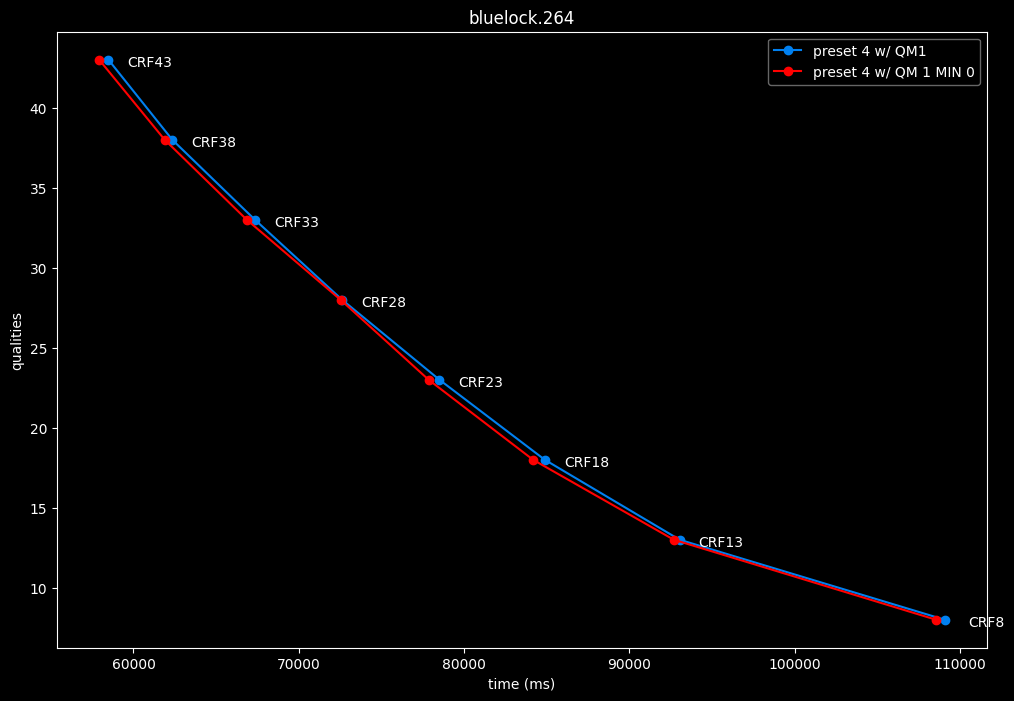
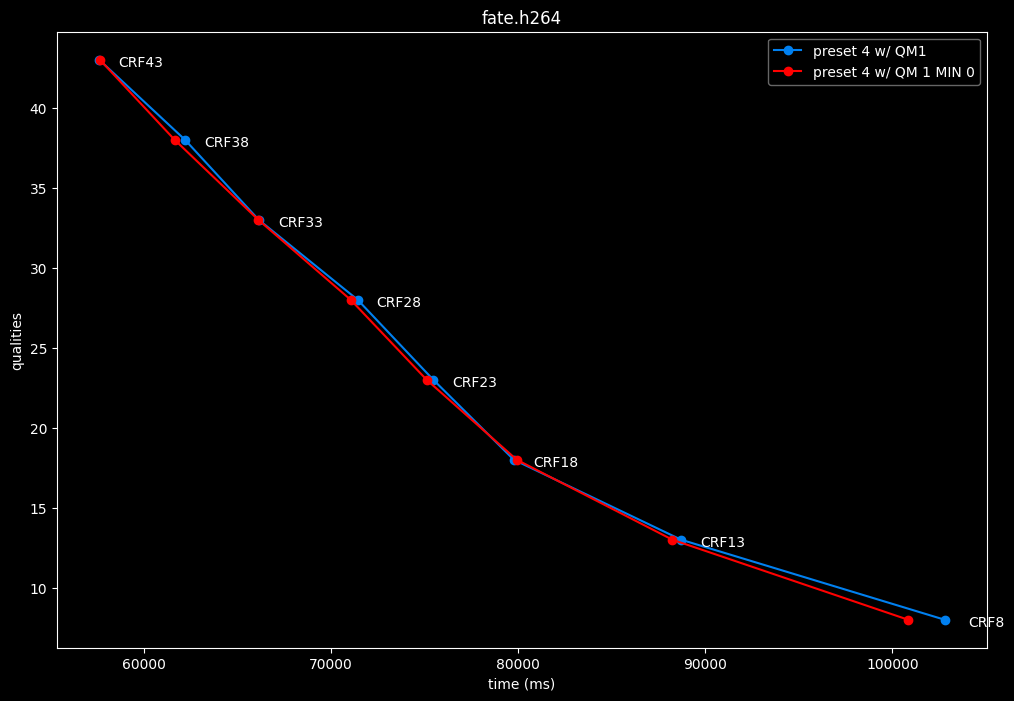
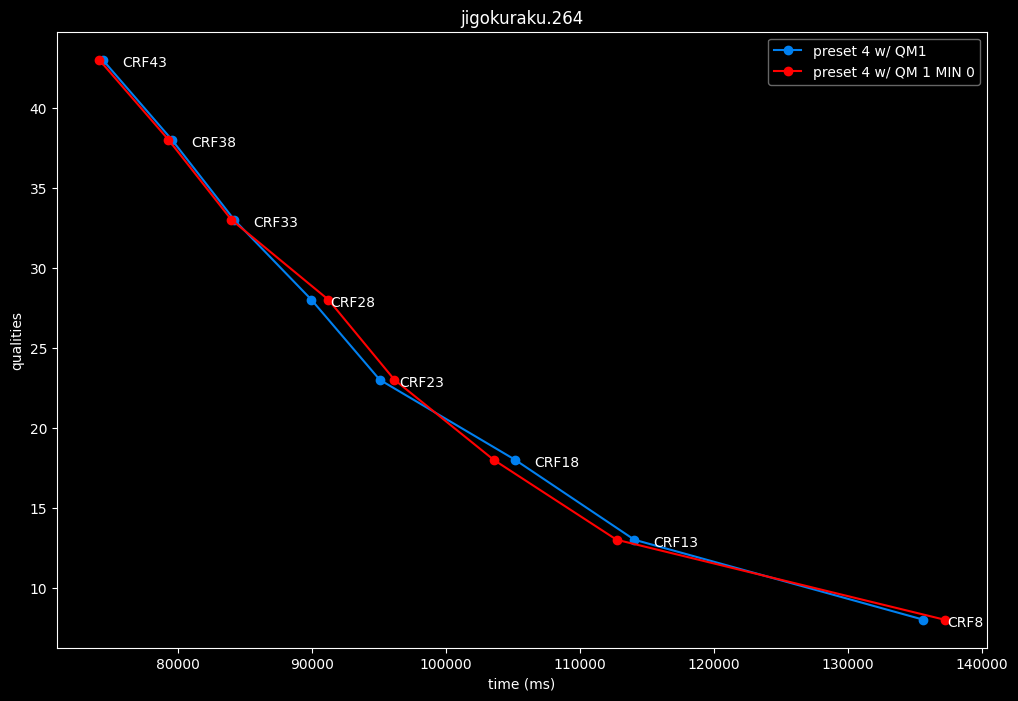
Setting qm-min to 0 on top of enabling quantization matrices can be beneficial in some clips at no added compute time.
I will re-tests many QMs ranges in the future, but I doubt it changed much from v1.7.0 where 0 was the most appropriate choice for most content.
--enable-restoration 0 vs default --enable-restoration 1
- Efficiency graphs:
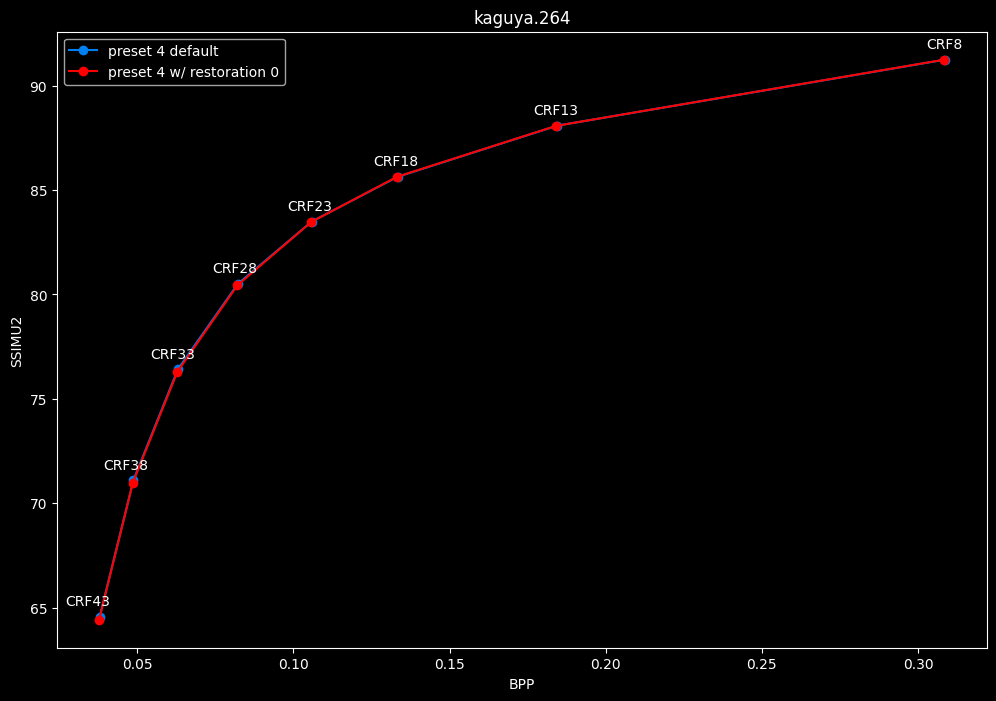
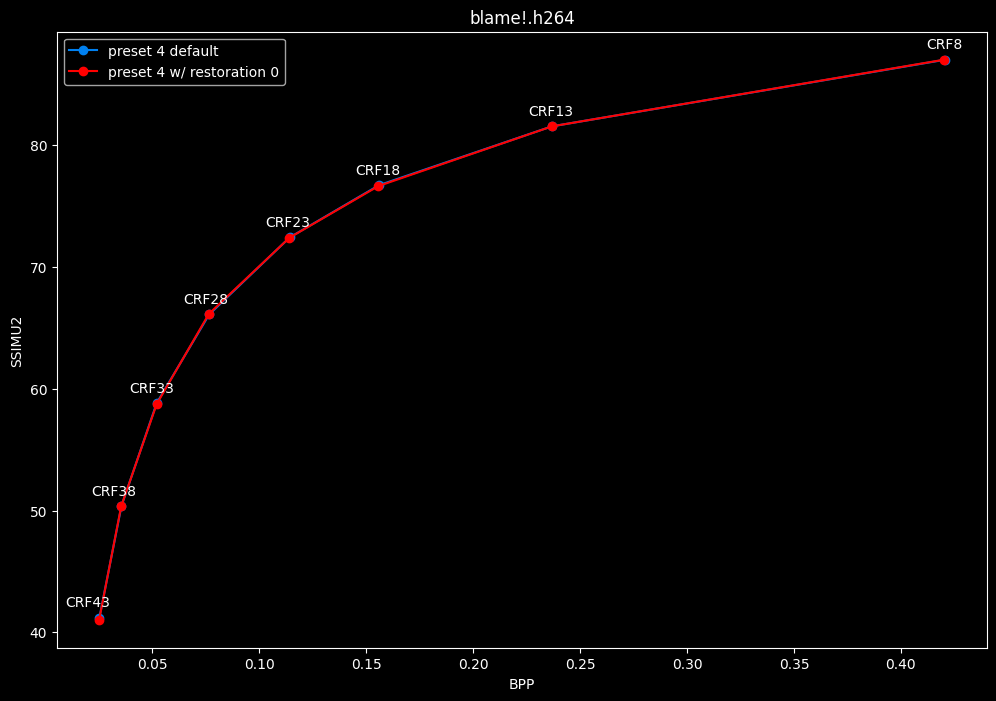
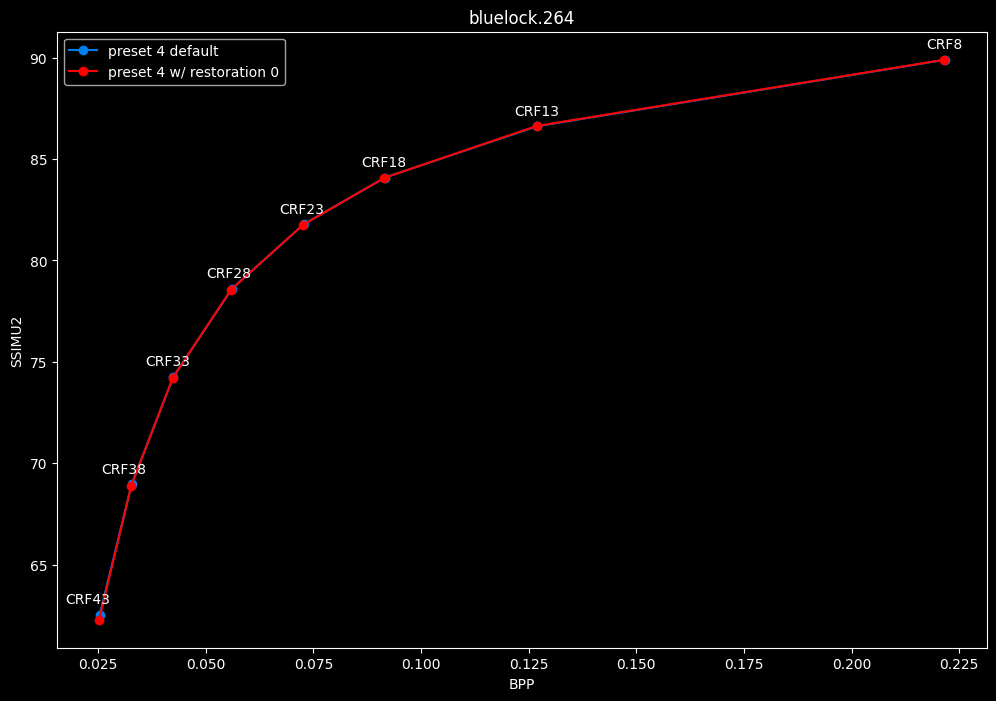
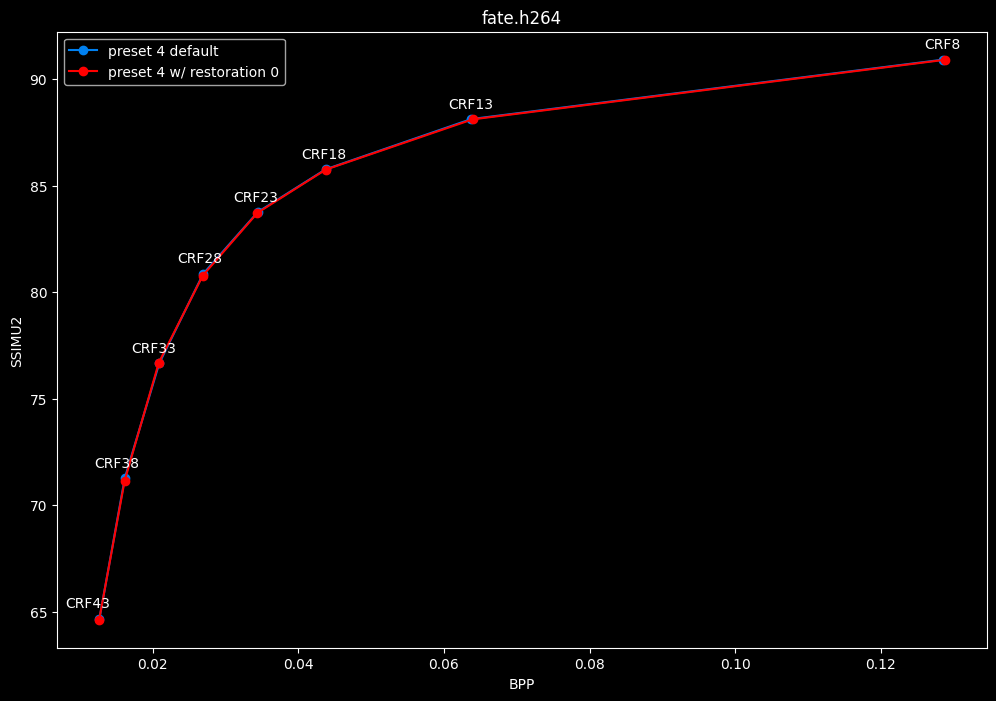
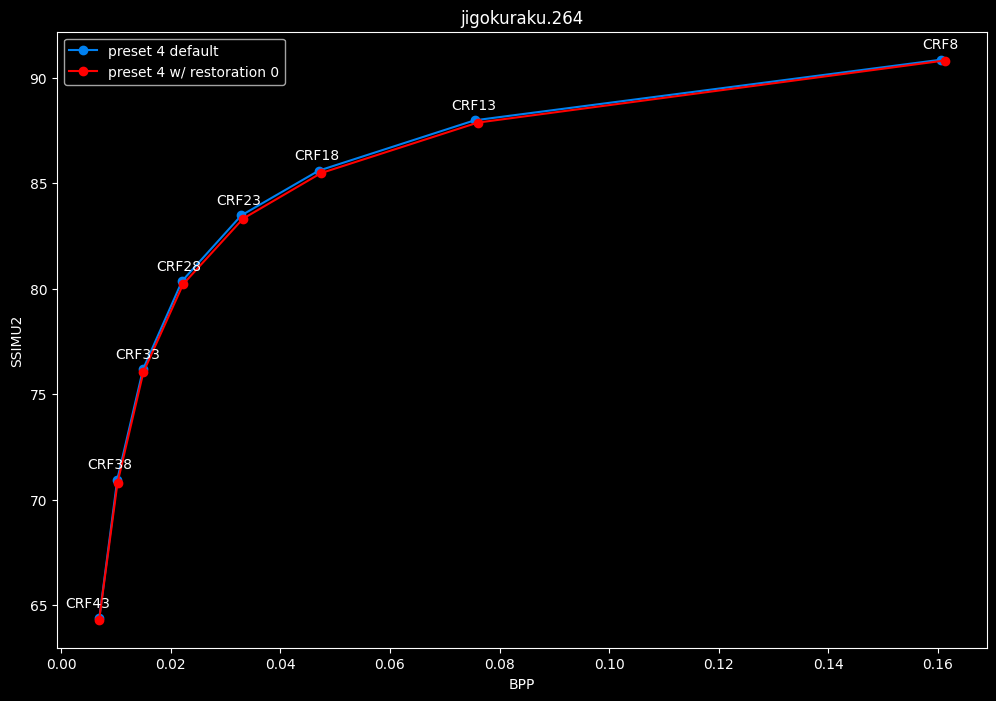
- Speed graphs:
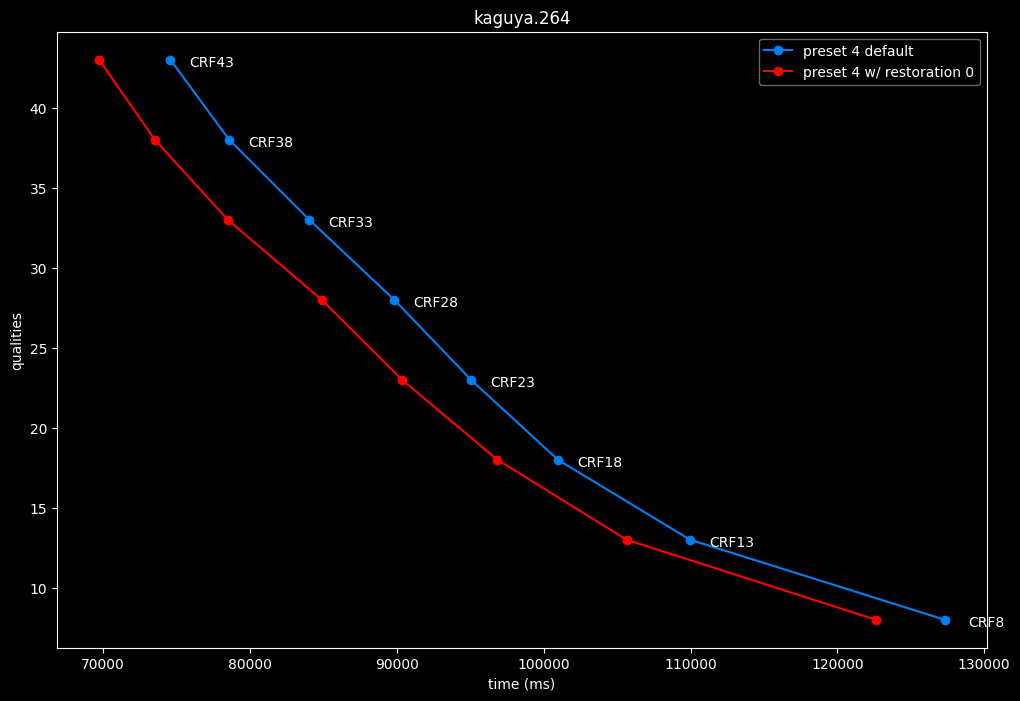
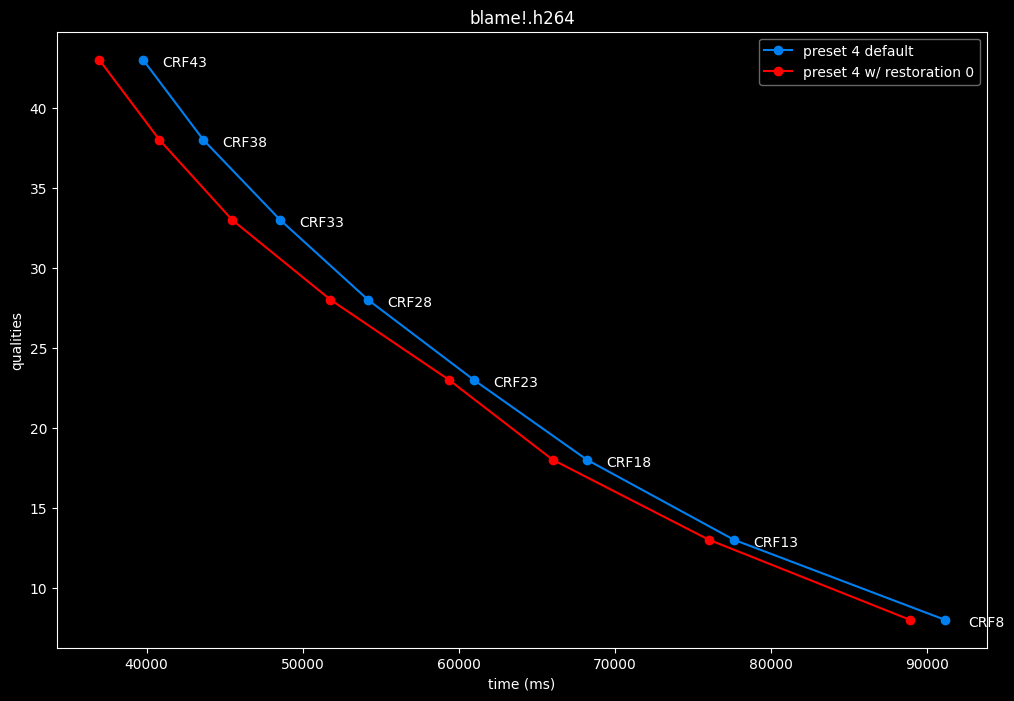
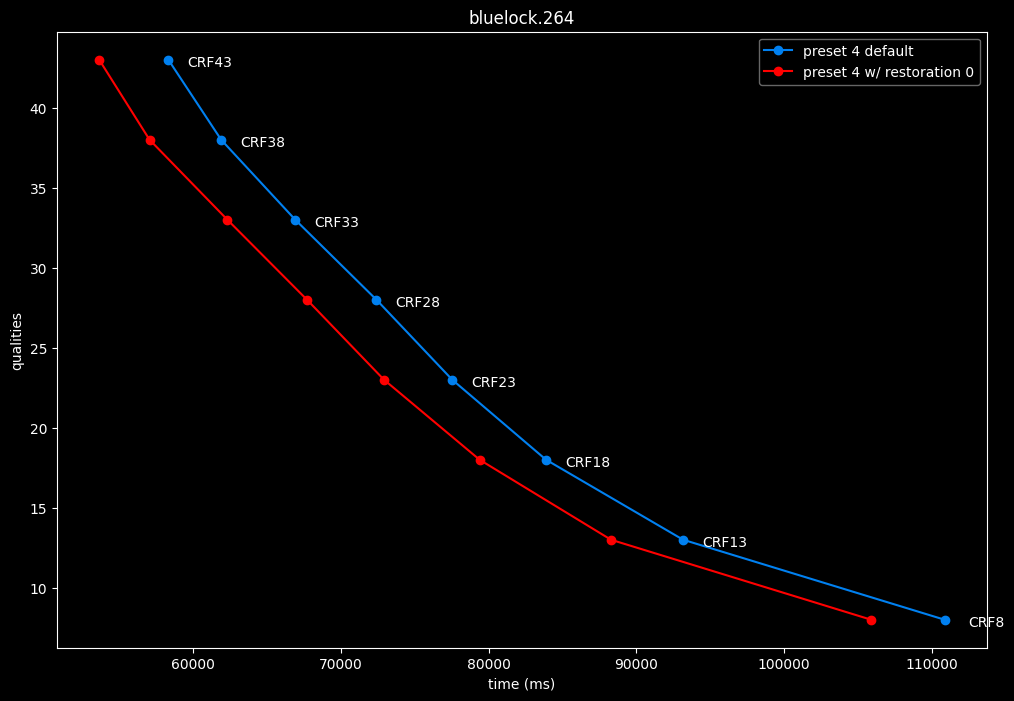
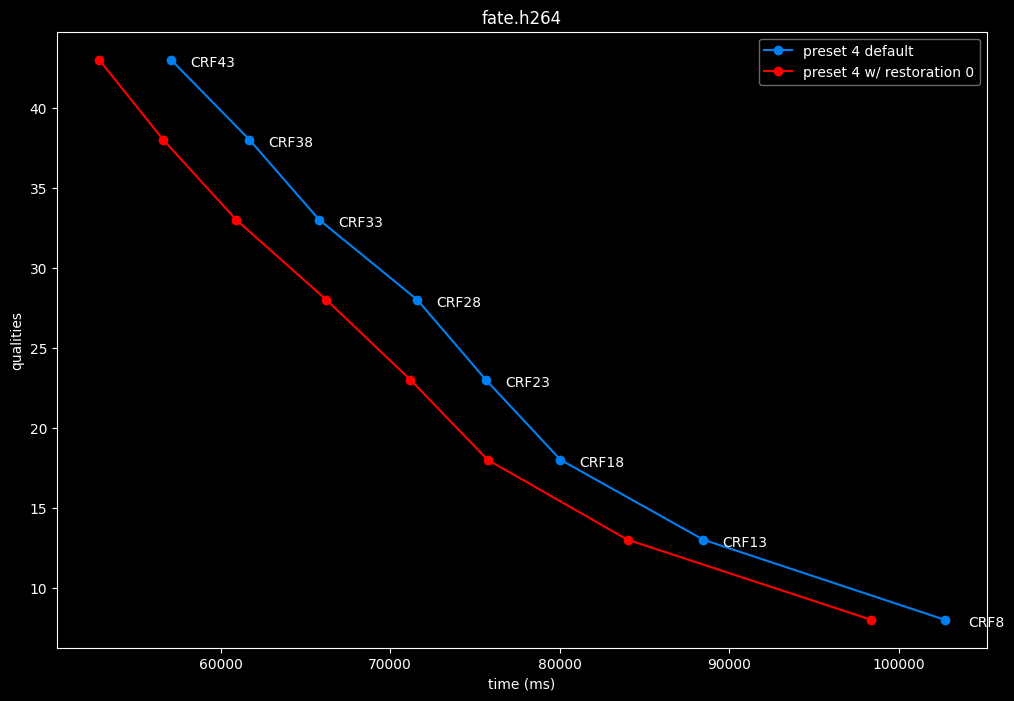
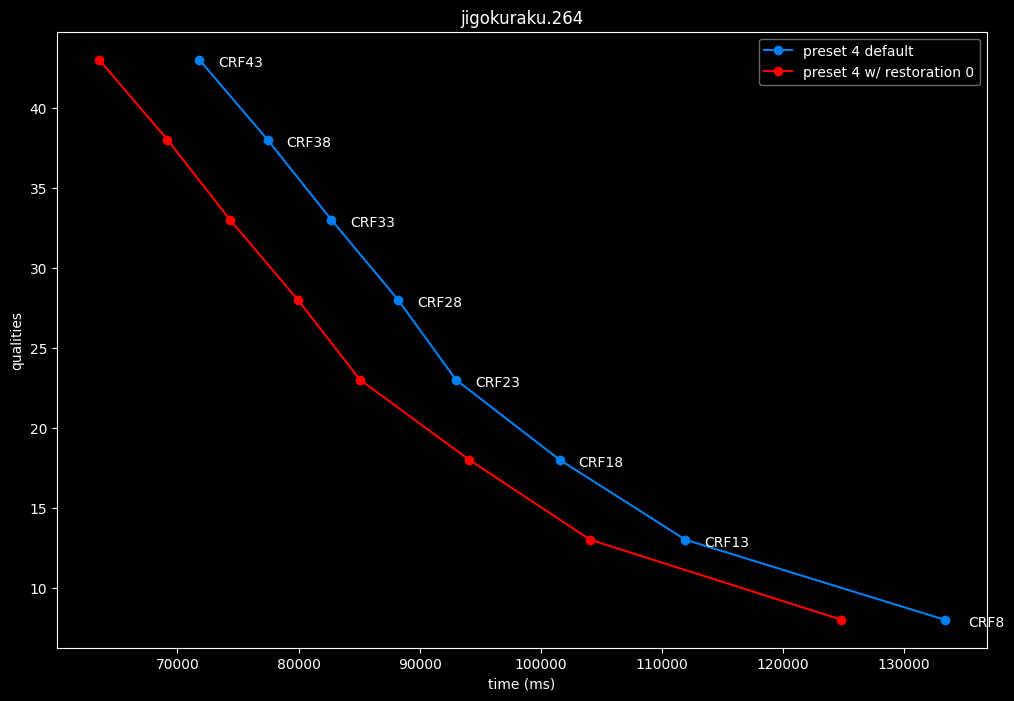
Even though the efficiencies are very similar, nothing is bit-perfect here. So according to SSIMU2, the loop restoration filter isn't necessarily useful. However, just like CDEF, it's a pretty demanding tool, so disabling it yields some performance improvements. Let's take these with a grain of salt until the image comparisons.
--scm 0 vs default --scm 2 (content adaptive)
In all the clips, the results are bit-perfect and there is no notable performance difference.
--scm 1 vs default --scm 2 (content adaptive)
- Efficiency graphs:
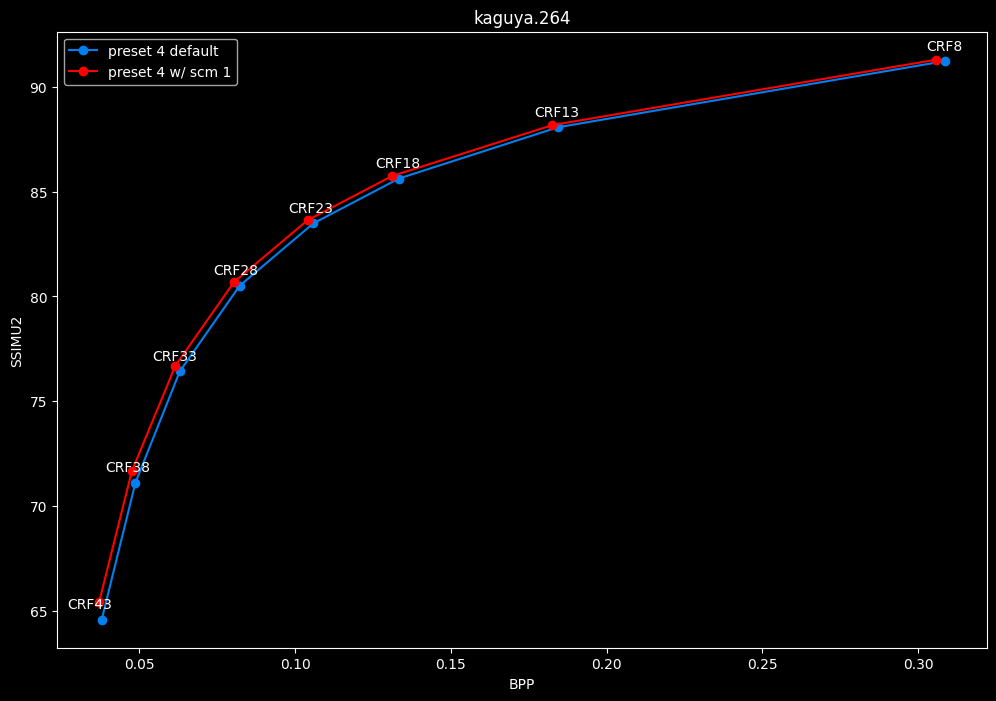
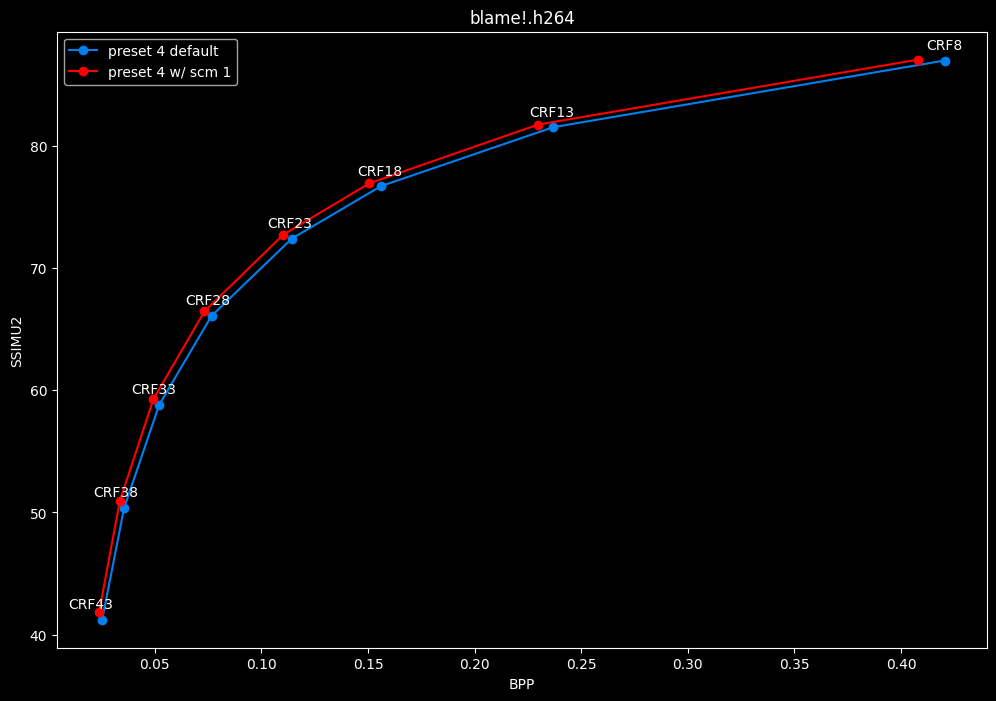
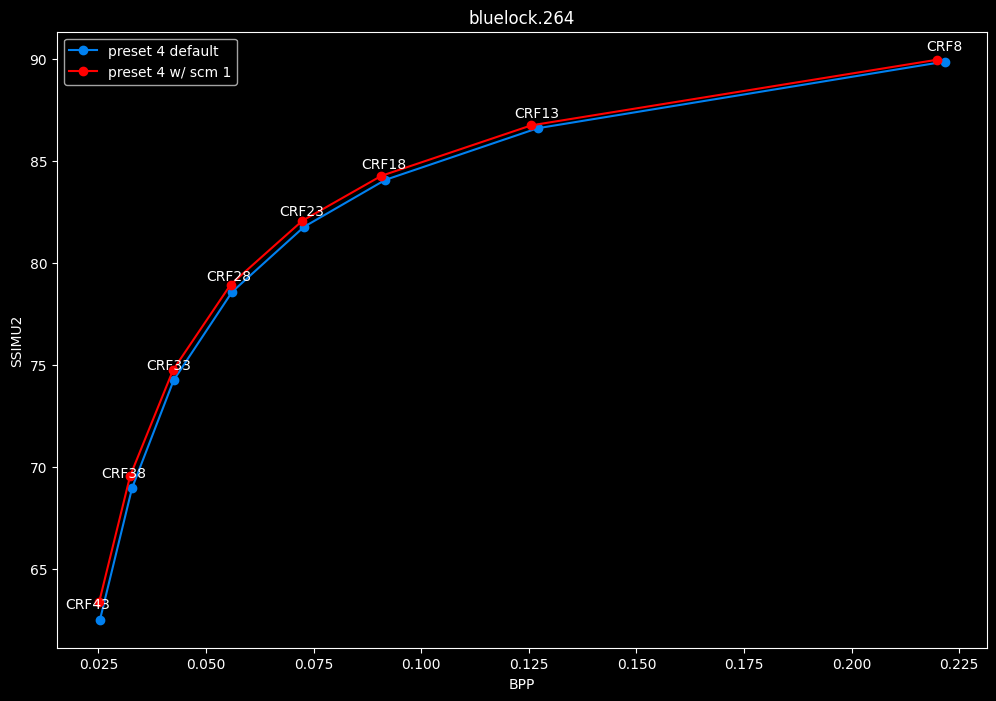
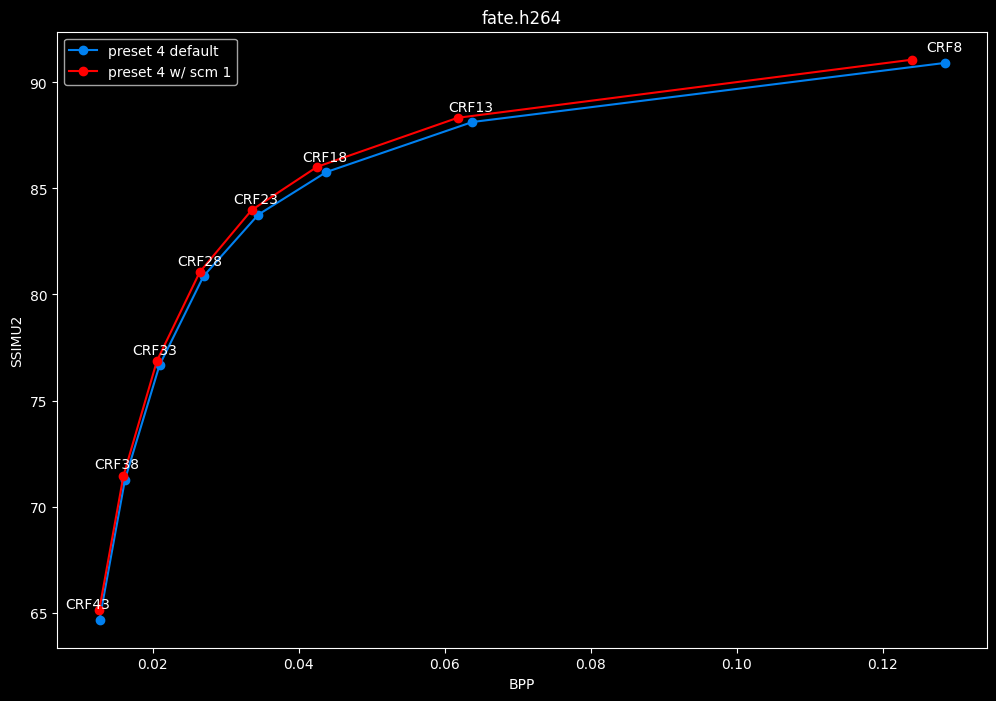
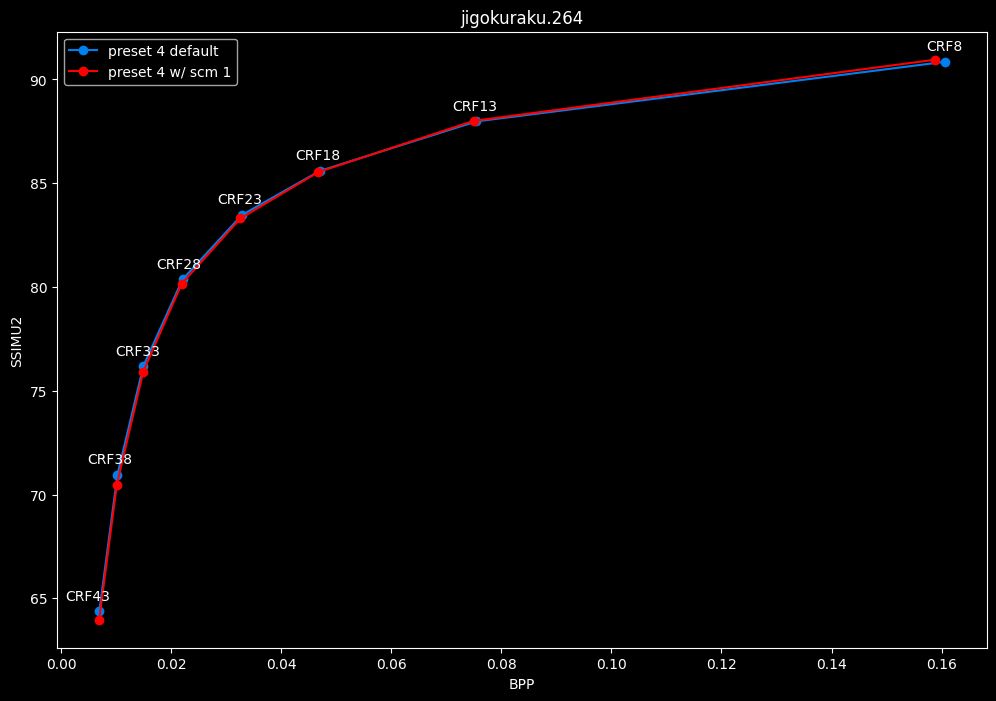
- Speed graphs:
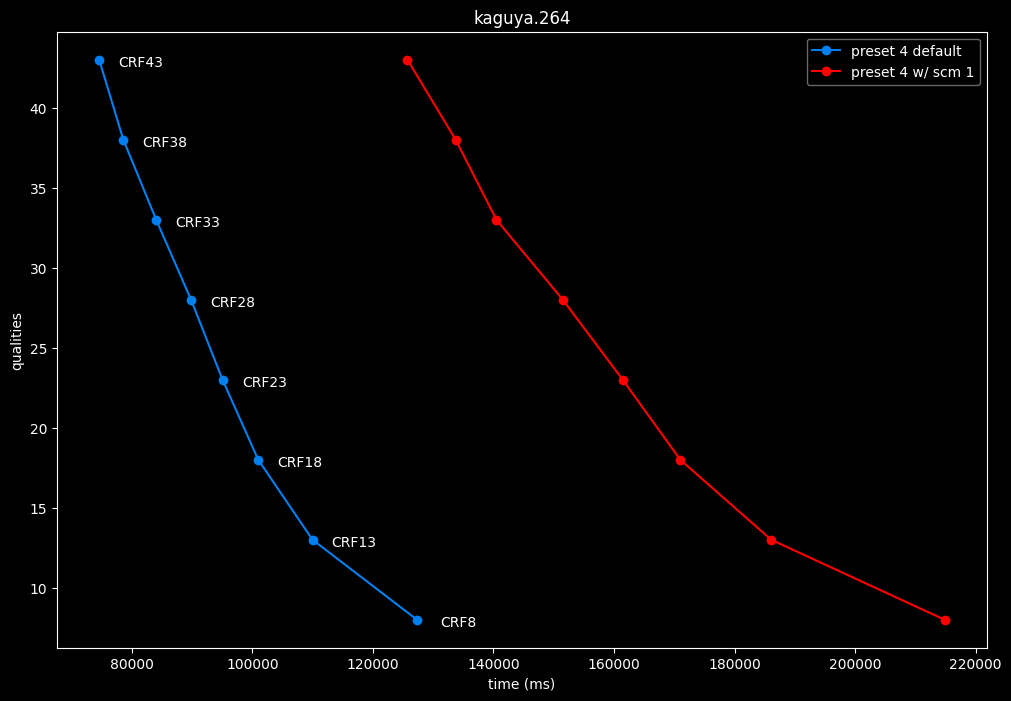
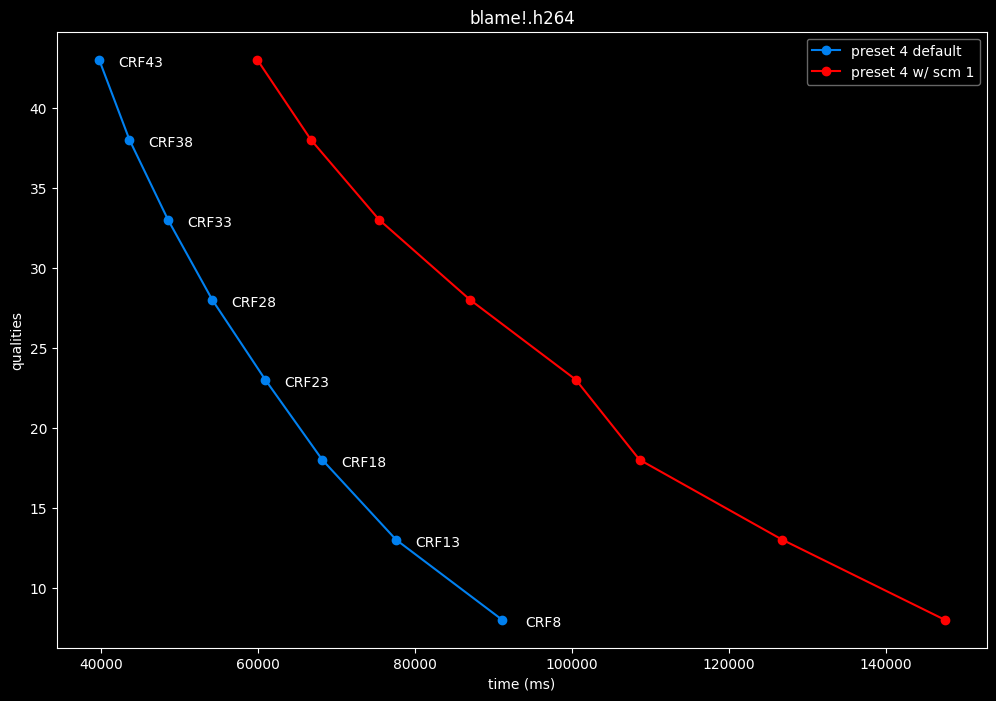
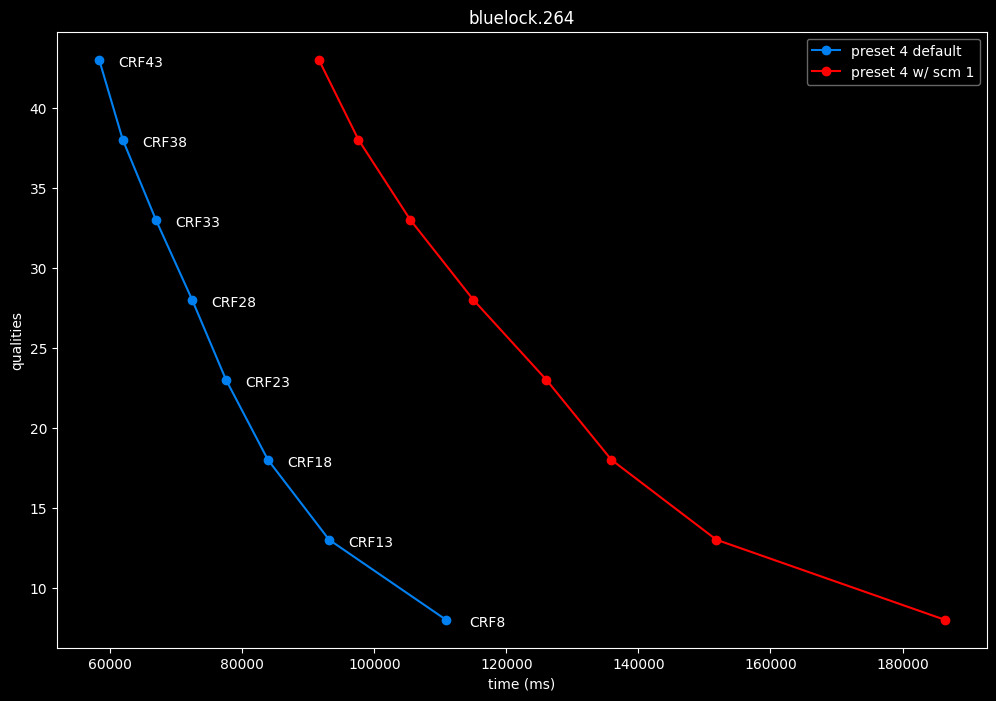
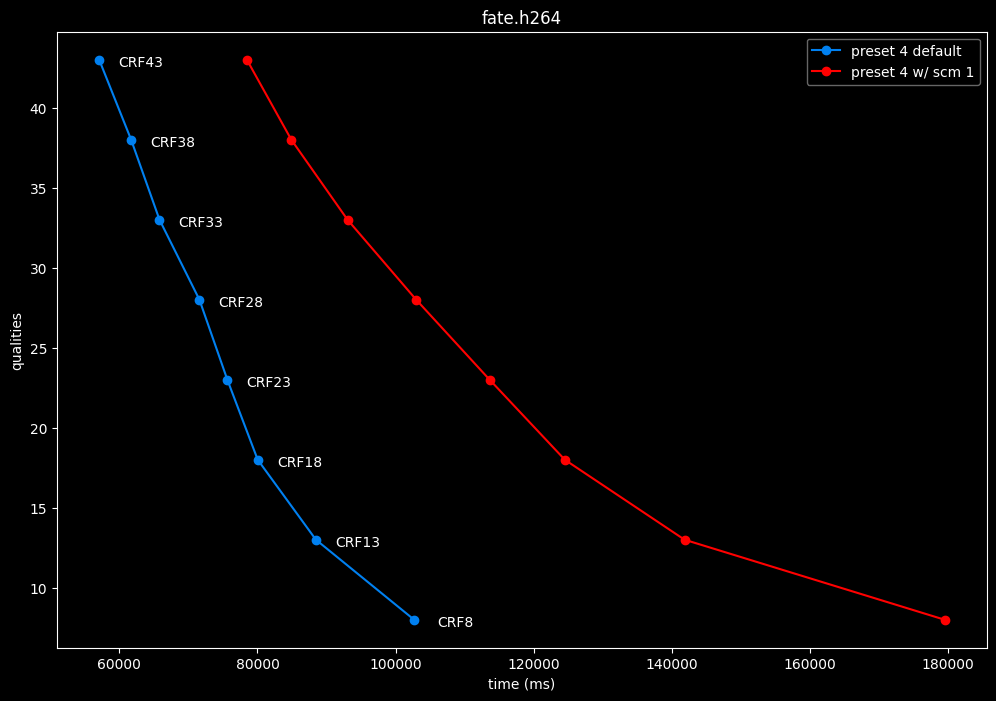
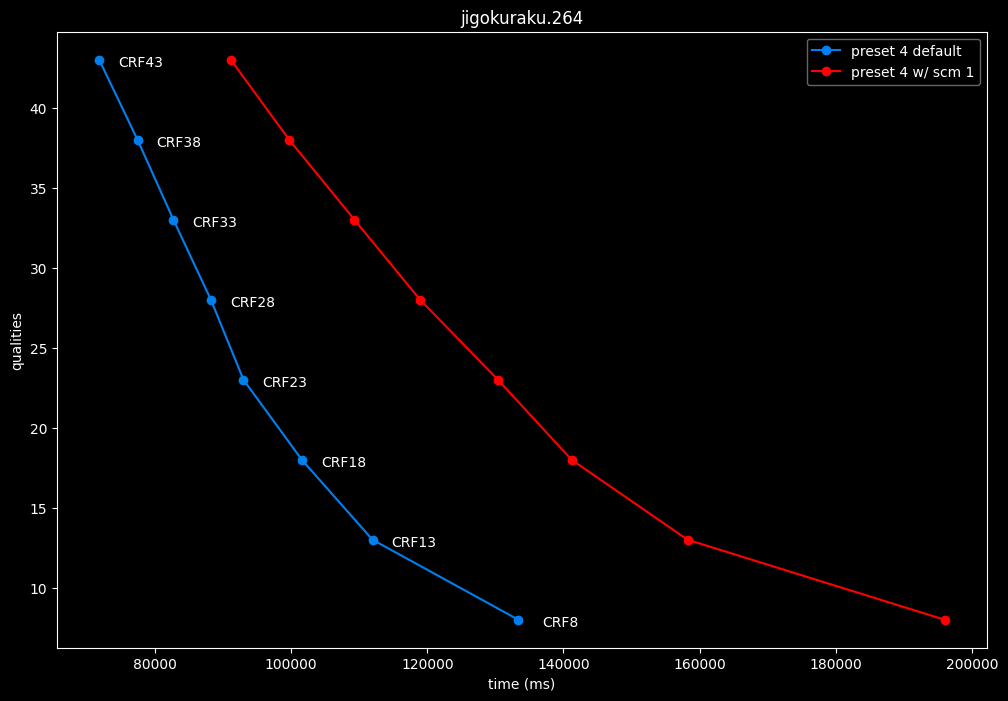
Interestingly enough, screen content tools seem to improve efficiency according to SSIMU2, at the cost of a huge performance regression. After the image comparisons are published, I will conduct additional testing on this.
--enable-tf 0 vs default --enable-tf 1
- Efficiency graphs:
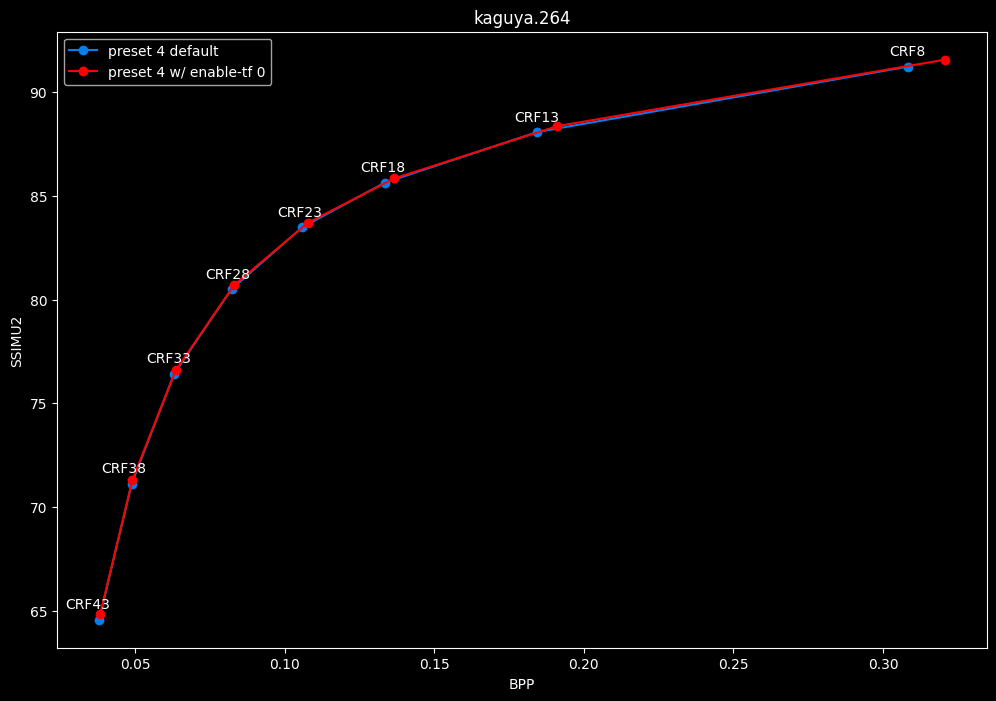
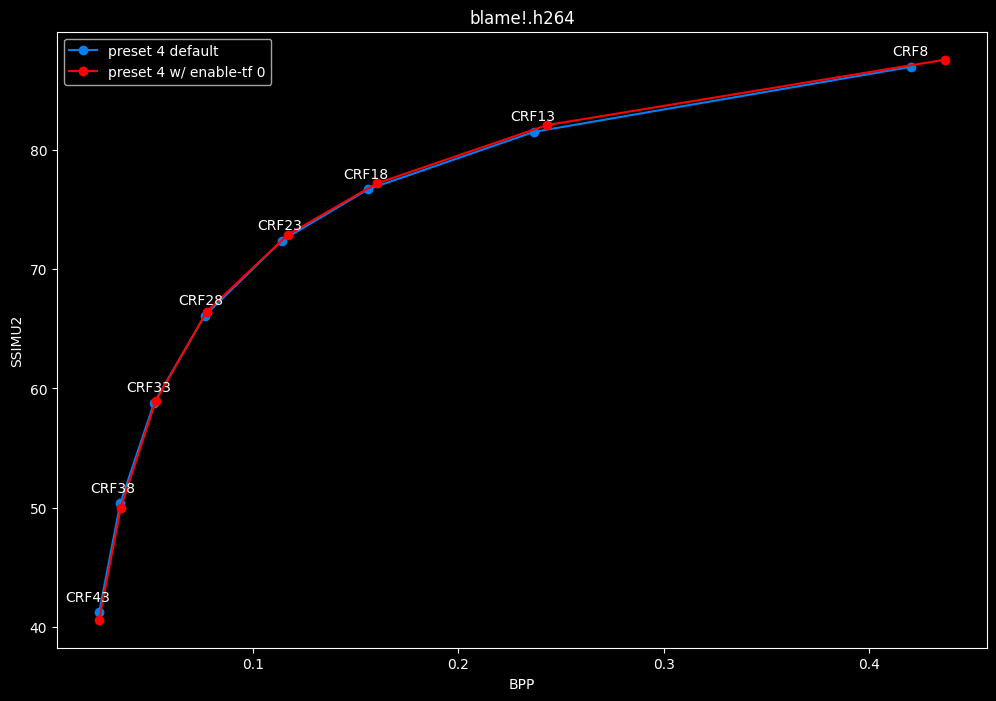
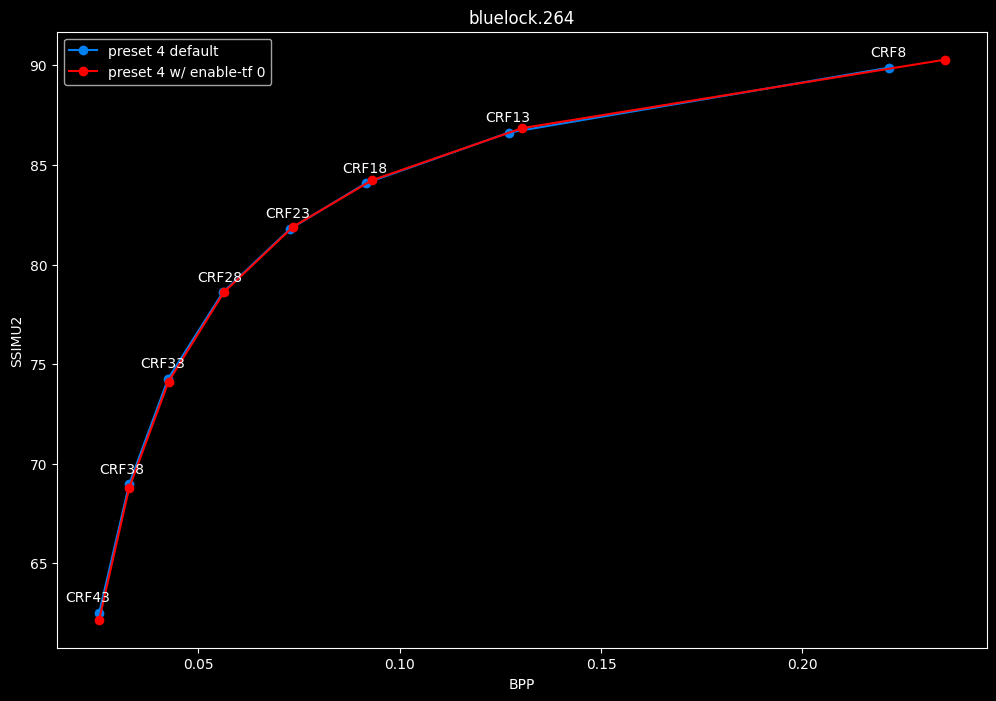
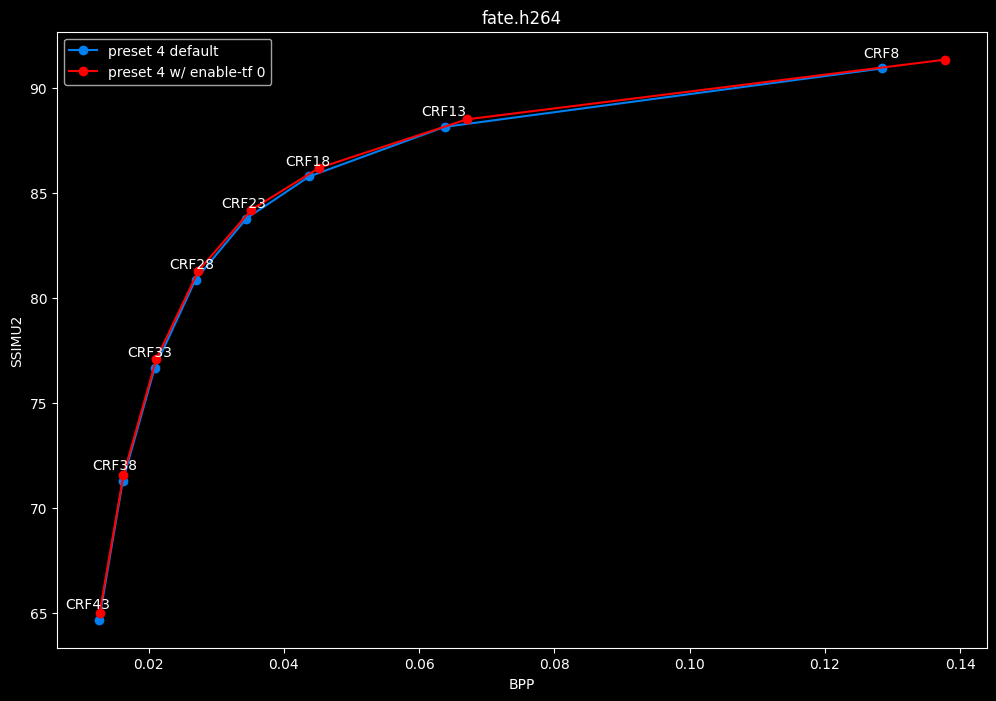
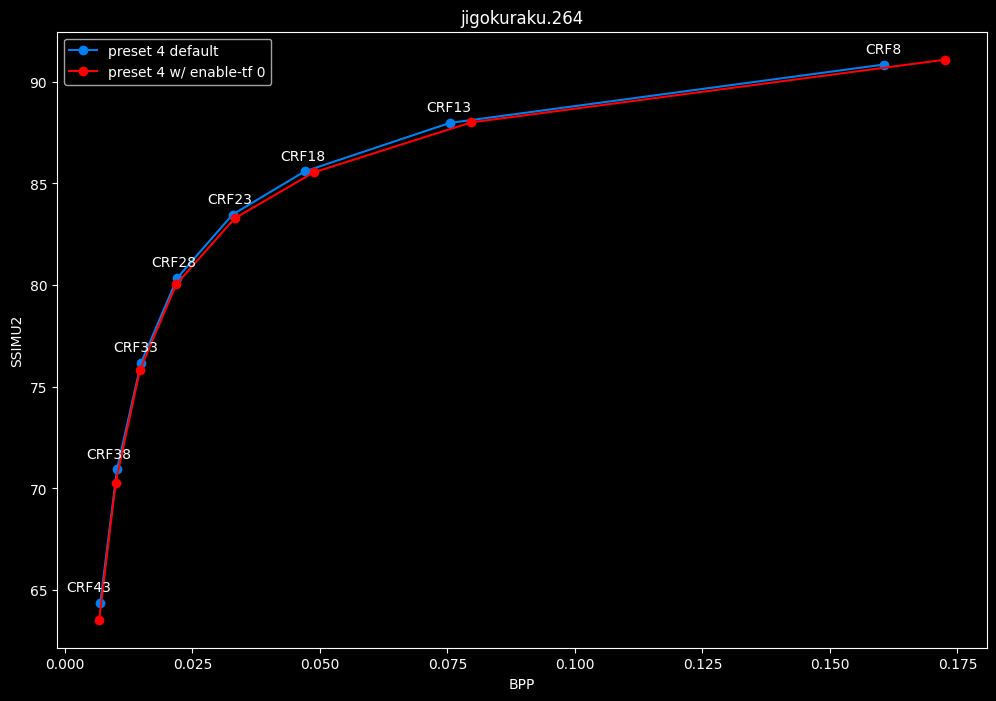
- Speed graphs:
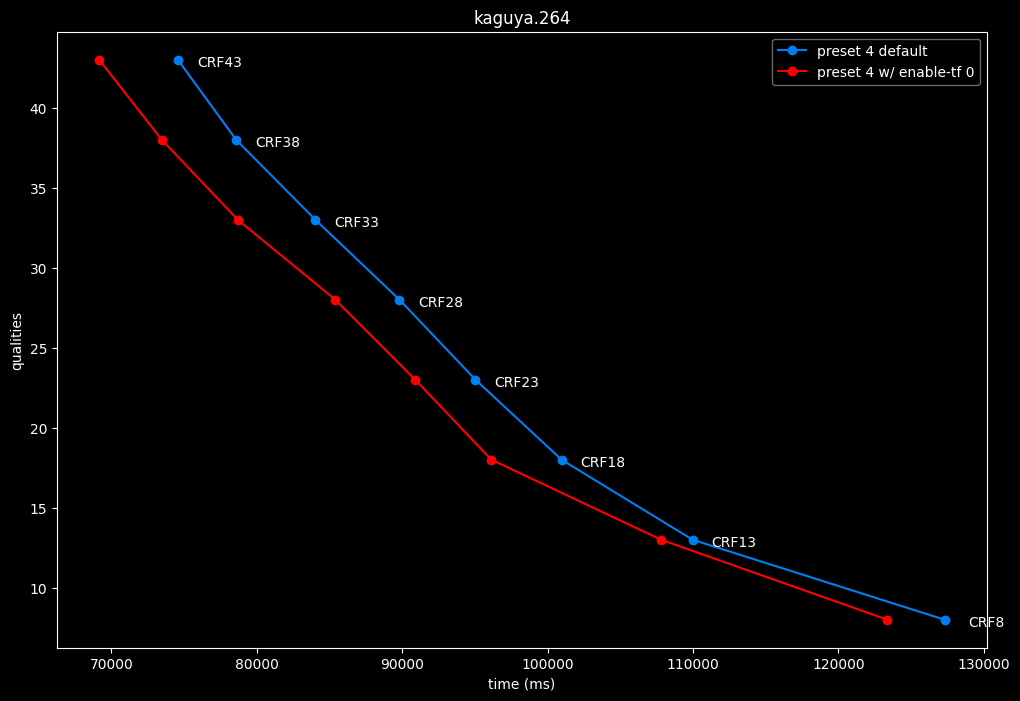
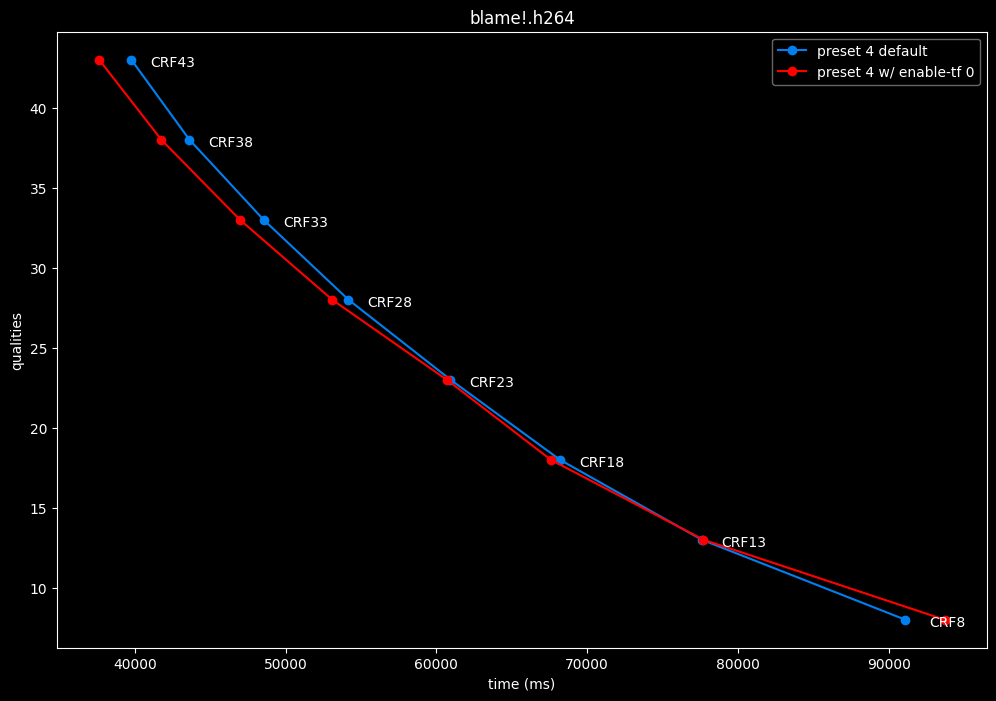
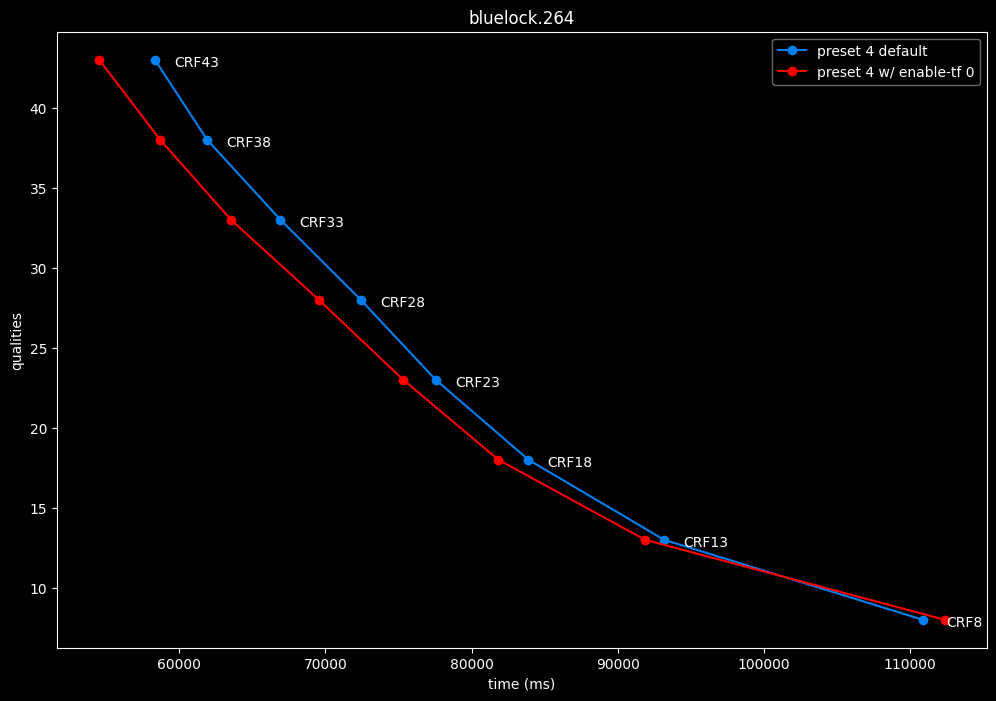
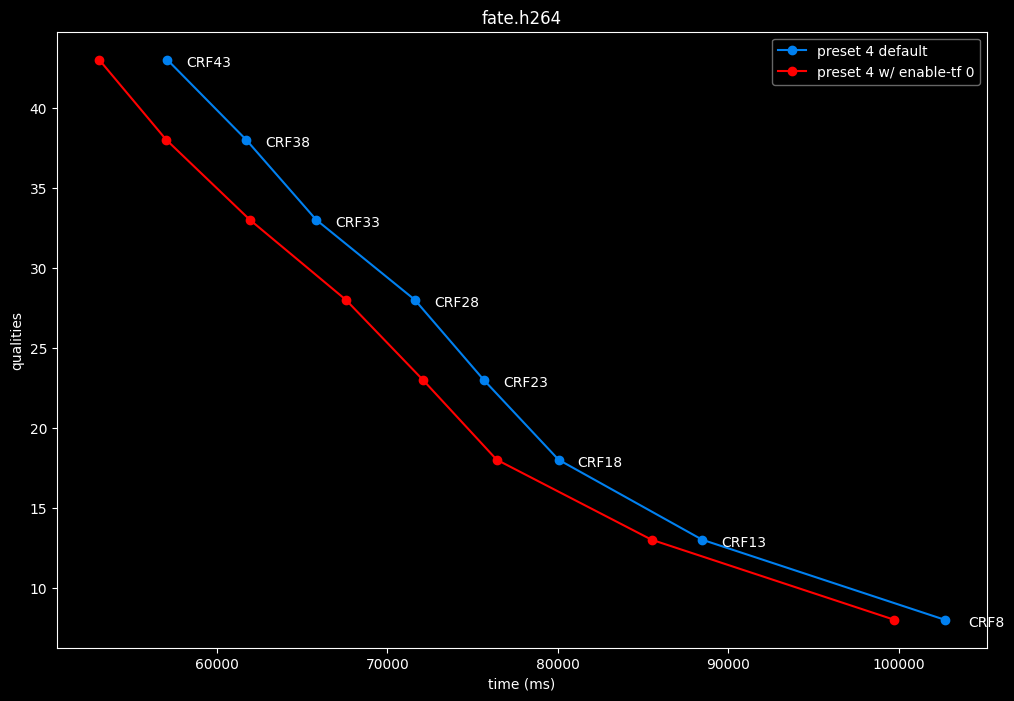
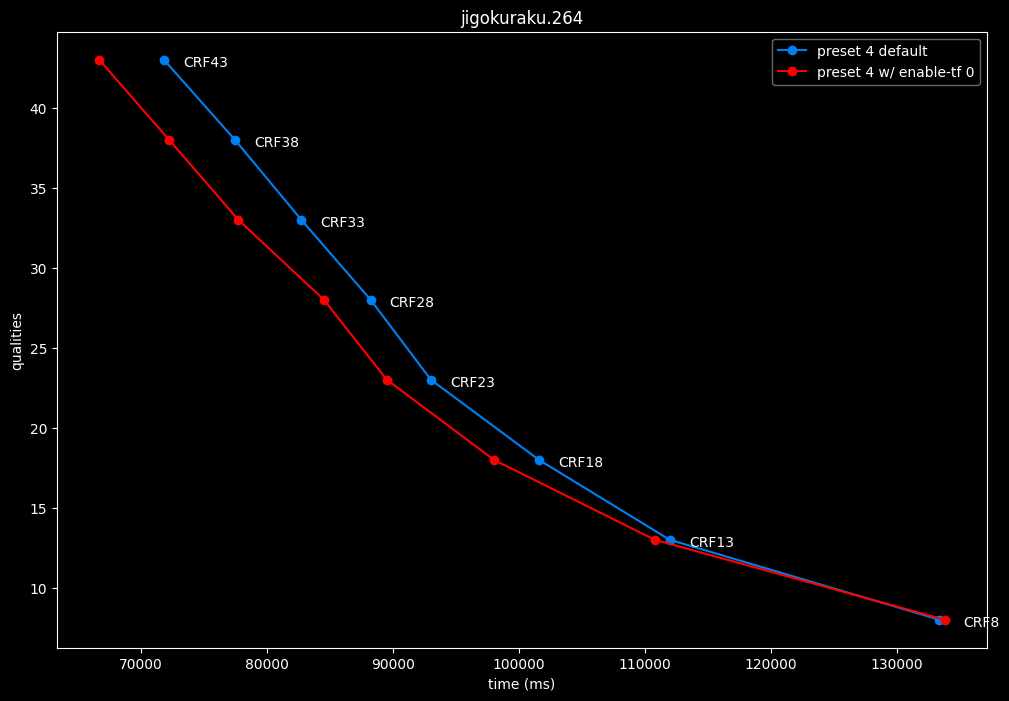
Disabled temporal filtering can sometimes improve efficiency slightly at "high quality", however it is very much clip dependent. It also improves performance slightly. The image comparisons will give another perspective to these results.
--enable-tpl-la 0 vs default --enable-tpl-la 1
In all the clips, the results are bit-perfect and there is no notable performance difference.
superres:
Kinda lazy to make, share and comment so much graphs for something that can be told in two lines...
All superres variants are freaking useless as they:
- do not improve efficiency
- decrease encoding speeds
- decrease decoding speeds when either bitrate or quality normalized.
Early TLDR on parameters results:
For a previous test with SVT-AV1 1.7.0 I did all parameters tests with --preset 6 --tune 2, now I did them with --preset 4 --tune 1. Mostly everything tested on v1.7.0 still stands today, but now we have more valuable data. Images comparisons are still needed to give more context to some results, so the conclusion presented here remains early as they are 100% based on SSIMU2 results and will require more analysis down the line.
Here is a quick run down of how each parameter affect encoding:
--tile-rows --tile-columnsshould never be used (except for decreasing decode complexity)--aq-mode 2is the most efficient / fastest--enable-cdef 0might improve performance at almost no efficiency loss (needs more thorough testing)--enable-dgand--enable-dlfbarely do anything--fast-decode 1decreases efficiency, improves encoding times, and the decoding gains still need to be determined.--irefresh-typeshould be kept default at high CRF values and for cleanish content at low CRF values, but can be set to 1 at low CRF values for extremely grainy content--lookaheadshould be kept default--enable-overlays 1does not improve efficiency, slight speed regression as well--enable-qm 1 --qm-min 0should be set for increased efficiency especially at low CRF values at no perf cost--enable-restorationbarely does anything but disabling yields better performance (needs visual confirmation)--scm 1screen content tools can improve efficiency with a big performance trade-off (needs more thorough testing)--enable-tf 0is a mixed bag efficiency wise but improves performancesuperres & resizeplease don't.
Conclusion
The extensive benchmarking reveals that obviously the slower presets provide better efficiency, with diminishing returns past preset 2. However, preset 4 provides a good balance of quality and speed for most use cases. Presets 6 and 8 are good options for the people that find 4 to be too slow for their liking.
The default settings tend to provide good results, but some tweaks like enabling quantization matrices can further optimize efficiency. Parameters like tile encoding and super resolution modes are not beneficial. Overall, SVT-AV1 continues to be a competitive option for encoding animation in AV1, with its speed being a notable strength.
Further testing with more content samples would help solidify these findings. The image comparisons will also provide additional subjective evaluation to complement the objective metrics used here, and we can discover the potential usefulness of Tune 0 that may betray what the metrics suggest. Overall, this comprehensive deep dive should give encoders a helpful starting point for choosing settings when encoding animation with the latest SVT-AV1 1.8.0. Thanks for reading!