VP8
VP8 is a video compression format developed by On2 Technologies released in 2008. It was later released as a royalty free codec in 2010 by Google. Its efficiency is competitive with AVC. VP8 was a significant player in the royalty-free codec space and was designed primarily around web video delivery. It is the precursor to VP9 & AV1, which both further improve video compression efficiency. VP8 has faced criticism for having a messy specification that many considered to be incomplete. It also serves as the basis for the WebP image format.
Design Assumptions
VP8's design is built upon several core assumptions tailored for web video.
- It is designed to operate efficiently within a quality range from "watchable video" (around 30dB PSNR) to "visually lossless" (around 45dB PSNR), anticipating limited network bandwidth.
- VP8 was designed to support efficient implementations across a wide breadth of client devices, from low-power mobile/embedded systems to powerful desktops.
- VP8 is optimized to handle common web video image formats; 4:2:0 color sampling, 8-bit per channel color depth, progressive scan (not interlaced), and image dimensions up to 16383x16383 pixels. Internally, lossy VP8 works exclusively in 8-bit YUV 4:2:0 (chroma is 1/4 the resolution of luma).
The overall architecture involves decomposing video frames into 16x16 luma (Y) and 8x8 chroma (U, V) macroblocks. These macroblocks can be further divided into 4x4 subblocks.
Technical Features
VP8 incorporates features that contribute to its compression efficiency and low computational complexity.
Frequency Transforms & Adaptive Quantization
VP8 utilizes transform coding to process the residual signal after intra or inter predictions.
The Discrete Cosine Transform is applied to all luma and chroma residual signals. The DCT is used due to its high VP8 defines a 4x4 inverse 2D DCT process as part of its bitstream format and decoding.
For macroblocks using 16x16 luma prediction modes, the DC coefficients from the 16 4x4 luma blocks within the macroblock are used to create another 4x4 block that undergoes a 4x4 Walsh-Hadamard Transform (WHT) to reduce redundancy among the DC coefficients in the 16x16 luma area.
VP8 defines 128 quantization levels within its operating quality range (~30dB to ~45dB). For each video frame, different quantization levels can be applied to six frequency components:
- 1st order luma DC
- 1st order luma AC
- 2nd order luma DC
- 2nd order luma AC
- chroma DC
- chroma AC
Additionally, VP8 includes a region-dependent quantization scheme, allowing macroblocks within a frame to be classified into four different segments, each with its own set of quantization parameters. All calculations in the transform, quantization, dequantization, and inverse transform pipeline can be performed using 16-bit operations.
Flexible Reference Frames
VP8 uses three types of reference frames for inter-prediction:
- Last Frame: The reconstructed frame immediately preceding the frame currently displayed.
- Golden Frame: A frame of decompressed data from an arbitrarily distant point in the past. Encoders can use the Golden Frame to improve coding efficiency by maintaining a copy of the background when foreground objects move, allowing occluded regions to be easily reconstructed. Golden frames also help with error resiliency in real-time video scenarios, like video conferencing.
- Alternate Reference Frame (Altref Frame): This frame is decoded, but is not necessarily displayed to the user. Its primary purpose is to serve as a reference to improve inter-prediction for other coded frames. Encoders can construct an Altref frame from multiple source frames or using macroblocks from various video frames, providing flexibility for improved compression. For example, it can be used for noise-reduced prediction by creating a "noise-free" reference frame through temporal or spatial filtering.
The intelligent use of Golden and Altref frames can compensate for the lack of B-frames (as seen in H.264) by allowing encoders to leverage information from "future" frames without requiring frame reordering in the decoder.
Intra Prediction
VP8 employs two main classes of prediction modes, intra and inter prediction. Intra prediction Uses data from within the current video frame. It applies to 4x4 luma, 16x16 luma, and 8x8 chroma blocks. Intra prediction modes for 8x8 chroma and 16x16 luma blocks include:
H_PRED(horizontal prediction): Fills columns with copies of the left column.V_PRED(vertical prediction): Fills rows with copies of the above row.DC_PRED(DC prediction): Fills the block with a single value, the average of pixels from the above row and left column. For chroma blocks, specific averaging rules apply for edge macroblocks (top row, left column, or top-left corner).TM_PRED(TrueMotion prediction): Unique to VP8, it uses the pixel above and to the left of the block (C), along with pixels from the above row (A) and left column (L). It propagates horizontal differences from A and vertical differences from L to form the prediction block, using the formulaXij = Li + Aj - C. TM_PRED is a frequently used mode, typically for 20% to 45% of all intra-coded blocks.
For 4x4 luma blocks, six additional directional intra modes are available. As is the case in other video codecs, keyframes rely solely on intra prediction modes.
Inter Prediction
Inter prediction uses data from previously encoded reference frames. A block is constructed using a motion vector to copy a block from one of the three reference frames (last, golden, altref). VP8 employs efficient motion vector coding by reusing vectors from neighboring macroblocks using modes like NEAREST and NEAR. The SPLITMV mode allows flexible coding of arbitrary block patterns within a macroblock by partitioning it into sub-macroblock patterns, each with its own motion vector. This allows a 16x16 macroblock to be partitioned into up to 16 4x4 blocks, each with a (potentially) new motion vector or inheriting from neighbors.
Motion compensation in VP8 uses quarter-pixel accurate motion vectors for luma pixels and up to one-eighth pixel accurate motion vectors for chroma pixels. It features a single-stage interpolation process and a set of high-performance six-tap interpolation filters for luma, and four-tap bicubic filters for chroma. This achieves optimal frequency response with high computational efficiency. Chroma motion vectors are calculated by averaging the motion vectors of the four corresponding luma subblocks. Motion vectors are limited to a range of -4096 to +4095 full pixels.
In-Loop Deblocking Filtering
VP8 includes a highly adaptive in-loop deblocking filter that reduces blocking artifacts introduced by the quantization of DCT coefficients.
- The filter type (normal or simple) and strength can be adjusted based on different prediction modes and reference frame types.
- It supports implicit segmentation, where different filter strengths can be applied to various parts of the image. For instance, stronger filtering might be applied to intra-coded blocks, while inter-coded blocks using the Golden Frame with a (0,0) motion vector might use a weaker filter.
- The choice of loop filter strengths is adjustable on a frame-by-frame basis. Loop filter strength can be adjusted per segment (within a frame) based on region-adaptive schemes.
A significant innovation is the ability to skip loop filtering entirely for edges between subblocks internal to a macroblock if the macroblock's coding mode is neither B_PRED nor SPLITMV and it has no DCT coefficients coded. This significantly reduces loop-filtering complexity. Loop filtering is applied to the entire frame after macroblock reconstruction and its results are used in the prediction of subsequent frames.
Entropy Coding
This section describes the VP8 bitstream's lossless compression step, where all of a lossy bitstream's data values are compressed losslessly. For background on this subject, it is recommended to read the Lossless Compression wiki entry (particularly the section on arithmetic coding).
Except for a few header bits, the majority of compressed VP8 data values are coded using a boolean arithmetic coder. This coder losslessly compresses sequences of boolean values where the probabilities of 0 or 1 can be accurately estimated. This approach provides significant data rate reduction compared to simpler methods like Huffman coding. Most symbol values are binarized into a series of boolean values using a tree scheme, where a binary tree is created for a set of symbols. Each non-leaf node in the tree has a probability assigned based on the likelihood of taking a branch. This consistent encoding/decoding style for various bitstream values (e.g., macroblock modes, motion vectors, quantized coefficients) improves module reusability in hardware and software implementations.
VP8 models entropy coding contexts using conditional probability distributions for macroblock modes, motion vectors, and quantized transform coefficients. These probability distributions remain stable within a frame and are updated on a per-frame basis. This design achieves lower decoder implementation complexity and allows better error recovery compared to H.264's context-based binary arithmetic coding.
VP8's bitstream separates compressed data into two categories:
- Macroblock coding modes & motion vectors
- Quantized transform coefficients
Critically, VP8 allows transform coefficients to be packed into multiple partitions (up to eight), enabling parallel processing in decoders on multi-core processors. For example, in FOUR_TOKEN_PARTITION mode, coefficients from macroblock rows 0, 4, 8, etc., are packed into the first partition, rows 1, 5, 9, etc., into the second, and so on. This design significantly improves decoder performance on multi-core systems with minimal impact on compression efficiency or single-core performance.
Overall Decoding Process
A VP8 decoder maintains four YUV frame buffers: the current frame being reconstructed, the immediately previous frame, the most recent golden frame, and the most recent altref frame. The decoding process generally involves:
- Decoding the frame header, which provides context for the per-macroblock data.
- Processing macroblock data in raster-scan order. This includes prediction data (modes/motion vectors) and DCT/WHT coefficients of the residual signal.
- Each macroblock is predicted using intra-prediction (from the current frame) or inter-prediction (from a reference frame).
- The residue DCT/WHT signal is decoded, dequantized, reverse-transformed, and added to the prediction buffer to produce the reconstructed macroblock.
- After all macroblocks are processed, the adaptive in-loop deblocking filter is applied to the entire frame to reduce artifacts.
- Finally, reference frame buffers are updated (e.g., current frame replacing golden or altref frame) and prepared for the next frame.
VP8 Today
Experimental results from initial publishing showed that VP8 encoded files were consistently faster to decode (averaging around 30% faster) than H.264 High Profile files at similar bitrates across various hardware platforms. In terms of encoding quality, VP8 achieved competitive results against the best H.264/AVC encoders at the time in its designed operating range for web video.
In practice, reactions to VP8's initial performance were mixed. Moscow State University's initial numbers for the libvpx encoder (shown below) were lackluster, and the performance claims that accompanied VP8's initial release were not appearing to hold up.
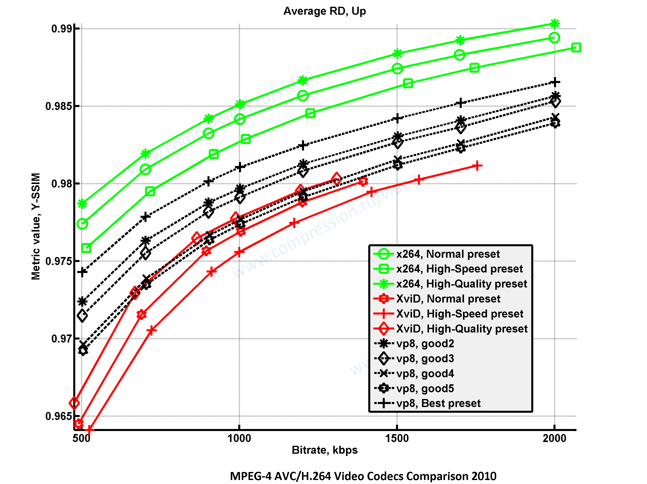 VP8 vs x264, Xvid on Pixar's "Up"
VP8 vs x264, Xvid on Pixar's "Up"
In her "Diary Of An x264 Developer" blog, Fiona Glaser (co-author of FFmpeg's native highly optimized VP8 decoder) discussed the positive and negative aspects of the VP8 video format. She acknowledged that VP8 doesn't have to be the best in compression to be useful while the current encoder issues are likely related to the encoder implementation's maturity, but she criticized Google for releasing an incomplete and inconsistent “bitstream guide” instead of a proper spec for the codec. The actual encoder/decoder implementation in libvpx differed from the bitstream specification, so the "bitstream guide" nomenclature took hold in what appeared to be a means of avoiding fixing the core issue. Fiona also praised VP8’s TM_PRED intra prediction mode and tree-based arithmetic coding, but criticized its slow deblocking filter and suboptimal inverse transform ordering.
Today, VP9 and to some extent AV1 have largely replaced VP8 as the web's most prominent royalty-free video compression standards. While VP8 may have had a rocky development cycle as well as a lackluster reference encoder, the effects of VP8's introduction are still felt today. WebP is still a widely adopted web image standard, and VP8 set important precedents for web video that helped push the industry forward (e.g. no interlaced video support; Fiona described interlacing as "the scourge of H.264"). Finally, royalty-free video standardization efforts have seen progressively fewer issues with implementation-to-spec parity, helping guide hardware vendors toward successful implementations more effectively.
Sources:
- Fiona Glaser's blog
- VP8 Data Format and Decoding Guide – RFC6386
- Technical overview of VP8, an open source video codec for the web